
{kind=link}
This publish is co-written with Eliad Gat and Oded Lifshiz from Orca Safety.
With information turning into the driving power behind many industries at the moment, having a contemporary information structure is pivotal for organizations to achieve success. One key element that performs a central function in fashionable information architectures is the info lake, which permits organizations to retailer and analyze massive quantities of knowledge in a cheap method and run superior analytics and machine studying (ML) at scale.
Orca Safety is an industry-leading Cloud Safety Platform that identifies, prioritizes, and remediates safety dangers and compliance points throughout your AWS Cloud property. Orca connects to your surroundings in minutes with patented SideScanning know-how to offer full protection throughout vulnerabilities, malware, misconfigurations, lateral motion threat, weak and leaked passwords, overly permissive identities, and extra.
The Orca Platform is powered by a state-of-the-art anomaly detection system that makes use of cutting-edge ML algorithms and large information capabilities to detect potential safety threats and alert clients in actual time, guaranteeing most safety for his or her cloud surroundings. On the core of Orca’s anomaly detection system is its transactional information lake, which permits the corporate’s information scientists, analysts, information engineers, and ML specialists to extract priceless insights from huge quantities of knowledge and ship revolutionary cloud safety options to its clients.
On this publish, we describe Orca’s journey constructing a transactional information lake utilizing Amazon Easy Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics. We discover why Orca selected to construct a transactional information lake and study the important thing issues that guided the number of Apache Iceberg as the popular desk format.
As well as, we describe the Orca Platform structure and the applied sciences used. Lastly, we focus on the challenges encountered all through the undertaking, current the options used to handle them, and share priceless classes realized.
Why did Orca construct an information lake?
Previous to the creation of the info lake, Orca’s information was distributed amongst numerous information silos, every owned by a unique workforce with its personal information pipelines and know-how stack. This setup led to a number of points, together with scaling difficulties as the info dimension grew, sustaining information high quality, guaranteeing constant and dependable information entry, excessive prices related to storage and processing, and difficulties supporting streaming use instances. Furthermore, working superior analytics and ML on disparate information sources proved difficult. To beat these points, Orca determined to construct an information lake.
A knowledge lake is a centralized information repository that permits organizations to retailer and handle massive volumes of structured and unstructured information, eliminating information silos and facilitating superior analytics and ML on your complete information. By decoupling storage and compute, information lakes promote cost-effective storage and processing of massive information.
Why did Orca select Apache Iceberg?
Orca thought of a number of desk codecs which have developed in recent times to assist its transactional information lake. Amongst the choices, Apache Iceberg stood out as the best selection as a result of it met all of Orca’s necessities.
First, Orca sought a transactional desk format that ensures information consistency and fault tolerance. Apache Iceberg’s transactional and ACID ensures, which permit concurrent learn and write operations whereas guaranteeing information consistency and simplified fault dealing with, fulfill this requirement. Moreover, Apache Iceberg’s assist for time journey and rollback capabilities makes it extremely appropriate for addressing information high quality points by reverting to a earlier state in a constant method.
Second, a key requirement was to undertake an open desk format that integrates with numerous processing engines. This was to keep away from vendor lock-in and permit groups to decide on the processing engine that most closely fits their wants. Apache Iceberg’s engine-agnostic and open design meets this requirement by supporting all common processing engines, together with Apache Spark, Amazon Athena, Apache Flink, Trino, Presto, and extra.
As well as, given the substantial information volumes dealt with by the system, an environment friendly desk format was required that may assist querying petabytes of knowledge very quick. Apache Iceberg’s structure addresses this want by effectively filtering and decreasing scanned information, leading to accelerated question instances.
An extra requirement was to permit seamless schema modifications with out impacting end-users. Apache Iceberg’s vary of options, together with schema evolution, hidden partitions, and partition evolution, addresses this requirement.
Lastly, it was vital for Orca to decide on a desk format that’s extensively adopted. Apache Iceberg’s rising and lively neighborhood aligned with the requirement for a preferred and community-backed desk format.
