

{kind=link}
Assuring info system safety requires not simply stopping system compromises but in addition discovering adversaries already current within the community earlier than they will assault from the inside. Defensive laptop operations personnel have discovered the strategy of cyber menace looking a crucial instrument for figuring out such threats. Nonetheless, the time, expense, and experience required for cyber menace looking typically inhibit using this strategy. What’s wanted is an autonomous cyber menace looking instrument that may run extra pervasively, obtain requirements of protection at the moment thought-about impractical, and considerably scale back competitors for restricted time, {dollars}, and naturally analyst sources. On this SEI weblog put up, I describe early work we’ve undertaken to use recreation concept to the event of algorithms appropriate for informing a totally autonomous menace looking functionality. As a place to begin, we’re creating what we seek advice from as chain video games, a set of video games during which menace looking methods may be evaluated and refined.
What’s Risk Searching?
The idea of menace looking has been round for fairly a while. In his seminal cybersecurity work, The Cuckoo’s Egg, Clifford Stoll described a menace hunt he carried out in 1986. Nonetheless, menace looking as a proper follow in safety operations facilities is a comparatively latest improvement. It emerged as organizations started to understand how menace looking enhances two different widespread safety actions: intrusion detection and incident response.
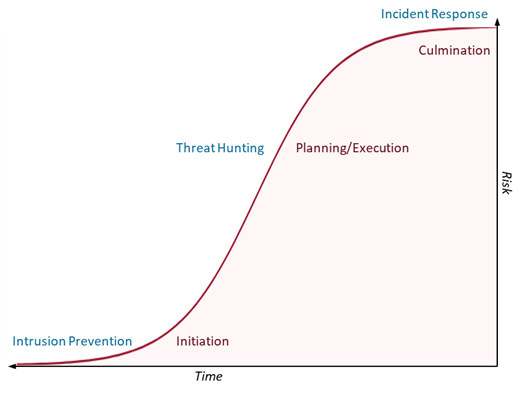
Intrusion detection tries to maintain attackers from moving into the community and initiating an assault, whereas incident response seeks to mitigate injury completed by an attacker after their assault has culminated. Risk looking addresses the hole within the assault lifecycle during which an attacker has evaded preliminary detection and is planning or launching the preliminary levels of execution of their plan (see Determine 1). These attackers can do important injury, however the danger hasn’t been totally realized but by the sufferer group. Risk looking gives the defender one other alternative to search out and neutralize assaults earlier than that danger can materialize.
{kind=link}
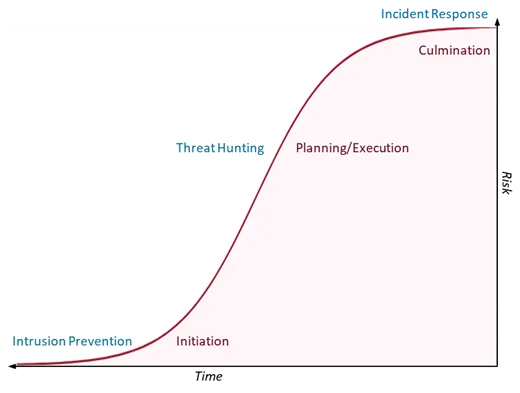
Determine 1: Risk Searching Addresses a Essential Hole within the Assault Lifecycle
Risk looking, nonetheless, requires an excessive amount of time and experience. Particular person hunts can take days or even weeks, requiring hunt workers to make robust choices about which datasets and techniques to research and which to disregard. Each dataset they don’t examine is one that would comprise proof of compromise.
The Imaginative and prescient: Autonomous Risk Searching
Quicker and larger-scale hunts may cowl extra knowledge, higher detect proof of compromise, and alert defenders earlier than the injury is finished. These supercharged hunts may serve a reconnaissance operate, giving human menace hunters info they will use to raised direct their consideration. To attain this pace and financial system of scale, nonetheless, requires automation. Actually, we imagine it requires autonomy—the flexibility for automated processes to predicate, conduct, and conclude a menace hunt with out human intervention.
Human-driven menace looking is practiced all through the DoD, however normally opportunistically when different actions, similar to real-time evaluation, allow. The expense of conducting menace hunt operations sometimes precludes thorough and complete investigation of the realm of regard. By not competing with real-time evaluation or different actions for investigator effort, autonomous menace looking might be run extra pervasively and held to requirements of protection at the moment thought-about impractical.
At this early stage in our analysis on autonomous menace looking, we’re centered within the short-term on quantitative analysis, speedy strategic improvement, and capturing the adversarial high quality of the menace looking exercise.
