

{kind=link}
Amazon Athena is a serverless, interactive analytics service constructed on the Trino, PrestoDB, and Apache Spark open-source frameworks. You need to use Athena to run SQL queries on petabytes of knowledge saved on Amazon Easy Storage Service (Amazon S3) in broadly used codecs comparable to Parquet and open-table codecs like Apache Iceberg, Apache Hudi, and Delta Lake. Nonetheless, Athena additionally permits you to question knowledge saved in 30 totally different knowledge sources—along with Amazon S3—together with relational, non-relational, and object shops operating on premises or in different cloud environments.
In Athena, we consult with queries on non-Amazon S3 knowledge sources as federated queries. These queries run on the underlying database, which suggests you’ll be able to analyze the information with out studying a brand new question language and with out the necessity for separate extract, rework, and cargo (ETL) scripts to extract, duplicate, and put together knowledge for evaluation.
Just lately, Athena added help for creating and querying views on federated knowledge sources to carry higher flexibility and ease of use to make use of instances comparable to interactive evaluation and enterprise intelligence reporting. Athena additionally up to date its knowledge connectors with optimizations that enhance efficiency and cut back value when querying federated knowledge sources. The up to date connectors use dynamic filtering and an expanded set of predicate pushdown optimizations to carry out extra operations within the underlying knowledge supply slightly than in Athena. Because of this, you get sooner queries with much less knowledge scanned, particularly on tables with hundreds of thousands to billions of rows of knowledge.
On this publish, we present easy methods to create and question views on federated knowledge sources in a knowledge mesh structure that includes knowledge producers and customers.
The time period knowledge mesh refers to an information structure with decentralized knowledge possession. A knowledge mesh permits domain-oriented groups with the information they want, emphasizes self-service, and promotes the notion of purpose-built knowledge merchandise. In a knowledge mesh, knowledge producers expose datasets to the group and knowledge customers subscribe to and devour the information merchandise created by producers. By distributing knowledge possession to cross-functional groups, a knowledge mesh can foster a tradition of collaboration, invention, and agility round knowledge.
Let’s dive into the answer.
Resolution overview
For this publish, think about a hypothetical ecommerce firm that makes use of a number of knowledge sources, every taking part in a distinct position:
- In an S3 knowledge lake, ecommerce data are saved in a desk named
Lineitems - Amazon ElastiCache for Redis shops
NationsandActiveOrdersknowledge, making certain ultra-fast reads of operational knowledge by downstream ecommerce methods - On Amazon Relational Database Service (Amazon RDS), MySQL is used to retailer knowledge like electronic mail addresses and transport addresses within the Orders, Buyer, and Suppliers tables
- For flexibility and low-latency reads and writes, an Amazon DynamoDB desk holds
HalfandPartsuppknowledge
We need to question these knowledge sources in a knowledge mesh design. Within the following sections, we arrange Athena knowledge supply connectors for MySQL, DynamoDB, and Redis, after which run queries that carry out complicated joins throughout these knowledge sources. The next diagram depicts our knowledge structure.

As you proceed with this resolution, observe that you’ll create AWS sources in your account. We’ve offered you with an AWS CloudFormation template that defines and configures the required sources, together with the pattern MySQL database, S3 tables, Redis retailer, and DynamoDB desk. The template additionally creates the AWS Glue database and tables, S3 bucket, Amazon S3 VPC endpoint, AWS Glue VPC endpoint, and different AWS Identification and Entry Administration (IAM) sources which might be used within the resolution.
The template is designed to reveal easy methods to use federated views in Athena, and isn’t meant for manufacturing use with out modification. Moreover, the template makes use of the us-east-1 Area and won’t work in different Areas with out modification. The template creates sources that incur prices whereas they’re in use. Observe the cleanup steps on the finish of this publish to delete the sources and keep away from pointless expenses.
Stipulations
Earlier than you launch the CloudFormation stack, guarantee you will have the next stipulations:
- An AWS account that gives entry to AWS companies
- An IAM consumer with an entry key and secret key to configure the AWS Command Line Interface (AWS CLI), and permissions to create an IAM position, IAM insurance policies, and stacks in AWS CloudFormation
Create sources with AWS CloudFormation
To get began, full the next steps:
- Select Launch Stack:

- Choose I acknowledge that this template might create IAM sources.
The CloudFormation stack takes roughly 20–half-hour to finish. You may monitor its progress on the AWS CloudFormation console. When standing reads CREATE_COMPLETE, your AWS account may have the sources essential to implement this resolution.
