

{kind=link}
Introduction
Be it twitter or Linkedin, I encounter quite a few posts about Massive Language Fashions(LLMs) every day. Maybe I puzzled why there’s such an unimaginable quantity of analysis and growth devoted to those intriguing fashions. From ChatGPT to BARD, Falcon, and numerous others, their names swirl round, leaving me desperate to uncover their true nature. How are these fashions created? How you can construct massive language fashions? How do they possess the flexibility to reply just about any query you throw at them? These burning questions have lingered in my thoughts, fueling my curiosity. This insatiable curiosity has ignited a hearth inside me, propelling me to dive headfirst into the realm of LLMs.
Be a part of me on an exhilarating journey as we are going to talk about the present cutting-edge in LLMs. Collectively, we’ll unravel the secrets and techniques behind their growth, comprehend their extraordinary capabilities, and make clear how they’ve revolutionized the world of language processing.
Studying Targets
- Find out about LLMs and their present cutting-edge.
- Perceive completely different LLMs accessible and approaches to coaching these LLMs from scratch
- Discover greatest practices to coach and consider LLMs
Buckle up and let’s begin our journey to mastering LLMs.
A Temporary Historical past of Massive Language Fashions
The historical past of Massive Language Fashions goes again to the Sixties. In 1967, a professor at MIT constructed the primary ever NLP program Eliza to grasp pure language. It makes use of sample matching and substitution methods to grasp and work together with people. Later, in 1970, one other NLP program was constructed by the MIT staff to grasp and work together with people often called SHRDLU.
In 1988, RNN structure was launched to seize the sequence data current within the textual content knowledge. Throughout the 2000s, there was intensive analysis in NLP utilizing RNNs. Language fashions utilizing RNNs had been state-of-the-art architectures so far. However RNNs might work effectively with solely shorter sentences however not with lengthy sentences. Therefore, LSTM was launched in 2013. Throughout this era, large developments emerged in LSTM-based functions. Concurrently, analysis started in consideration mechanisms as effectively.
There have been 2 main issues with LSTM. LSTM solved the issue of lengthy sentences to some extent however it might not likely excel whereas working with actually lengthy sentences. Coaching LSTM fashions can’t be parallelized. Attributable to this, the coaching of those fashions took longer time.
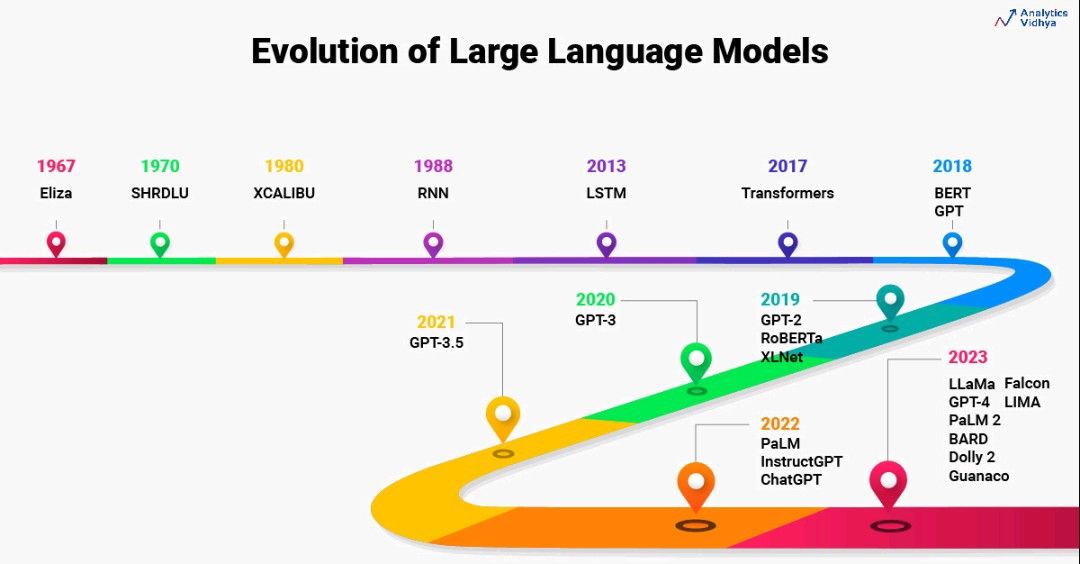
In 2017, there was a breakthrough within the analysis of NLP by means of the paper Consideration Is All You Want. This paper revolutionized the whole NLP panorama. The researchers launched the brand new structure often called Transformers to beat the challenges with LSTMs. Transformers basically had been the primary LLM developed containing an enormous no. of parameters. Transformers emerged as state-of-the-art fashions for LLMs. Even in the present day, the event of LLM stays influenced by transformers.