Resolution overview
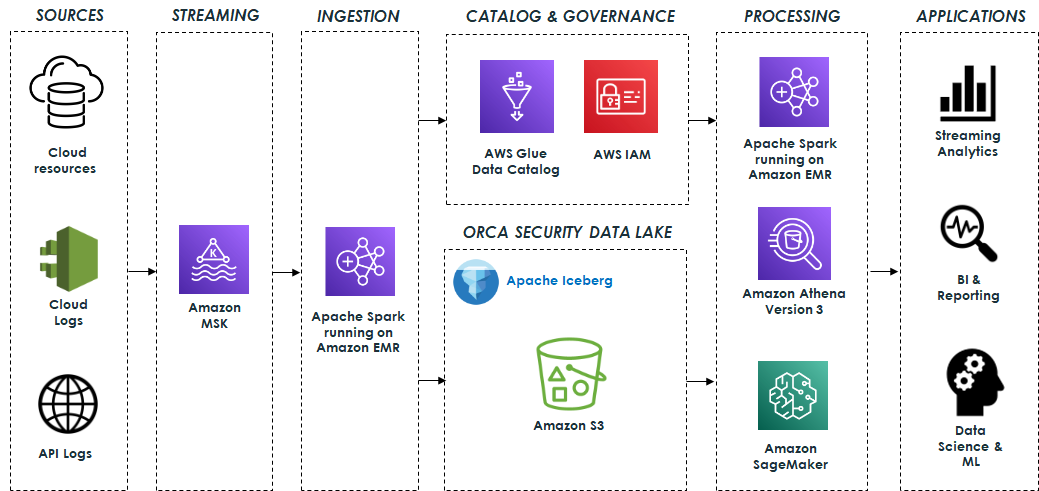
Orca’s information lake relies on open-source applied sciences that seamlessly combine with Apache Iceberg. The system ingests information from numerous sources akin to cloud sources, cloud exercise logs, and API entry logs, and processes billions of messages, leading to terabytes of knowledge day by day. This information is distributed to Apache Kafka, which is hosted on Amazon Managed Streaming for Apache Kafka (Amazon MSK). It’s then processed utilizing Apache Spark Structured Streaming working on Amazon EMR and saved within the information lake. Amazon EMR streamlines the method of loading all required Iceberg packages and dependencies, guaranteeing that the info is saved in Apache Iceberg format and prepared for consumption as shortly as doable.
The info lake is constructed on prime of Amazon S3 utilizing Apache Iceberg desk format with Apache Parquet because the underlying file format. As well as, the AWS Glue Information Catalog permits information discovery, and AWS Identification and Entry Administration (IAM) enforces safe entry controls for the lake and its operations.
The info lake serves as the inspiration for a wide range of capabilities which can be supported by completely different engines.
Information pipelines constructed on Apache Spark and Athena SQL analyze and course of the info saved within the information lake. These information pipelines generate priceless insights and curated information which can be saved in Apache Iceberg tables for downstream utilization. This information is then utilized by numerous functions for streaming analytics, enterprise intelligence, and reporting.
Amazon SageMaker is used to construct, prepare, and deploy a spread of ML fashions. Particularly, the system makes use of Amazon SageMaker Processing jobs to course of the info saved within the information lake, using the AWS SDK for Pandas (beforehand often called AWS Wrangler) for numerous information transformation operations, together with cleansing, normalization, and have engineering. This ensures that the info is appropriate for coaching functions. Moreover, SageMaker coaching jobs are employed for coaching the fashions. After the fashions are skilled, they’re deployed and used to determine anomalies and alert clients in actual time to potential safety threats. The next diagram illustrates the answer structure.
Challenges and classes realized
Orca confronted a number of challenges whereas constructing its petabyte-scale information lake, together with:
- Figuring out optimum desk partitioning
- Optimizing EMR streaming ingestion for prime throughput
- Taming the small information drawback for quick reads
- Maximizing efficiency with Athena model 3
- Sustaining Apache Iceberg tables
- Managing information retention
- Monitoring the info lake infrastructure and operations
- Mitigating information high quality points
On this part, we describe every of those challenges and the options carried out to handle them.
Figuring out optimum desk partitioning
Figuring out optimum partitioning for every desk is essential with a view to optimize question efficiency and decrease the influence on groups querying the tables when partitioning modifications. Apache Iceberg’s hidden partitions mixed with partition transformations proved to be priceless in reaching this aim as a result of it allowed for clear modifications to partitioning with out impacting end-users. Moreover, partition evolution permits experimentation with numerous partitioning methods to optimize price and efficiency with out requiring a rewrite of the desk’s information each time.
For instance, with these options, Orca was capable of simply change a number of of its desk partitioning from DAY to HOUR with no influence on consumer queries. With out this native Iceberg functionality, they might have wanted to coordinate the brand new schema with all of the groups that question the tables and rewrite your complete information, which might have been a pricey, time-consuming, and error-prone course of.