Modeling the Drawback with Cyber Camouflage Video games
At current, we stay a good distance from our imaginative and prescient of a totally autonomous menace looking functionality that may examine cybersecurity knowledge at a scale approaching the one at which this knowledge is created. To start out down this path, we should have the ability to mannequin the issue in an summary approach that we (and a future automated hunt system) can analyze. To take action, we would have liked to construct an summary framework during which we may quickly prototype and check menace looking methods, probably even programmatically utilizing instruments like machine studying. We believed a profitable strategy would replicate the concept that menace looking includes each the attackers (who want to disguise in a community) and defenders (who wish to discover and evict them). These concepts led us to recreation concept.
We started by conducting a literature overview of latest work in recreation concept to determine researchers already working in cybersecurity, ideally in methods we may instantly adapt to our objective. Our overview did certainly uncover latest work within the space of adversarial deception that we thought we may construct on. Considerably to our shock, this physique of labor centered on how defenders may use deception, somewhat than attackers. In 2018, for instance, a class of video games was developed known as cyber deception video games. These video games, contextualized when it comes to the Cyber Kill Chain, sought to research the effectiveness of deception in irritating attacker reconnaissance. Furthermore, the cyber deception video games had been zero-sum video games, which means that the utility of the attacker and the defender steadiness out. We additionally discovered work on cyber camouflage video games, that are much like cyber deception video games, however are general-sum video games, which means the attacker and defender utility are not straight associated and might range independently.
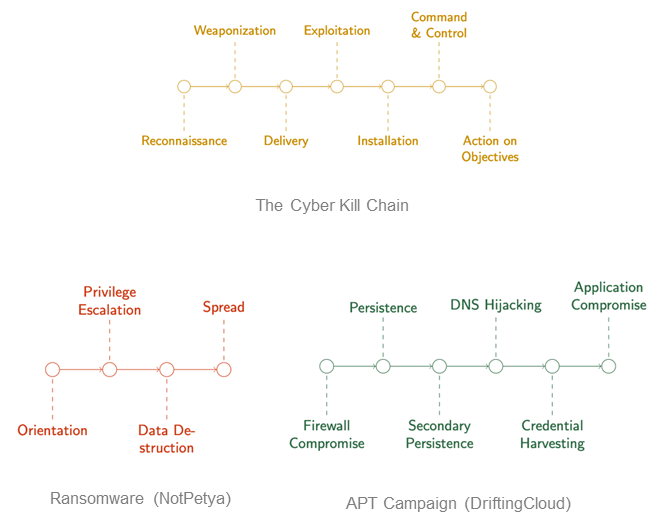
Seeing recreation concept utilized to actual cybersecurity issues made us assured we may apply it to menace looking. Essentially the most influential a part of this work on our analysis issues the Cyber Kill Chain. Kill chains are an idea derived from kinetic warfare, and they’re normally utilized in operational cybersecurity as a communication and categorization instrument. Kill chains are sometimes used to interrupt down patterns of assault, similar to in ransomware and different malware. A greater approach to consider these chains is as assault chains, as a result of they’re getting used for assault characterization.
Elsewhere in cybersecurity, evaluation is finished utilizing assault graphs, which map all of the paths by which a system could be compromised (see Determine 2). You may consider this type of graph as a composition of particular person assault chains. Consequently, whereas the work on cyber deception video games primarily used references to the Cyber Kill Chain to contextualize the work, it struck us as a robust formalism that we may orient our mannequin round.
{kind=link}
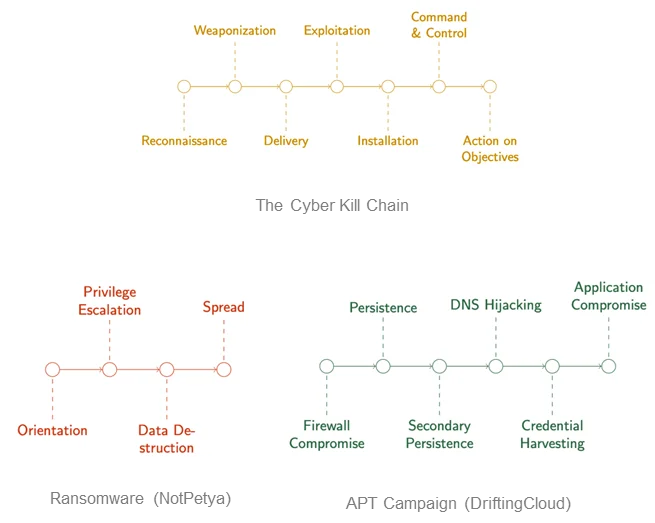
Determine 2: An Assault Graph Using the Cyber Kill Chain
Within the following sections, I’ll describe that mannequin and stroll you thru some easy examples, describe our present work, and spotlight the work we plan to undertake within the close to future.