Over the subsequent 5 years, there was vital analysis centered on constructing higher LLMs in comparison with transformers. The scale of LLM exponentially elevated over time. The experiments proved that rising the scale of LLMs and datasets improved the information of LLMs. Therefore, LLMs like BERT, GPT, and their variants like GPT-2, GPT-3, GPT 3.5, and XLNet had been launched with a rise within the dimension of parameters and coaching datasets.
In 2022, there was one other breakthrough in NLP, ChatGPT. ChatGPT is a dialogue-optimized LLM that’s able to answering something you need it to. In a few months, Google launched BARD as a competitor to ChatGPT.
Within the final 1 12 months, there have been a whole lot of Massive Language Fashions developed. You may get the listing of open-source LLMs together with their efficiency rank right here. The state-of-the-art LLM so far is Falcon 40B Instruct.
What are Massive Language Fashions?
Merely put this way- Massive Language Fashions are deep studying fashions educated on large datasets to grasp human languages. Its core goal is to be taught and perceive human languages exactly. Massive Language Fashions allow the machines to interpret languages similar to the way in which we, as people, interpret them.
Massive Language Fashions be taught the patterns and relationships between the phrases within the language. For instance, it understands the syntactic and semantic construction of the language like grammar, order of the phrases, and which means of the phrases and phrases. It positive factors the aptitude to understand the entire language itself.
However how precisely is language fashions completely different from Massive Language Fashions?
Language fashions and Massive Language fashions be taught and perceive the human language however the main distinction is the event of those fashions.
Language fashions are usually statistical fashions developed utilizing HMMs or probabilistic-based fashions whereas Massive Language Fashions are deep studying fashions with billions of parameters educated on a really large dataset.
However why do we’d like Massive Language Fashions within the first place?
Why Massive Language Fashions?
The reply to this query is straightforward. LLMs are task-agnostic fashions. Actually, these fashions have the aptitude to resolve any activity. For instance, ChatGPT is a classical instance of this. Each time you ask ChatGPT one thing, it amazes you.
And another astonishing function about these LLMs is that you just don’t have to really fine-tune the fashions like some other pretrained mannequin to your activity. All you want do is to immediate the mannequin. It does the job for you. Therefore, LLMs present immediate options to any drawback that you’re engaged on. Furthermore, it’s only one mannequin for all of your issues and duties. Therefore, these fashions are often called the Basis fashions in NLP.
Totally different Sorts of LLMs
LLMs may be broadly labeled into 2 sorts relying on their activity:
- Persevering with the textual content
- Dialogue optimized
Persevering with the Textual content
These LLMs are educated to foretell the subsequent sequence of phrases within the enter textual content. Their activity at hand is to proceed the textual content.
For instance, given the textual content “How are you”, these LLMs may full the sentence with “How are you doing? or “How are you? I’m high quality.
The listing of LLMs falling underneath this class are Transformers, BERT, XLNet, GPT, and its variants like GPT-2, GPT-3, GPT-4, and so on.
Now, the issue with these LLMs is that its excellent at finishing the textual content fairly than answering. Generally, we anticipate the reply fairly than completion.
As mentioned above, given How are you? as an enter, LLM tries to finish the textual content with doing? or I’m high quality. The response may be both of them: completion or a solution. That is precisely why the dialogue-optimized LLMs had been launched.
