

{kind=link}

|
In March 2023, AWS and NVIDIA introduced a multipart collaboration targeted on constructing essentially the most scalable, on-demand synthetic intelligence (AI) infrastructure optimized for coaching more and more complicated massive language fashions (LLMs) and growing generative AI functions.
We preannounced Amazon Elastic Compute Cloud (Amazon EC2) P5 cases powered by NVIDIA H100 Tensor Core GPUs and AWS’s newest networking and scalability that can ship as much as 20 exaflops of compute efficiency for constructing and coaching the most important machine studying (ML) fashions. This announcement is the product of greater than a decade of collaboration between AWS and NVIDIA, delivering the visible computing, AI, and excessive efficiency computing (HPC) clusters throughout the Cluster GPU (cg1) cases (2010), G2 (2013), P2 (2016), P3 (2017), G3 (2017), P3dn (2018), G4 (2019), P4 (2020), G5 (2021), and P4de cases (2022).
Most notably, ML mannequin sizes at the moment are reaching trillions of parameters. However this complexity has elevated clients’ time to coach, the place the most recent LLMs at the moment are educated over the course of a number of months. HPC clients additionally exhibit related developments. With the constancy of HPC buyer information assortment rising and information units reaching exabyte scale, clients are searching for methods to allow quicker time to resolution throughout more and more complicated functions.
Introducing EC2 P5 Situations
As we speak, we’re asserting the overall availability of Amazon EC2 P5 cases, the next-generation GPU cases to deal with these buyer wants for top efficiency and scalability in AI/ML and HPC workloads. P5 cases are powered by the most recent NVIDIA H100 Tensor Core GPUs and can present a discount of as much as 6 instances in coaching time (from days to hours) in comparison with earlier technology GPU-based cases. This efficiency improve will allow clients to see as much as 40 % decrease coaching prices.
P5 cases present 8 x NVIDIA H100 Tensor Core GPUs with 640 GB of excessive bandwidth GPU reminiscence, third Gen AMD EPYC processors, 2 TB of system reminiscence, and 30 TB of native NVMe storage. P5 cases additionally present 3200 Gbps of combination community bandwidth with help for GPUDirect RDMA, enabling decrease latency and environment friendly scale-out efficiency by bypassing the CPU on internode communication.
Listed here are the specs for these cases:
| Occasion Dimension |
vCPUs | Reminiscence (GiB) |
GPUs (H100) |
Community Bandwidth (Gbps) |
EBS Bandwidth (Gbps) |
Native Storage (TB) |
| P5.48xlarge | 192 | 2048 | 8 | 3200 | 80 | 8 x 3.84 |
Right here’s a fast infographic that exhibits you the way the P5 cases and NVIDIA H100 Tensor Core GPUs evaluate to earlier cases and processors:
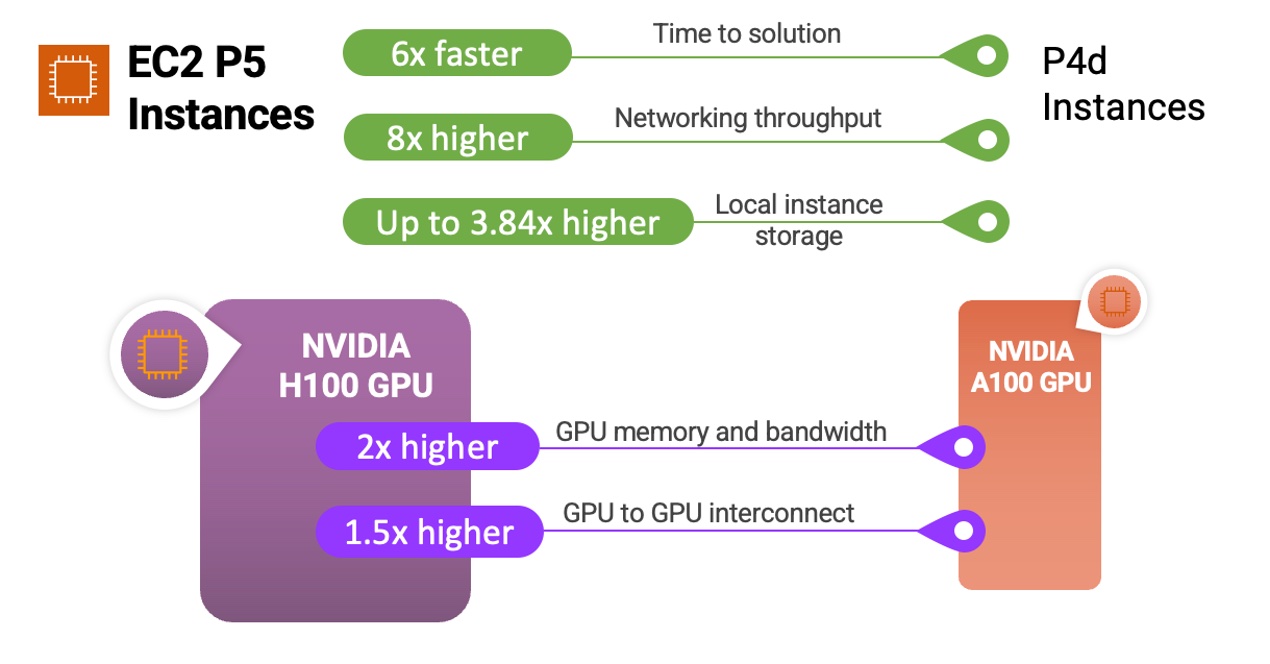
P5 cases are perfect for coaching and operating inference for more and more complicated LLMs and pc imaginative and prescient fashions behind essentially the most demanding and compute-intensive generative AI functions, together with query answering, code technology, video and picture technology, speech recognition, and extra. P5 will present as much as 6 instances decrease time to coach in contrast with earlier technology GPU-based cases throughout these functions. Clients who can use decrease precision FP8 information sorts of their workloads, widespread in lots of language fashions that use a transformer mannequin spine, will see additional profit at as much as 6 instances efficiency improve by help for the NVIDIA transformer engine.
HPC clients utilizing P5 cases can deploy demanding functions at higher scale in pharmaceutical discovery, seismic evaluation, climate forecasting, and monetary modeling. Clients utilizing dynamic programming (DP) algorithms for functions like genome sequencing or accelerated information analytics can even see additional profit from P5 by help for a brand new DPX instruction set.
This permits clients to discover downside areas that beforehand appeared unreachable, iterate on their options at a quicker clip, and get to market extra rapidly.
You’ll be able to see the element of occasion specs together with comparisons of occasion sorts between p4d.24xlarge and new p5.48xlarge under:
| Characteristic | p4d.24xlarge | p5.48xlarge | Comparision |
| Quantity & Sort of Accelerators | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| FP8 TFLOPS per Server | – | 16,000 | 640% vs.A100 FP16 |
| FP16 TFLOPS per Server | 2,496 | 8,000 | |
| GPU Reminiscence | 40 GB | 80 GB | 200% |
| GPU Reminiscence Bandwidth | 12.8 TB/s | 26.8 TB/s | 200% |
| CPU Household | Intel Cascade Lake | AMD Milan | – |
| vCPUs | 96 | 192 | 200% |
| Complete System Reminiscence | 1152 GB | 2048 GB | 200% |
| Networking Throughput | 400 Gbps | 3200 Gbps | 800% |
| EBS Throughput | 19 Gbps | 80 Gbps | 400% |
| Native Occasion Storage | 8 TBs NVMe | 30 TBs NVMe | 375% |
| GPU to GPU Interconnect | 600 GB/s | 900 GB/s | 150% |
Second-generation Amazon EC2 UltraClusters and Elastic Cloth Adaptor
P5 cases present market-leading scale-out functionality for multi-node distributed coaching and tightly coupled HPC workloads. They provide as much as 3,200 Gbps of networking utilizing the second-generation Elastic Cloth Adaptor (EFA) know-how, 8 instances in contrast with P4d cases.
To handle buyer wants for large-scale and low latency, P5 cases are deployed within the second-generation EC2 UltraClusters, which now present clients with decrease latency throughout as much as 20,000+ NVIDIA H100 Tensor Core GPUs. Offering the most important scale of ML infrastructure within the cloud, P5 cases in EC2 UltraClusters ship as much as 20 exaflops of combination compute functionality.