Easy Chain Video games
Our strategy to modeling cyber menace looking employs a household of video games we seek advice from as chain video games, as a result of they’re oriented round a really summary mannequin of the kill chains. We name this summary mannequin a state chain. Every state in a sequence represents a place of benefit in a community, a pc, a cloud software, or a lot of different completely different contexts in an enterprise’s info system infrastructure. Chain video games are performed on state chains. States signify positions within the community conveying benefit (or drawback) to the attacker. The utility and value of occupying a state may be quantified. Progress via the state chain motivates the attacker; stopping progress motivates the defender.
You may consider an attacker initially establishing themselves in a single state—“state zero” (see “S0” in Determine 3). Maybe somebody within the group clicked on a malicious hyperlink or an e-mail attachment. The attacker’s first order of enterprise is to ascertain persistence on the machine they’ve contaminated to ward in opposition to being unintentionally evicted. To determine this persistence, the attacker writes a file to disk and makes positive it’s executed when the machine begins up. In so doing, they’ve moved from preliminary an infection to persistence, they usually’re advancing into state one. Every extra step an attacker takes to additional their objectives advances them into one other state.
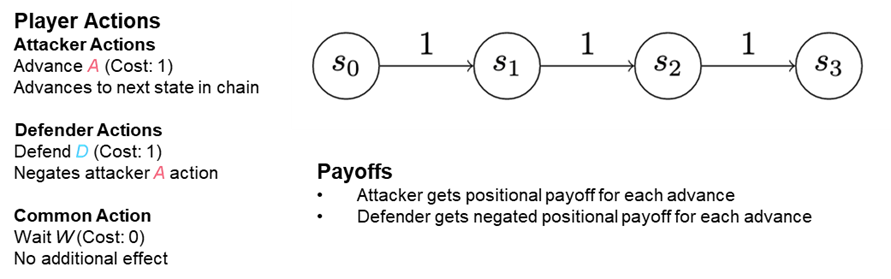{kind=link}
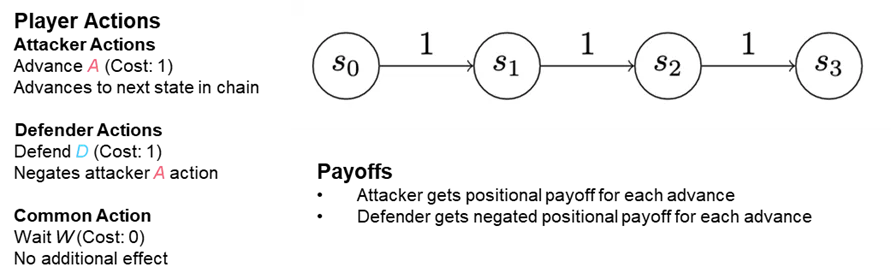
Determine 3: The Genesis of a Risk Searching Mannequin: a Easy Chain Recreation Performed on a State Chain
The sphere isn’t large open for an attacker to take these actions. As an illustration, in the event that they’re not a privileged person, they won’t have the ability to set their file to execute. What’s extra, attempting to take action will reveal their presence to an endpoint safety resolution. So, they’ll must attempt to elevate their privileges and turn out to be an admin person. Nonetheless, that transfer may additionally arouse suspicion. Each actions entail some danger, however in addition they have a possible reward.
To mannequin this example, a price is imposed any time an attacker needs to advance down the chain, however the attacker may alternatively earn a profit by efficiently shifting right into a given state. The defender doesn’t journey alongside the chain just like the attacker: The defender is someplace within the community, capable of observe (and generally cease) a number of the attackers strikes.
All of those chain video games are two-player video games performed between an attacker and a defender, they usually all comply with guidelines governing how the attacker advances via the chain and the way the defender may attempt to cease them. The video games are confined to a hard and fast variety of turns, normally two or three in these examples, and are principally general-sum video games: every participant positive aspects and loses utility independently. We conceived these video games as simultaneous flip video games: Each gamers resolve what to do on the similar time and people actions are resolved concurrently.
We are able to additionally apply graphs to trace the play (see Determine 4). From the attacker standpoint, this graph represents a selection they will make about learn how to assault, exploit, or in any other case function inside the defender community. As soon as the attacker makes that selection, we are able to consider the trail the attacker choses as a sequence. So though the evaluation is oriented round chains, there are methods we are able to deal with extra advanced graphs to consider them like chains.