Deploy connectors and hook up with knowledge sources
With our sources provisioned, we will start to attach the dots in our knowledge mesh. Let’s begin by connecting the information sources created by the CloudFormation stack with Athena.
- On the Athena console, select Knowledge sources within the navigation pane.
- Select Create knowledge supply.
- For Knowledge sources, choose MySQL, then select Subsequent.
- For Knowledge supply title, enter a reputation, comparable to
mysql. The Athena connector for MySQL is an AWS Lambda perform that was created for you by the CloudFormation template. - For Connection particulars, select Choose or enter a Lambda perform.
- Select
mysql, then select Subsequent. - Assessment the data and select Create knowledge supply.
- Return to the Knowledge sources web page and select
mysql. - On the connector particulars web page, select the hyperlink below Lambda perform to entry the Lambda console and examine the perform related to this connector.

- Return to the Athena question editor.
- For Knowledge supply, select
mysql. - For Database, select the
gross salesdatabase. - For Tables, it is best to see a list of MySQL tables which might be prepared so that you can question.
- Repeat these steps to arrange the connectors for DynamoDB and Redis.
In spite of everything 4 knowledge sources are configured, we will see the information sources on the Knowledge supply drop-down menu. All different databases and tables, just like the lineitem desk, which is saved on Amazon S3, are outlined within the AWS Glue Knowledge Catalog and might be accessed by selecting AwsDataCatalog as the information supply.
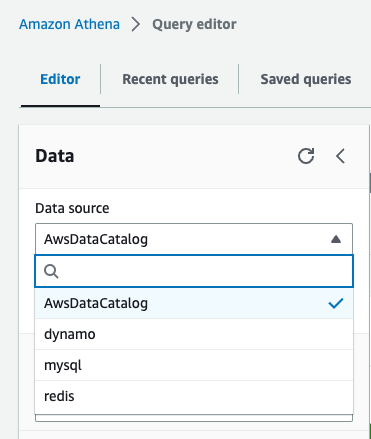
Analyze knowledge with Athena
With our knowledge sources configured, we’re prepared to begin operating queries and utilizing federated views in a knowledge mesh structure. Let’s begin by looking for out how a lot revenue was made on a given line of components, damaged out by provider nation and yr.
For such a question, we have to calculate, for every nation and yr, the revenue for components ordered in annually that have been stuffed by a provider in every nation. Revenue is outlined because the sum of [(l_extendedprice*(1-l_discount)) - (ps_supplycost * l_quantity)] for all line objects describing components within the specified line.
Answering this query requires querying all 4 knowledge sources—MySQL, DynamoDB, Redis, and Amazon S3—and is achieved with the next SQL:
Working this question on the Athena console produces the next outcome.
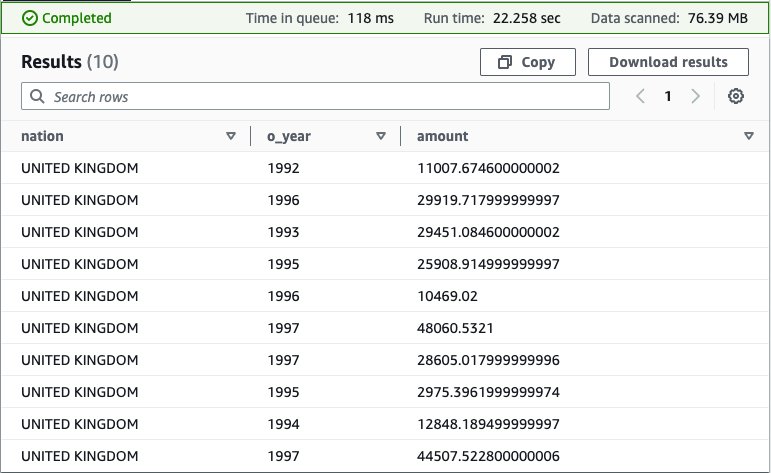
This question is pretty complicated: it entails a number of joins and requires particular information of the right approach to calculate revenue metrics that different end-users might not possess.
To simplify the evaluation expertise for these customers, we will disguise this complexity behind a view. For extra data on utilizing views with federated knowledge sources, see Querying federated views.
Use the next question to create the view within the data_lake database below the AwsDataCatalog knowledge supply:
Subsequent, run a easy choose question to validate the view was created efficiently: SELECT * FROM federated_view restrict 10
The outcome ought to be much like our earlier question.
With our view in place, we will carry out new analyses to reply questions that might be difficult with out the view as a result of complicated question syntax that might be required. For instance, we will discover the full revenue by nation:
Your outcomes ought to resemble the next screenshot.