2. Dialogue Optimized
These LLMs reply again with a solution fairly than finishing it. Given the enter “How are you?”, these LLMs may reply again with a solution “I’m doing high quality.” fairly than finishing the sentence.
The listing of dialogue-optimized LLMs is InstructGPT, ChatGPT, BARD, Falcon-40B-instruct, and so on.
Now, we are going to see the challenges concerned in coaching LLMs from scratch.
What are the Challenges of Coaching LLM?
Coaching LLMs from scratch are actually difficult due to 2 fundamental elements: Infrastructure and Price.
Infrastructure
LLMs are educated on a large textual content corpus ranging at the very least within the dimension of 1000 GBs. The fashions used to coach on these datasets are very massive containing billions of parameters. So as to practice such massive fashions on the huge textual content corpus, we have to arrange an infrastructure/{hardware} supporting a number of GPUs. Are you able to guess the time taken to coach GPT-3 – 175 billion parameter mannequin on a single GPU?
It might take 355 years to coach GPT-3 on a single NVIDIA Tesla V100 GPU.
This clearly reveals that coaching LLM on a single GPU isn’t attainable in any respect. It requires distributed and parallel computing with 1000’s of GPUs.
Simply to present you an thought, right here is the {hardware} used for coaching well-liked LLMs-
- Falcon-40B was educated on 384 A100 40GB GPUs, utilizing a 3D parallelism technique (TP=8, PP=4, DP=12) mixed with ZeRO.
- Researchers calculated that OpenAI might have educated GPT-3 in as little as 34 days on 1,024x A100 GPUs
- PaLM (540B, Google): 6144 TPU v4 chips utilized in whole.
Price
It’s very apparent from the above that GPU infrastructure is far wanted for coaching LLMs from scratch. Organising this dimension of infrastructure is very costly. Firms and analysis establishments make investments tens of millions of {dollars} to set it up and practice LLMs from scratch.
It’s estimated that GPT-3 value round $4.6 million {dollars} to coach from scratch
On common, the 7B parameter mannequin would value roughly $25000 to coach it from scratch.
Now, we are going to see how one can practice LLMs from scratch
How Do you Practice LLMs from Scratch?
The coaching means of LLMs is completely different for the sort of LLM you wish to construct whether or not it’s persevering with the textual content or dialogue optimized. The efficiency of LLMs primarily relies upon upon 2 elements: Dataset and Mannequin Structure. These 2 are the important thing driving elements behind the efficiency of LLMs.
Let’s talk about the now completely different steps concerned in coaching the LLMs.
1. Persevering with the Textual content
The coaching means of the LLMs that proceed the textual content is called pretraining LLMs. These LLMs are educated in self-supervised studying to foretell the subsequent phrase within the textual content. We are going to precisely see the completely different steps concerned in coaching LLMs from scratch.
a. Dataset Assortment
Step one in coaching LLMs is gathering a large corpus of textual content knowledge. The dataset performs probably the most vital position within the efficiency of LLMs. Just lately, OpenChat is the most recent dialog-optimized massive language mannequin impressed by LLaMA-13B. It achieves 105.7% of the ChatGPT rating on the Vicuna GPT-4 analysis. Have you learnt the explanation behind its success? It’s high-quality knowledge. It has been finetuned on solely ~6K knowledge.
The coaching knowledge is created by scraping the web, web sites, social media platforms, educational sources, and so on. Make it possible for coaching knowledge is as various as attainable.
Current work has demonstrated that elevated coaching dataset range improves common cross-domain information and downstream generalization functionality for large-scale language fashions
What does it say? Let me clarify.
You may need come throughout the headlines that “ChatGPT failed at JEE” or “ChatGPT fails to clear the UPSC” and so forth. What may be the attainable causes? The reason is it lacked the required stage of intelligence. That is closely depending on the dataset used for coaching. Therefore, the demand for various dataset continues to rise as high-quality cross-domain dataset has a direct impression on the mannequin generalization throughout completely different duties.
Unlock the potential of LLMs with the prime quality knowledge!