{kind=link}
Determine 4: Graph Depicting Attacker Play in a Chain Recreation
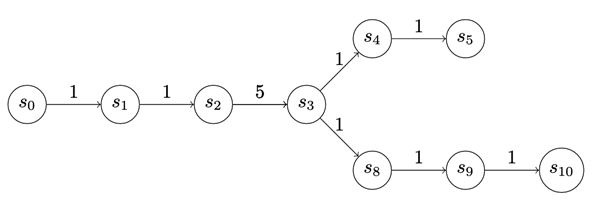
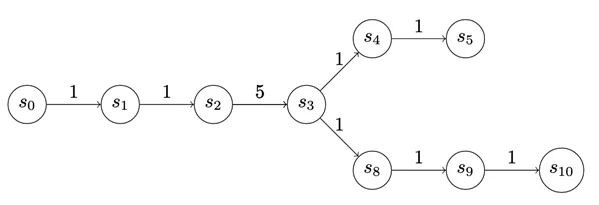
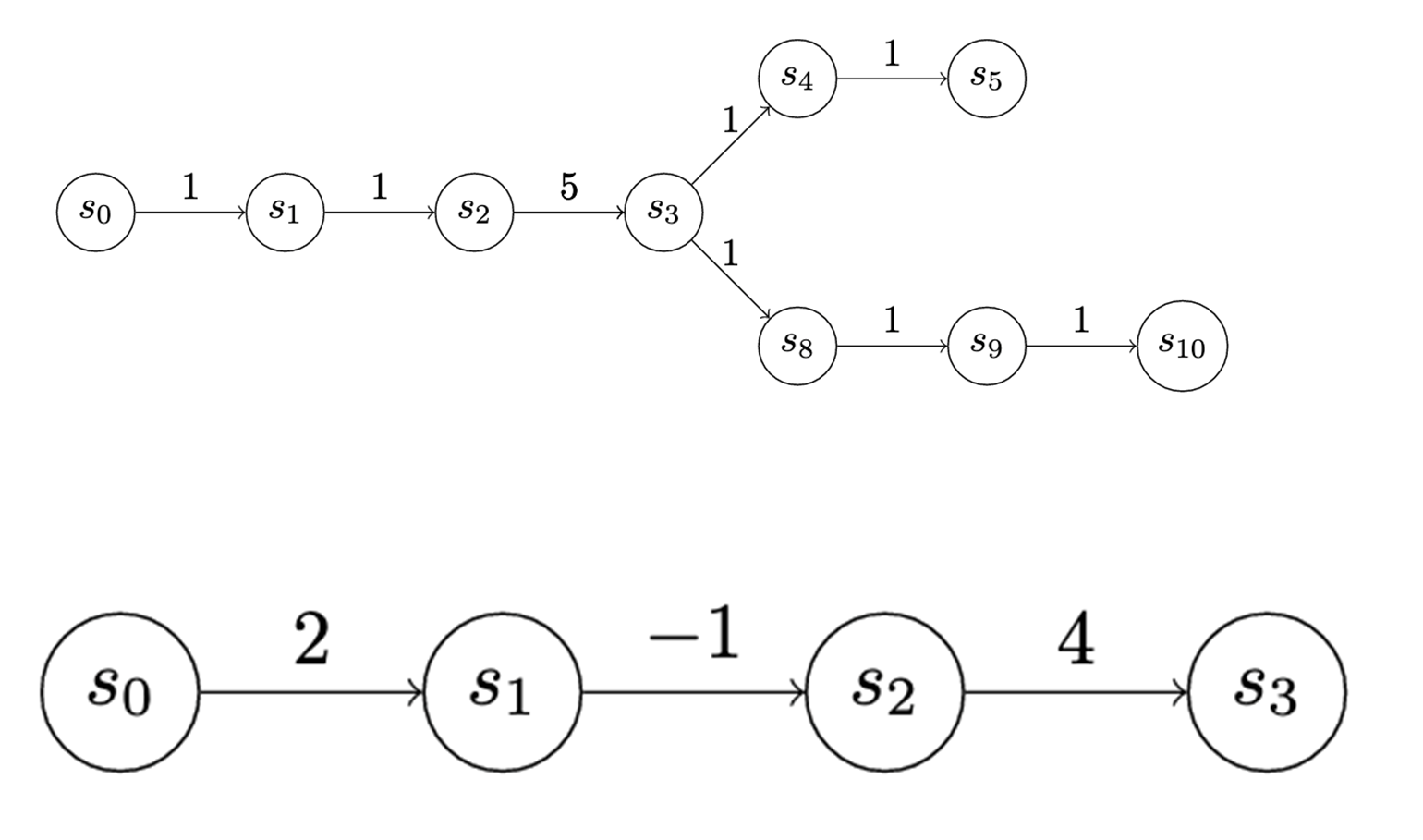
payoff to enter a state is depicted on the edges of the graphs in Determine 5. The payoff doesn’t need to be the identical for every state. We use uniform-value chains for the primary few examples, however there’s really numerous expressiveness on this value task. As an illustration, within the chain under, S3 might signify a precious supply of data, however to entry it the attacker might need to tackle some internet danger.