EC2 UltraClusters use Amazon FSx for Lustre, absolutely managed shared storage constructed on the preferred high-performance parallel file system. With FSx for Lustre, you’ll be able to rapidly course of large datasets on demand and at scale and ship sub-millisecond latencies. The low-latency and high-throughput traits of FSx for Lustre are optimized for deep studying, generative AI, and HPC workloads on EC2 UltraClusters.
FSx for Lustre retains the GPUs and ML accelerators in EC2 UltraClusters fed with information, accelerating essentially the most demanding workloads. These workloads embody LLM coaching, generative AI inferencing, and HPC workloads, corresponding to genomics and monetary threat modeling.
Getting Began with EC2 P5 Situations
To get began, you should use P5 cases within the US East (N. Virginia) and US West (Oregon) Area.
When launching P5 cases, you’ll select AWS Deep Studying AMIs (DLAMIs) to help P5 cases. DLAMI gives ML practitioners and researchers with the infrastructure and instruments to rapidly construct scalable, safe distributed ML functions in preconfigured environments.
It is possible for you to to run containerized functions on P5 cases with AWS Deep Studying Containers utilizing libraries for Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS). For a extra managed expertise, you too can use P5 cases by way of Amazon SageMaker, which helps builders and information scientists simply scale to tens, tons of, or hundreds of GPUs to coach a mannequin rapidly at any scale with out worrying about organising clusters and information pipelines. HPC clients can leverage AWS Batch and ParallelCluster with P5 to assist orchestrate jobs and clusters effectively.
Current P4 clients might want to replace their AMIs to make use of P5 cases. Particularly, you will have to replace your AMIs to incorporate the most recent NVIDIA driver with help for NVIDIA H100 Tensor Core GPUs. They can even want to put in the most recent CUDA model (CUDA 12), CuDNN model, framework variations (e.g., PyTorch, Tensorflow), and EFA driver with up to date topology information. To make this course of simple for you, we are going to present new DLAMIs and Deep Studying Containers that come prepackaged with all of the wanted software program and frameworks to make use of P5 cases out of the field.
Now Out there
Amazon EC2 P5 cases can be found at the moment in AWS Areas: US East (N. Virginia) and US West (Oregon). For extra data, see the Amazon EC2 pricing web page. To be taught extra, go to our P5 occasion web page and discover AWS re:Put up for EC2 or by your traditional AWS Assist contacts.
You’ll be able to select a broad vary of AWS companies which have generative AI in-built, all operating on essentially the most cost-effective cloud infrastructure for generative AI. To be taught extra, go to Generative AI on AWS to innovate quicker and reinvent your functions.
— Channy