Beforehand, Widespread Crawl was the go-to dataset for coaching LLMs. The Widespread Crawl comprises the uncooked net web page knowledge, extracted metadata, and textual content extractions since 2008. The scale of the dataset is in petabytes (1 petabyte=1e6 GB). It’s confirmed that the Massive Language Fashions educated on this dataset confirmed efficient outcomes however didn’t generalize effectively throughout different duties. Therefore, a brand new dataset referred to as Pile was created from 22 various high-quality datasets. It’s a mix of present knowledge sources and new datasets within the vary of 825 GB. In current instances, the refined model of the frequent crawl was launched within the identify of RefinedWeb Dataset. The datasets used for GPT-3 and GPT-4 haven’t been open-sourced with a view to preserve a aggressive benefit over the others.
b. Dataset Preprocessing
The following step is to preprocess and clear the dataset. Because the dataset is crawled from a number of net pages and completely different sources, it’s very often that the dataset may comprise numerous nuances. We should get rid of these nuances and put together a high-quality dataset for the mannequin coaching.
The particular preprocessing steps really rely upon the dataset you’re working with. A few of the frequent preprocessing steps embody eradicating HTML Code, fixing spelling errors, eliminating poisonous/biased knowledge, changing emoji into their textual content equal, and knowledge deduplication. Information deduplication is likely one of the most important preprocessing steps whereas coaching LLMs. Information deduplication refers back to the means of eradicating duplicate content material from the coaching corpus.
It’s apparent that the coaching knowledge may comprise duplicate or practically the identical sentences because it’s collected from numerous knowledge sources. We’d like knowledge deduplication for two main causes: It helps the mannequin to not memorize the identical knowledge repeatedly. It helps us to guage LLMs higher as a result of the coaching and take a look at knowledge comprise non-duplicated data. If it comprises duplicated data, there’s a very likelihood that the knowledge it has seen within the coaching set is supplied as output in the course of the take a look at set. Because of this, the numbers reported is probably not true. You may learn extra about knowledge deduplication methods right here.
c. Dataset Preparation
The following step is to create the enter and output pairs for coaching the mannequin. Throughout the pretraining part, LLMs are educated to foretell the subsequent token within the textual content. Therefore, enter and output pairs are created accordingly.
For instance, let’s take a easy corpus-
- Instance 1: I’m a DHS Chatbot.
- Instance 2: DHS stands for DataHack Summit.
- Instance 3: I can offer you details about DHS
Within the case of instance 1, we are able to create the input-output pairs as per below-

Equally, within the case of instance 2, the next is a listing of enter and output pairs-

Every enter and output pair is handed on to the mannequin for coaching. Now, what subsequent? Let’s outline the mannequin structure.
d. Mannequin Structure
The following step is to outline the mannequin structure and practice the LLM.
As of in the present day, there are an enormous no. of LLMs being developed. You may get an outline of various LLMs right here. There’s a customary course of adopted by the researchers whereas constructing LLMs. A lot of the researchers begin with an present Massive Language Mannequin structure like GPT-3 together with the precise hyperparameters of the mannequin. After which tweak the mannequin structure and hyperparameters to provide you with a state-of-the-art mannequin structure.
For instance,
- Falcon is a state-of-the-art LLM. It ranks first on the open-source LLM leaderboard. Falcon is impressed by GPT-3 structure with a few tweaks.
e. Hyperparameter Search
Hyperparameter tuning is a really costly course of by way of time and price as effectively. Simply think about operating this experiment for the billion-parameter mannequin. It’s not possible proper? Therefore, the perfect methodology to go about is to make use of the hyperparameters of present analysis work, for instance, use the hyperparameters of GPT-3 whereas working with the corresponding structure after which discover the optimum hyperparameters on the small scale after which interpolate them for the ultimate mannequin.
The experiments can contain any or all the following: weight initialization, positional embeddings, optimizer, activation, studying fee, weight decay, loss operate, sequence size, variety of layers, variety of consideration heads, variety of parameters, dense vs. sparse layers, batch dimension, and drop out.
