

{kind=link}
“Generative AI is consuming the world.”
That’s how Andrew Feldman, CEO of Silicon Valley AI pc maker Cerebras, begins his introduction to his firm’s newest achievement: An AI supercomputer able to 2 billion billion operations per second (2 exaflops). The system, known as Condor Galaxy 1, is on observe to double in dimension inside 12 weeks. In early 2024, will probably be joined by two extra programs of double that dimension. The Silicon Valley firm plans to maintain including Condor Galaxy installations subsequent 12 months till it’s working a community of 9 supercomputers able to 36 exaflops in complete.
If large-language fashions and different generative AI are consuming the world, Cerebras’s plan is to assist them digest it. And the Sunnyvale, Calif., firm just isn’t alone. Different makers of AI-focused computer systems are constructing large programs round both their very own specialised processors or Nvidia’s newest GPU, the H100. Whereas it’s troublesome to choose the scale and capabilities of most of those programs, Feldman claims Condor Galaxy 1 is already among the many largest.
Condor Galaxy 1—assembled and began up in simply 10 days—is made up of 32 Cerebras CS-2 computer systems and is ready to broaden to 64. The subsequent two programs, to be in-built Austin, Texas, and Ashville, N.C., may even home 64 CS-2s every.
The guts of every CS-2 is the Waferscale Engine-2, an AI-specific processor with 2.6 trillion transistors and 850,000 AI cores created from a full wafer of silicon. The chip is so massive that the size of reminiscence, bandwidth, compute sources, and different stuff within the new supercomputers shortly will get a bit ridiculous, as the next graphic exhibits.
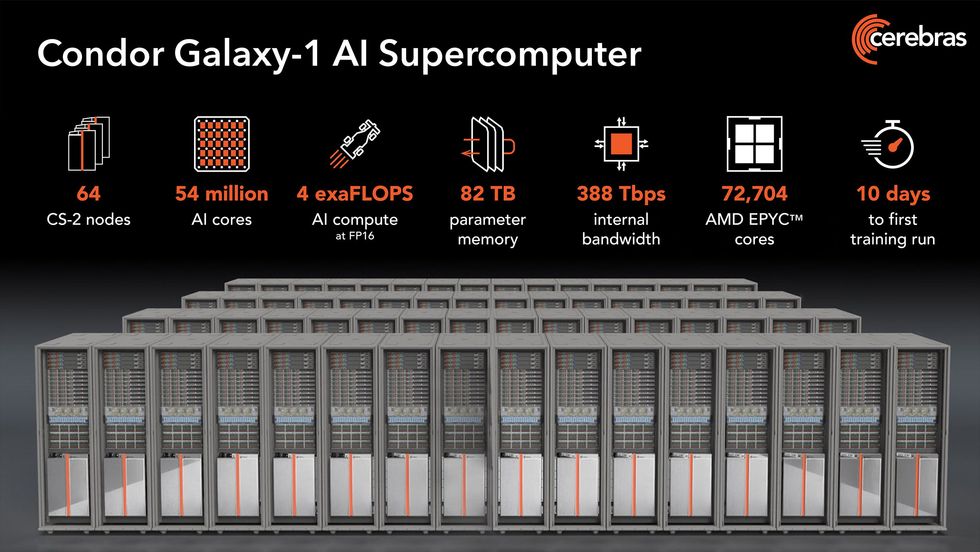 In case you didn’t discover these numbers overwhelming sufficient, right here’s one other: There are at the very least 166 trillion transistors within the Condor Galaxy 1.Cerebras
In case you didn’t discover these numbers overwhelming sufficient, right here’s one other: There are at the very least 166 trillion transistors within the Condor Galaxy 1.Cerebras
One in every of Cerebras’s greatest benefits in constructing large AI supercomputers is its potential to scale up sources merely, says Feldman. For instance, a 40 billion–parameter community might be educated in about the identical time as a 1 billion–parameter community for those who commit 40-fold extra {hardware} sources to it. Importantly, such a scale-up doesn’t require extra strains of code. Demonstrating linear scaling has traditionally been very troublesome due to the problem of dividing up large neural networks in order that they function effectively. “We scale linearly from 1 to 32 [CS-2s] with a keystroke,” he says.
The Condor Galaxy sequence is owned by Abu Dhabi–primarily based G42, a holding firm with 9 AI-based companies together with G42 Cloud, one of many largest cloud-computing suppliers within the Center East. Nonetheless, Cerebras will function the supercomputers and might lease sources G42 just isn’t utilizing for inner work.
Demand for coaching massive neural networks has shot up, in response to Feldman. The variety of corporations coaching neural-network fashions with 50 billion or extra parameters went from 2 in 2021 to greater than 100 this 12 months, he says.
Clearly, Cerebras isn’t the one one going after companies that want to coach actually massive neural networks. Massive gamers corresponding to Amazon, Google, Meta, and Microsoft have their very own choices. Pc clusters constructed round Nvidia GPUs dominate a lot of this enterprise, however a few of these corporations have developed their very own silicon for AI, corresponding to Google’s TPU sequence and Amazon’s Trainium. There are additionally startup opponents to Cerebras, making their very own AI accelerators and computer systems together with Habana (now a part of Intel), Graphcore, and Samba Nova.
Meta, for instance, constructed its AI Analysis SuperCluster utilizing greater than 6,000 Nvidia A100 GPUs. A deliberate second section would push the cluster to five exaflops. Google constructed a system containing 4,096 of its TPU v4 accelerators for a complete of 1.1 exaflops. That system ripped by way of the BERT pure language processor neural community, which is far smaller than at present’s LLMs, in simply over 10 seconds. Google additionally runs Compute Engine A3, which is constructed round Nvidia H100 GPUs and a customized infrastructure processing unit made with Intel. Cloud supplier CoreWeave, in partnership with Nvidia, examined a system of three,584 H100 GPUs that educated a benchmark representing the big language mannequin GPT-3 in simply over 10 minutes. In 2024, Graphcore plans to construct a 10-exaflop system known as the Good Pc made up of greater than 8,000 of its Bow processors.
You may entry Condor Galaxy right here.
From Your Website Articles
Associated Articles Across the Internet