{kind=link}
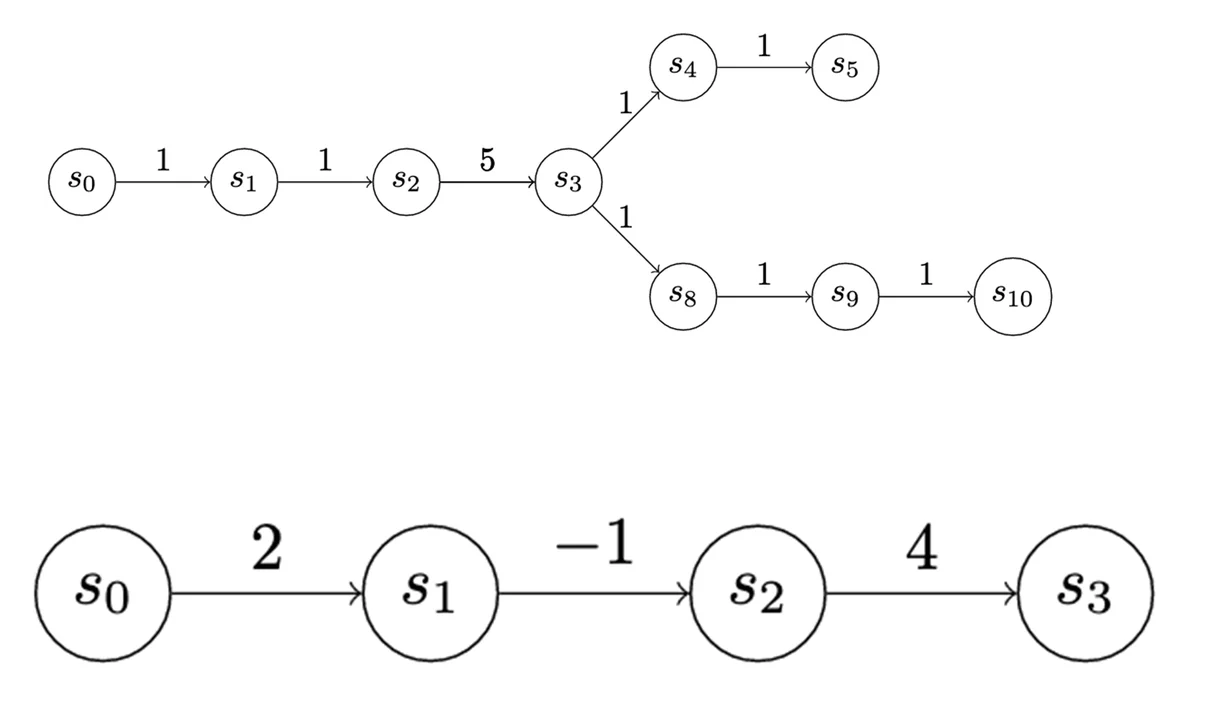
Determine 5: Monitoring the Payoff to the Attacker for Advancing Down the Chain
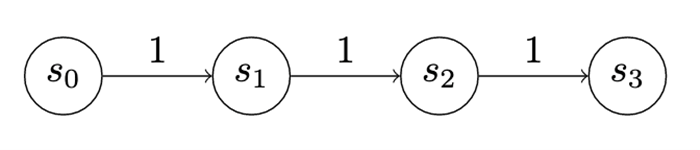
Within the first recreation, which is a quite simple recreation we are able to name “Model 0,” the attacker and defender have two actions every (Determine 6). The attacker can advance, which means they will go from no matter state they’re in to the subsequent state, amassing the utility for getting into the state and paying the price to advance. On this case, the utility for every advance is 1, which is totally offset by the price.
{kind=link}
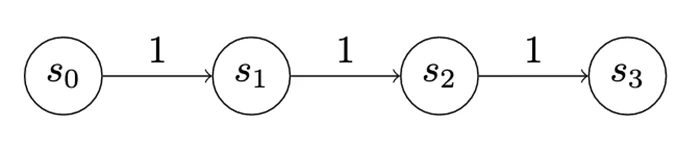
Determine 6: A Easy Recreation, “Model 0,” Demonstrating a Uniform-Worth Chain
Nonetheless, the defender receives -1 utility at any time when an attacker advances (zero-sum). This scoring isn’t meant to incentivize the attacker to advance a lot as to encourage the defender to train their detect motion. A detect will cease an advance, which means the attacker pays the price for the advance however doesn’t change states and doesn’t get any extra utility. Nonetheless, exercising the detect motion prices the defender 1 utility. Consequently, as a result of a penalty is imposed when the attacker advances, the defender is motivated to pay the price for his or her detect motion and keep away from being punished for an attacker advance. Lastly, each the attacker and the defender can select to wait. Ready prices nothing, and earns nothing.