Let’s talk about one of the best practices for well-liked hyperparameters now-
- Batch dimension: Ideally select the big batch dimension that matches the GPU reminiscence.
- Studying Fee Scheduler: The higher solution to go about that is to lower the educational fee because the coaching progress. This can overcome the native minima and improves the mannequin stability. A few of the generally used Studying Fee Schedulers are Step Decay and Exponential Decay.
- Weight Initialization: The mannequin convergence extremely is dependent upon the weights initialized earlier than coaching. Initializing the correct weights results in quicker convergence. The generally used weight initialization for transformers is T-Fixup.
- Regularization: It’s confirmed that LLMs are susceptible to overfitting. Therefore, it’s vital to make use of the methods Utilizing batch normalization, dropout, l1/l2 regularization will assist the mannequin overcome overfitting.
2. Dialogue-optimized LLMs
Within the dialogue-optimized LLMs, step one is identical because the pretraining LLMs mentioned above. After pretraining, these LLMs are actually able to finishing the textual content. Now, to generate a solution for a particular query, the LLM is finetuned on a supervised dataset containing questions and solutions. By the top of this step, your mannequin is now able to producing a solution to a query.
ChatGPT is a dialogue-optimized LLM. The coaching methodology of ChatGPT is just like the steps mentioned above. Simply that it contains a further step often called RLHF aside from pretraining and supervised high quality tuning.

However not too long ago, there was a paper often called LIMA: Much less Is for Extra Alignment. It reveals that you just don’t want RLHF in any respect within the first place. All you want is pretraining on the large quantity of dataset and supervised fine-tuning on a top quality knowledge as much less as 1000 knowledge.
As of in the present day, OpenChat is the most recent dialog-optimized massive language mannequin impressed by LLaMA-13B. It achieves 105.7% of the ChatGPT rating on the Vicuna GPT-4 analysis. It’s been finetuned on solely 6k high-quality knowledge.
How Do you Consider LLMs?
The analysis of LLMs can’t be subjective. It needs to be a logical course of to guage the efficiency of LLMs.
Within the case of classification or regression issues, we have now the true labels and predicted labels after which examine each of them to grasp how effectively the mannequin is performing. We take a look at the confusion matrix for this proper? However what about massive language fashions? They only generate the textual content.
There are 2 methods to guage LLMs: Intrinsic and extrinsic strategies.
Intrinsic Strategies
Conventional Language fashions had been evaluated utilizing intrinsic strategies like perplexity, bits per character, and so on. These metrics monitor the efficiency on the language entrance i.e. how effectively the mannequin is ready to predict the subsequent phrase.
Extrinsic Strategies
With the developments in LLMs in the present day, extrinsic strategies are most well-liked to guage their efficiency. The advisable solution to consider LLMs is to take a look at how effectively they’re acting at completely different duties like problem-solving, reasoning, arithmetic, pc science, and aggressive exams like MIT, JEE, and so on.
EleutherAI launched a framework referred to as as Language Mannequin Analysis Harness to match and consider the efficiency of LLMs. Hugging face built-in the analysis framework to guage open supply LLMs developed by group.
The proposed framework evaluates LLMs throughout 4 completely different datasets. Closing rating is aggregation of rating from every datasets.
- AI2 Reasoning Problem: A group of science questions designed for elementary faculty college students.
- HellaSwag: A take a look at that challenges state-of-the-art fashions to make commonsense inferences, that are comparatively simple for people (about 95% accuracy).
- MMLU: A complete take a look at that evaluates the multitask accuracy of a textual content mannequin. It contains 57 completely different duties overlaying topics like fundamental math, U.S. historical past, pc science, legislation, and extra.
- TruthfulQA: A take a look at particularly created to evaluate a mannequin’s tendency to generate correct solutions and keep away from reproducing false data generally discovered on-line.
Additionally Learn: 10 Thrilling Tasks on Massive Language Fashions(LLM)
Finish Notes
Hope you are actually able to construct your personal massive language fashions!
Any ideas? Remark beneath.