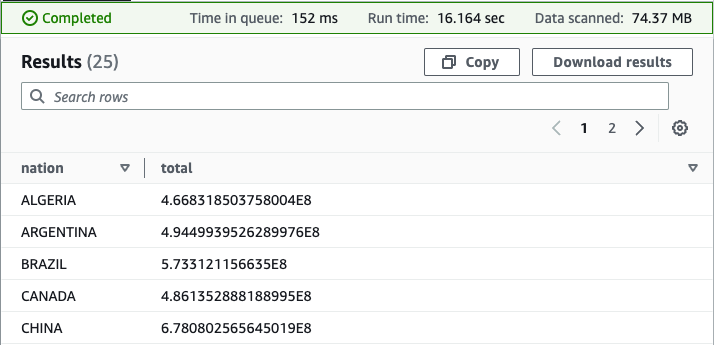
As you now see, the federated view makes it easier for end-users to run queries on this knowledge. Customers are free to question a view of the information, outlined by a educated knowledge producer, slightly than having to first purchase experience in every underlying knowledge supply. As a result of Athena federated queries are processed the place the information is saved, with this method, we keep away from duplicating knowledge from the supply system, saving beneficial time and price.
Use federated views in a multi-user mannequin
Up to now, now we have happy one of many ideas of a knowledge mesh: we created a knowledge product (federated view) that’s decoupled from its originating supply and is on the market for on-demand evaluation by customers.
Subsequent, we take our knowledge mesh a step additional through the use of federated views in a multi-user mannequin. To maintain it easy, assume now we have one producer account, the account we used to create our 4 knowledge sources and federated view, and one client account. Utilizing the producer account, we give the patron account permission to question the federated view from the patron account.
The next determine depicts this setup and our simplified knowledge mesh structure.
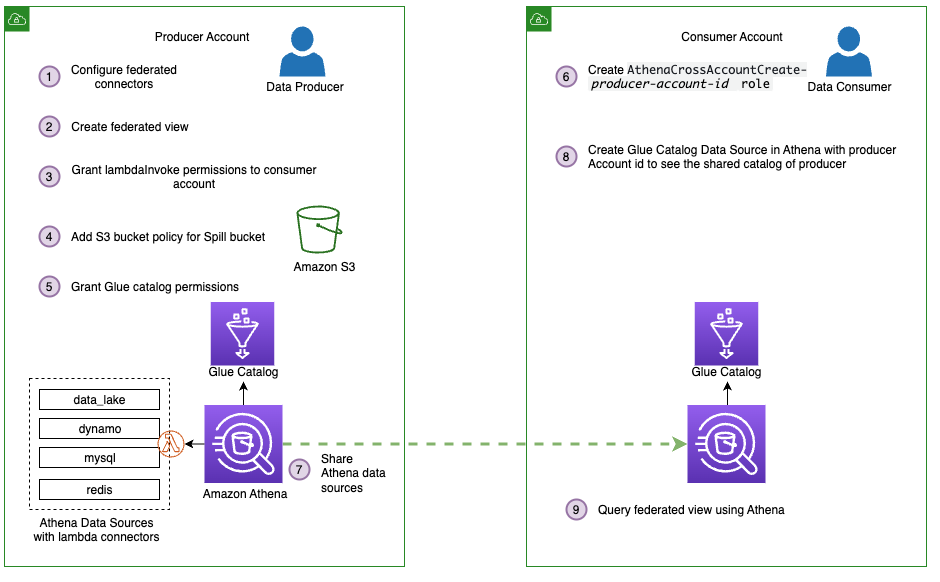
Observe these steps to share the connectors and AWS Glue Knowledge Catalog sources from the producer, which incorporates our federated view, with the patron account:
- Share the information sources
mysql,redis,dynamo, anddata_lakewith the patron account. For directions, consult with Sharing a knowledge supply in Account A with Account B. Be aware that Account A represents the producer and Account B represents the patron. Be sure you use the identical knowledge supply names from earlier when sharing knowledge. That is needed for the federated view to work in a cross-account mannequin. - Subsequent, share the producer account’s AWS Glue Knowledge Catalog with the patron account by following the steps in Cross-account entry to AWS Glue knowledge catalogs. For the information supply title, use
shared_federated_catalog. - Change to the patron account, navigate to the Athena console, and confirm that you simply see
federated_viewlisted below Views within theshared_federated_catalogKnowledge Catalog anddata_lakedatabase. - Subsequent, run a pattern question on the shared view to see the question outcomes.