Determine 7 illustrates the payoff matrix of a Model 0 recreation. The matrix exhibits the whole internet utility for every participant once they play the sport for a set variety of turns (on this case, two turns). Every row represents the defender selecting a single sequence of actions: The primary row exhibits what occurs when the defender waits for 2 turns throughout all the opposite completely different sequences of actions the attacker can take. Every cell is a pair of numbers that exhibits how nicely that works out for the defender, which is the left quantity, and the attacker on the correct.
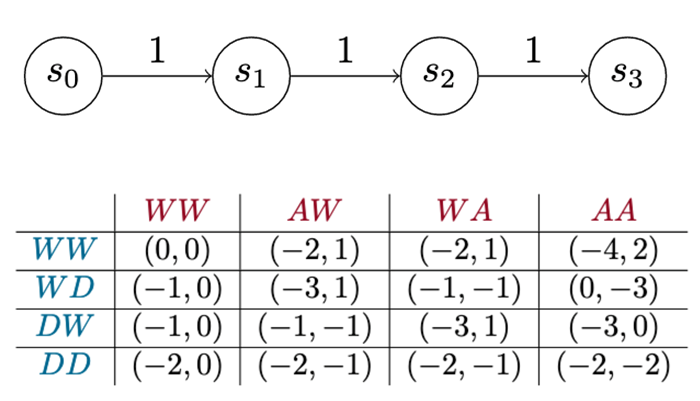{kind=link}
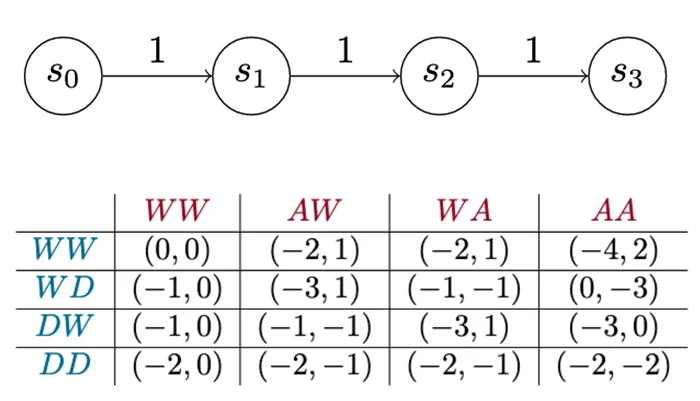
Determine 7: Payoff Matrix for a Easy Assault-Defend Chain Recreation of Two Turns (A=advance; W=wait; D=detect)
This matrix exhibits each technique the attacker or the defender can make use of on this recreation over two turns. Technically, it exhibits each pure technique. With that info, we are able to carry out other forms of study, similar to figuring out dominant methods. On this case, it seems there’s one dominant technique every for the attacker and the defender. The attacker’s dominant technique is to at all times attempt to advance. The defender’s dominant technique is, “By no means detect!” In different phrases, at all times wait. Intuitively, evidently the -1 utility penalty assessed to an attacker to advance isn’t sufficient to make it worthwhile for the defender to pay the price to detect. So, consider this model of the sport as a educating instrument. An enormous a part of making this strategy work lies in selecting good values for these prices and payouts.
Introducing Camouflage
In a second model of our easy chain recreation, we launched some mechanics that helped us take into consideration when to deploy and detect attacker camouflage. You’ll recall from our literature overview that prior work on cyber camouflage video games and cyber deception video games modeled deception as defensive actions, however right here it’s a property of the attacker.
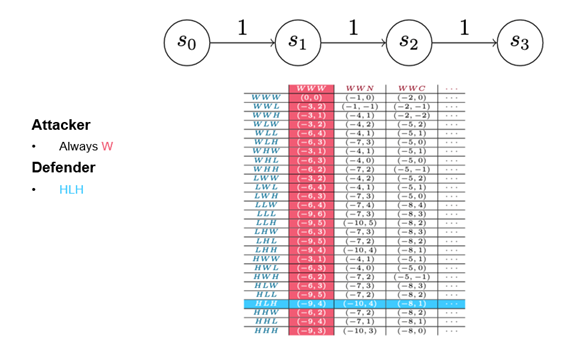
This recreation is similar to Model 0, besides every participant’s major motion has been cut up in two. As an alternative of a single advance motion, the attacker has a noisy advance motion and a camouflaged advance motion. Consequently, this model displays tendencies we see in precise cyber assaults: Some attackers attempt to take away proof of their exercise or select strategies that could be much less dependable however more durable to detect. Others transfer boldly ahead. On this recreation, that dynamic is represented by making a camouflaged advance extra pricey than a noisy advance, but it surely’s more durable to detect.