Optimizing EMR streaming ingestion for prime throughput
As talked about beforehand, the system ingests billions of messages day by day, leading to terabytes of knowledge processed and saved every day. Subsequently, optimizing the EMR clusters for the sort of load whereas sustaining excessive throughput and low prices has been an ongoing problem. Orca addressed this in a number of methods.
First, Orca selected to make use of occasion fleets with its EMR clusters as a result of they permit optimized useful resource allocation by combining completely different occasion sorts and sizes. Occasion fleets enhance resilience by permitting a number of Availability Zones to be configured. In consequence, the cluster will launch in an Availability Zone with all of the required occasion sorts, stopping capability limitations. Moreover, occasion fleets can use each Amazon Elastic Compute Cloud (Amazon EC2) On-Demand and Spot cases, leading to price financial savings.
The method of sizing the cluster for prime throughput and decrease prices concerned adjusting the variety of core and job nodes, choosing appropriate occasion sorts, and fine-tuning CPU and reminiscence configurations. In the end, Orca was capable of finding an optimum configuration consisting of on-demand core nodes and spot job nodes of various sizes, which supplied excessive throughput but in addition ensured compliance with SLAs.
Orca additionally discovered that utilizing completely different Kafka Spark Structured Streaming properties, akin to minOffsetsPerTrigger, maxOffsetsPerTrigger, and minPartitions, supplied increased throughput and higher management of the load. Utilizing minPartitions, which permits higher parallelism and distribution throughout a bigger variety of duties, was significantly helpful for consuming excessive lags shortly.
Lastly, when coping with a excessive information ingestion price, Amazon S3 might throttle the requests and return 503 errors. To handle this state of affairs, Iceberg gives a desk property referred to as write.object-storage.enabled, which includes a hash prefix into the saved S3 object path. This method successfully mitigates throttling issues.
Taming the small information drawback for quick reads
A typical problem typically encountered when ingesting streaming information into the info lake is the creation of many small information. This will have a unfavourable influence on learn efficiency when querying the info with Athena or Apache Spark. Having a excessive variety of information results in longer question planning and runtimes because of the have to course of and skim every file, leading to overhead for file system operations and community communication. Moreover, this can lead to increased prices because of the massive variety of S3 PUT and GET requests required.
To handle this problem, Apache Spark Structured Streaming gives the set off mechanism, which can be utilized to tune the speed at which information is dedicated to Apache Iceberg tables. The commit price has a direct influence on the variety of information being produced. As an example, the next commit price, similar to a shorter time interval, ends in a number of information information being produced.
In sure instances, launching the Spark cluster on an hourly foundation and configuring the set off to AvailableNow facilitated the processing of bigger information batches and decreased the variety of small information created. Though this method led to price financial savings, it did contain a trade-off of decreased information freshness. Nonetheless, this trade-off was deemed acceptable for particular use instances.
As well as, to handle preexisting small information throughout the information lake, Apache Iceberg gives a information information compaction operation that mixes these smaller information into bigger ones. Operating this operation on a schedule is very really useful to optimize the quantity and dimension of the information. Compaction additionally proves priceless in dealing with late-arriving information and permits the mixing of this information into consolidated information.
Maximizing efficiency with Athena model 3
Orca was an early adopter of Athena model 3, Amazon’s implementation of the Trino question engine, which gives intensive assist for Apache Iceberg. At any time when doable, Orca most well-liked utilizing Athena over Apache Spark for information processing. This choice was pushed by the simplicity and serverless structure of Athena, which led to decreased prices and simpler utilization, in contrast to Spark, which usually required provisioning and managing a devoted cluster at increased prices.
As well as, Orca used Athena as a part of its mannequin coaching and because the main engine for advert hoc exploratory queries carried out by information scientists, enterprise analysts, and engineers. Nonetheless, for sustaining Iceberg tables and updating desk properties, Apache Spark remained the extra scalable and feature-rich possibility.
Sustaining Apache Iceberg tables
Guaranteeing optimum question efficiency and minimizing storage overhead grew to become a big problem as the info lake grew to a petabyte scale. To handle this problem, Apache Iceberg gives a number of upkeep procedures, akin to the next:
- Information information compaction – This operation, as talked about earlier, entails combining smaller information into bigger ones and reorganizing the info inside them. This operation not solely reduces the variety of information but in addition permits information sorting based mostly on completely different columns or clustering related information utilizing z-ordering. Utilizing Apache Iceberg’s compaction ends in important efficiency enhancements, particularly for big tables, making a noticeable distinction in question efficiency between compacted and uncompacted information.