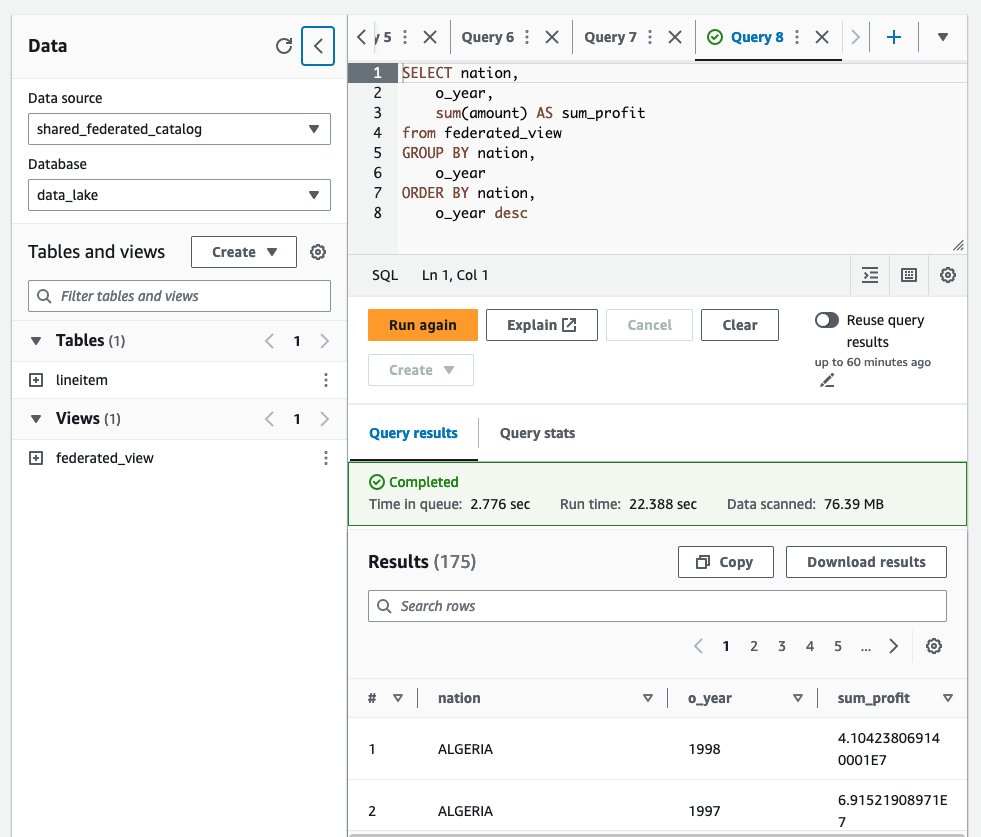
Clear up
To wash up the sources created for this publish, full the next steps:
- On the Amazon S3 console, empty the bucket
athena-federation-workshop-<account-id>. - In case you’re utilizing the AWS CLI, delete the objects within the
athena-federation-workshop-<account-id>bucket with the next code. Be sure you run this command on the right bucket.aws s3 rm s3://athena-federation-workshop-<account-id> --recursive - On the AWS CloudFormation console or the AWS CLI, delete the stack
athena-federated-view-blog.
Abstract
On this publish, we demonstrated the performance of Athena federated views. We created a view spanning 4 totally different federated knowledge sources and ran queries towards it. We additionally noticed how federated views may very well be prolonged to a multi-user knowledge mesh and ran queries from a client account.
To reap the benefits of federated views, guarantee you might be utilizing Athena engine model 3 and improve your knowledge supply connectors to the most recent model obtainable. For data on easy methods to improve a connector, see Updating a knowledge supply connector.
In regards to the Authors
 Saurabh Bhutyani is a Principal Huge Knowledge Specialist Options Architect at AWS. He’s obsessed with new applied sciences. He joined AWS in 2019 and works with clients to offer architectural steering for operating scalable analytics options and knowledge mesh architectures utilizing AWS analytics companies like Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Huge Knowledge Specialist Options Architect at AWS. He’s obsessed with new applied sciences. He joined AWS in 2019 and works with clients to offer architectural steering for operating scalable analytics options and knowledge mesh architectures utilizing AWS analytics companies like Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
 Pathik Shah is a Sr. Huge Knowledge Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the large knowledge analytics house since then, serving to clients construct scalable and strong options utilizing AWS analytics companies.
Pathik Shah is a Sr. Huge Knowledge Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the large knowledge analytics house since then, serving to clients construct scalable and strong options utilizing AWS analytics companies.