On the defender facet, the detect motion now splits right into a weak detect and a sturdy detect. A weak detect can solely cease noisy advances; a sturdy detect can cease each varieties of attacker advance, however–in fact–it prices extra. Within the payout matrix (Determine 8), weak and robust detects are known as high and low detections. (Determine 8 presents the full payout matrix. I don’t count on you to have the ability to learn it, however I needed to offer a way of how shortly easy modifications can complicate evaluation.)
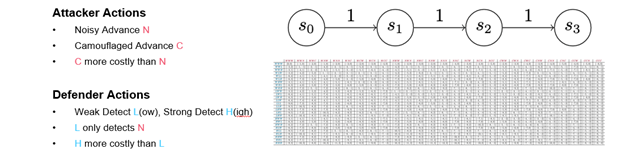{kind=link}
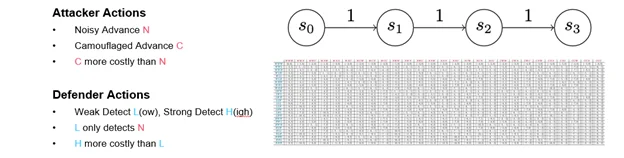
Determine 8: Payout Matrix in a Easy Chain Recreation of Three Turns with Added Assault and Detect Choices
Dominant Technique
In recreation concept, a dominant technique just isn’t the one which at all times wins; somewhat, a technique is deemed dominant if its efficiency is the very best you’ll be able to count on in opposition to a superbly rational opponent. Determine 9 gives a element of the payout matrix that exhibits all of the defender methods and three of the attacker methods. Regardless of the addition of a camouflaged motion, the sport nonetheless produces one dominant technique every for each the attacker and the defender. We’ve tuned the sport, nonetheless, in order that the attacker ought to by no means advance, which is an artifact of the best way we’ve chosen to construction the prices and payouts. So, whereas these explicit methods replicate the best way the sport is tuned, we’d discover that attackers in actual life deploy methods aside from the optimum rational technique. In the event that they do, we’d wish to regulate our habits to optimize for that scenario.
{kind=link}
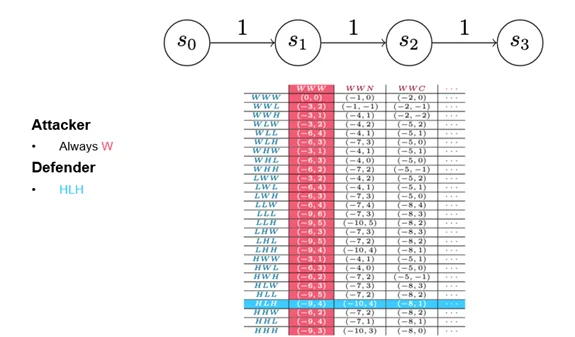
Determine 9: Detailed View of Payout Matrix Indicating Dominant Technique
Extra Advanced Chains
The 2 video games I’ve mentioned up to now had been performed on chains with uniform development prices. After we range that assumption, we begin to get rather more fascinating outcomes. As an illustration, a three-state chain (Determine 10) is a really affordable characterization of sure varieties of assault: An attacker will get numerous utility out of the preliminary an infection, and sees numerous worth in taking a selected motion on aims, however moving into place to take that motion might incur little, no, and even detrimental utility.
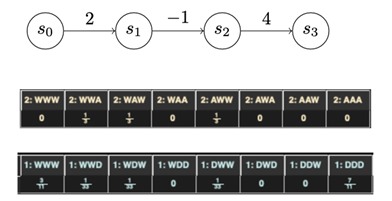{kind=link}
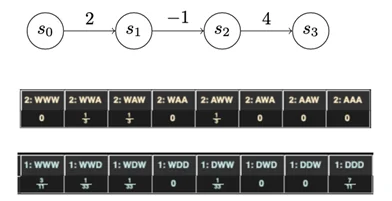
Determine 10: Illustration of a Three-State Chain from the Gambit Recreation Evaluation Instrument
Introducing chains with advanced utilities yields rather more advanced methods for each attacker and defender. Determine 10 is derived from the output of Gambit, which is a recreation evaluation instrument, that describes the dominant methods for a recreation performed over the chain proven under. The dominant methods are actually combined methods. A combined technique signifies that there isn’t any “proper technique” for any single playthrough; you’ll be able to solely outline optimum play when it comes to possibilities. As an illustration, the attacker right here ought to at all times advance one flip and wait the opposite two turns. Nonetheless, the attacker ought to combine it up once they make their advance, spreading them out equally amongst all three turns.