- Expiring previous snapshots – This operation gives a method to take away outdated snapshots and their related information information, enabling Orca to keep up low storage prices.
Operating these upkeep procedures effectively and cost-effectively utilizing Apache Spark, significantly the compaction operation, which operates on terabytes of knowledge day by day, requires cautious consideration. This entails appropriately sizing the Spark cluster working on EMR and adjusting numerous settings akin to CPU and reminiscence.
As well as, utilizing Apache Iceberg’s metadata tables proved to be very useful in figuring out points associated to the bodily format of Iceberg’s tables, which might straight influence question efficiency. Metadata tables supply insights into the bodily information storage format of the tables and supply the comfort of querying them with Athena model 3. By accessing the metadata tables, essential details about tables’ information information, manifests, historical past, partitions, snapshots, and extra will be obtained, which aids in understanding and optimizing the desk’s information format.
As an example, the next queries can uncover priceless details about the underlying information:
- The variety of information and their common dimension per partition:
- The variety of information information pointed to by every manifest:
- Details about the info information:
- Data associated to information completeness:
Managing information retention
Efficient administration of knowledge retention in a petabyte-scale information lake is essential to make sure low storage prices in addition to to adjust to GDPR. Nonetheless, implementing such a course of will be difficult when coping with Iceberg information saved in S3 buckets, as a result of deleting information based mostly on easy S3 lifecycle insurance policies might doubtlessly trigger desk corruption. It is because Iceberg’s information information are referenced in manifest information, so any modifications to information information should even be mirrored within the manifests.
To handle this problem, sure issues have to be taken into consideration whereas dealing with information retention correctly. Apache Iceberg gives two modes for dealing with deletes, particularly copy-on-write (CoW), and merge-on-read (MoR). In CoW mode, Iceberg rewrites information information on the time of deletion and creates new information information, whereas in MoR mode, as an alternative of rewriting the info information, a delete file is written that lists the place of deleted information in information. These information are then reconciled with the remaining information throughout learn time.
In favor of quicker learn instances, CoW mode is preferable and when used together with the expiring previous snapshots operation, it permits for the onerous deletion of knowledge information which have exceeded the set retention interval.
As well as, by storing the info sorted based mostly on the sphere that shall be utilized for deletion (for instance, organizationID), it’s doable to scale back the variety of information that require rewriting. This optimization considerably enhances the effectivity of the deletion course of, leading to improved deletion instances.
Monitoring the info lake infrastructure and operations
Managing an information lake infrastructure is difficult because of the numerous parts it encompasses, together with these liable for information ingestion, storage, processing, and querying.
Efficient monitoring of all these parts entails monitoring useful resource utilization, information ingestion charges, question runtimes, and numerous different performance-related metrics, and is important for sustaining optimum efficiency and detecting points as quickly as doable.
Monitoring Amazon EMR was essential as a result of it performed an important function within the system for information ingestion, processing, and upkeep. Orca monitored the cluster standing and useful resource utilization of Amazon EMR by using the out there metrics via Amazon CloudWatch. Moreover, it used JMX Exporter and Prometheus to scrape particular Apache Spark metrics and create customized metrics to additional enhance the pipelines’ observability.
One other problem emerged when making an attempt to additional monitor the ingestion progress via Kafka lag. Though Kafka lag monitoring is the usual technique for monitoring ingestion progress, it posed a problem as a result of Spark Structured Streaming manages its offsets internally and doesn’t commit them again to Kafka. To beat this, Orca utilized the progress of the Spark Structured Streaming Question Listener (StreamingQueryListener) to watch the processed offsets, which had been then dedicated to a devoted Kafka shopper group for lag monitoring.
As well as, to make sure optimum question efficiency and determine potential efficiency points, it was important to watch Athena queries. Orca addressed this by utilizing key metrics from Athena and the AWS SDK for Pandas, particularly TotalExecutionTime and ProcessedBytes. These metrics helped determine any degradation in question efficiency and hold observe of prices, which had been based mostly on the dimensions of the info scanned.
Mitigating information high quality points
Apache Iceberg’s capabilities and general structure performed a key function in mitigating information high quality challenges.
One of many methods Apache Iceberg addresses these challenges is thru its schema evolution functionality, which permits customers to change or add columns to a desk’s schema with out rewriting your complete information. This function prevents information high quality points that will come up on account of schema modifications, as a result of the desk’s schema is managed as a part of the manifest information, guaranteeing protected modifications.
Moreover, Apache Iceberg’s time journey function gives the flexibility to overview a desk’s historical past and roll again to a earlier snapshot. This performance has confirmed to be extraordinarily helpful in figuring out potential information high quality points and swiftly resolving them by reverting to a earlier state with identified information integrity.
These strong capabilities be certain that information throughout the information lake stays correct, constant, and dependable.
Conclusion
Information lakes are an important a part of a contemporary information structure, and now it’s simpler than ever to create a sturdy, transactional, cost-effective, and high-performant information lake by utilizing Apache Iceberg, Amazon S3, and AWS Analytics providers akin to Amazon EMR and Athena.
Since constructing the info lake, Orca has noticed important enhancements. The info lake infrastructure has allowed Orca’s platform to have seamless scalability whereas decreasing the price of working its information pipelines by over 50% using Amazon EMR. Moreover, question prices had been decreased by greater than 50% utilizing the environment friendly querying capabilities of Apache Iceberg and Athena model 3.
Most significantly, the info lake has made a profound influence on Orca’s platform and continues to play a key function in its success, supporting new use instances akin to change information seize (CDC) and others, and enabling the event of cutting-edge cloud safety options.
If Orca’s journey has sparked your curiosity and you might be contemplating implementing an analogous answer in your group, listed here are some strategic steps to contemplate:
- Begin by completely understanding your group’s information wants and the way this answer can deal with them.
- Attain out to specialists, who can give you steerage based mostly on their very own experiences. Think about participating in seminars, workshops, or on-line boards that debate these applied sciences. The next sources are really useful for getting began:
- An vital a part of this journey could be to implement a proof of idea. This hands-on expertise will present priceless insights into the complexities of a transactional information lake.
Embarking on a journey to a transactional information lake utilizing Amazon S3, Apache Iceberg, and AWS Analytics can vastly enhance your group’s information infrastructure, enabling superior analytics and machine studying, and unlocking insights that drive innovation.
Concerning the Authors
 Eliad Gat is a Large Information & AI/ML Architect at Orca Safety. He has over 15 years of expertise designing and constructing large-scale cloud-native distributed programs, specializing in massive information, analytics, AI, and machine studying.
Eliad Gat is a Large Information & AI/ML Architect at Orca Safety. He has over 15 years of expertise designing and constructing large-scale cloud-native distributed programs, specializing in massive information, analytics, AI, and machine studying.
 Oded Lifshiz is a Principal Software program Engineer at Orca Safety. He enjoys combining his ardour for delivering revolutionary, data-driven options together with his experience in designing and constructing large-scale machine studying pipelines.
Oded Lifshiz is a Principal Software program Engineer at Orca Safety. He enjoys combining his ardour for delivering revolutionary, data-driven options together with his experience in designing and constructing large-scale machine studying pipelines.
 Yonatan Dolan is a Principal Analytics Specialist at Amazon Internet Companies. He’s situated in Israel and helps clients harness AWS analytical providers to leverage information, acquire insights, and derive worth. Yonatan additionally leads the Apache Iceberg Israel neighborhood.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Internet Companies. He’s situated in Israel and helps clients harness AWS analytical providers to leverage information, acquire insights, and derive worth. Yonatan additionally leads the Apache Iceberg Israel neighborhood.
 Carlos Rodrigues is a Large Information Specialist Options Architect at Amazon Internet Companies. He helps clients worldwide construct transactional information lakes on AWS utilizing open desk codecs like Apache Hudi and Apache Iceberg.
Carlos Rodrigues is a Large Information Specialist Options Architect at Amazon Internet Companies. He helps clients worldwide construct transactional information lakes on AWS utilizing open desk codecs like Apache Hudi and Apache Iceberg.
 Sofia Zilberman is a Sr. Analytics Specialist Options Architect at Amazon Internet Companies. She has a observe document of 15 years of making large-scale, distributed processing programs. She stays keen about massive information applied sciences and structure tendencies, and is continually looking out for practical and technological improvements.
Sofia Zilberman is a Sr. Analytics Specialist Options Architect at Amazon Internet Companies. She has a observe document of 15 years of making large-scale, distributed processing programs. She stays keen about massive information applied sciences and structure tendencies, and is continually looking out for practical and technological improvements.