This payout construction might replicate, as an illustration, the implementation of a mitigation of some type in entrance of a precious asset. The attacker is deterred from attacking the asset by the mitigation. However they’re additionally getting some utility from making that first advance. If that utility had been smaller, as an illustration as a result of the utility of compromising one other a part of the community was mitigated, maybe it will be rational for the attacker to both attempt to advance all the best way down the chain or by no means attempt to advance in any respect. Clearly, extra work is required right here to raised perceive what’s occurring, however we’re inspired by seeing this extra advanced habits emerge from such a easy change.
Future Work
Our early efforts on this line of analysis on automated menace looking have urged three areas of future work:
- enriching the sport house
- simulation
- mapping to the issue area
We focus on every of those areas under.
Enriching the Recreation House to Resemble a Risk Hunt
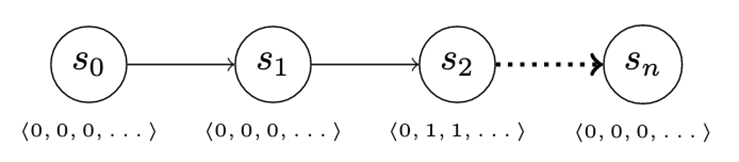
Risk looking normally occurs as a set of information queries to uncover proof of compromise. We are able to replicate this motion in our recreation by introducing an info vector. The data vector modifications when the attacker advances, however not all the knowledge within the vector is robotically obtainable (and due to this fact invisible) to the defender. As an illustration, because the attacker advances from S0 to S1 (Determine 11), there isn’t any change within the info the defender has entry to. Advancing from S1 to S2 modifications a number of the defender-visible knowledge, nonetheless, enabling them to detect attacker exercise.
{kind=link}
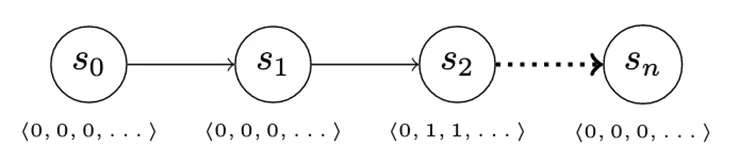
Determine 11: Info Vector Permits for Stealthy Assault
The addition of the knowledge vector permits a lot of fascinating enhancements to our easy recreation. Deception may be modeled as a number of advance actions that differ within the components of the knowledge vector that they modify. Equally, the defender’s detect actions can accumulate proof from completely different components of the vector, or maybe unlock components of the vector to which the defender usually has no entry. This habits might replicate making use of enhanced logging to processes or techniques the place compromise could also be suspected, as an illustration.
Lastly, we are able to additional defender actions by introducing actions to remediate an attacker presence; for instance, by suggesting a number be reinstalled, or by ordering configuration modifications to a useful resource that make it harder for the attacker to advance into.
Simulation
As proven within the earlier instance video games, small problems can lead to many extra choices for participant habits, and this impact creates a bigger house during which to conduct evaluation. Simulation can present approximate helpful details about questions which can be computationally infeasible to reply exhaustively. Simulation additionally permits us to mannequin conditions during which theoretical assumptions are violated to find out whether or not some theoretically suboptimal methods have higher efficiency in particular situations.
Determine 12 presents the definition of model 0 of our recreation in OpenSpiel, a simulation framework from DeepMind. We plan to make use of this instrument for extra lively experimentation within the coming yr.
{kind=link}

Determine 12: Recreation Specification Created with OpenSpiel
Mapping the Mannequin to the Drawback of Risk Searching
Our final instance recreation illustrated how we are able to use completely different advance prices on state chains to raised replicate patterns of community safety and patterns of attacker habits. These patters range relying on how we select to interpret the connection of the state chain to the attacking participant. Extra complexity right here leads to a a lot richer set of methods than the uniform-value chains do.
There are different methods we are able to map primitives in our video games to extra features of the real-world menace looking downside. We are able to use simulation to mannequin empirically noticed methods, and we are able to map options within the info vector to info parts current in real-world techniques. This train lies on the coronary heart of the work we plan to do within the close to future.
Conclusion
Handbook menace looking strategies at the moment obtainable are costly, time consuming, useful resource intensive, and depending on experience. Quicker, inexpensive, and fewer resource-intensive menace looking strategies would assist organizations examine extra knowledge sources, coordinate for protection, and assist triage human menace hunts. The important thing to sooner, inexpensive menace looking is autonomy. To develop efficient autonomous menace looking strategies, we’re creating chain video games, that are a set of video games we use to guage menace looking methods. Within the near-term, our objectives are modeling, quantitatively evaluating and creating methods, speedy strategic improvement, and capturing the adversarial high quality of menace looking exercise. In the long run, our purpose is an autonomous menace looking instrument that may predict adversarial exercise, examine it, and draw conclusions to tell human analysts.