
{kind=link}
Anaconda made some information yesterday when it introduced assist for Pandata, a brand new open-source stack. However simply what’s Pandata, and may it’s in your huge information radar?
In accordance with the Pandata GitHub web page, Pandata is a set of scalable Python-based information instruments used for scientific, engineering, and evaluation workloads. There are greater than 20 completely different Python-based instruments listed as being a part of Pandata, together with acquainted names like Pandas, Numba, Dask, Jupyter, Plotly, and Conda.
The Python libraries that make up Pandata had been developed individually to supply capabilities for information storage, entry, processing, and visualization capabilites amongst others. However they had been designed to work nicely collectively, in accordance with GitHub web page, which is maintained by James Bednar, the director of customized providers at Anaconda.
Pandata is meant to leverage the broad Python ecosystem to ship the high-performance and scalable information analyses capabilites that the scientific and engineering communities want however should not discovering with legacy device stacks, in accordance with Bednar.
Bednar and fellow Anaconda worker Martin Durant wrote a paper about Pandata for the current SCIPY 2023 convention. Titled “The Pandata Scalable Open-Supply Evaluation Stack,” the eight-page paper describes the necessity for Pandata, and the traits of Pandata instruments. In accordance with the paper, Pandata is required to switch older, domain-specific tooling with a brand new information stack that’s composed of instruments which might be area unbiased, excessive efficiency, and scalable.
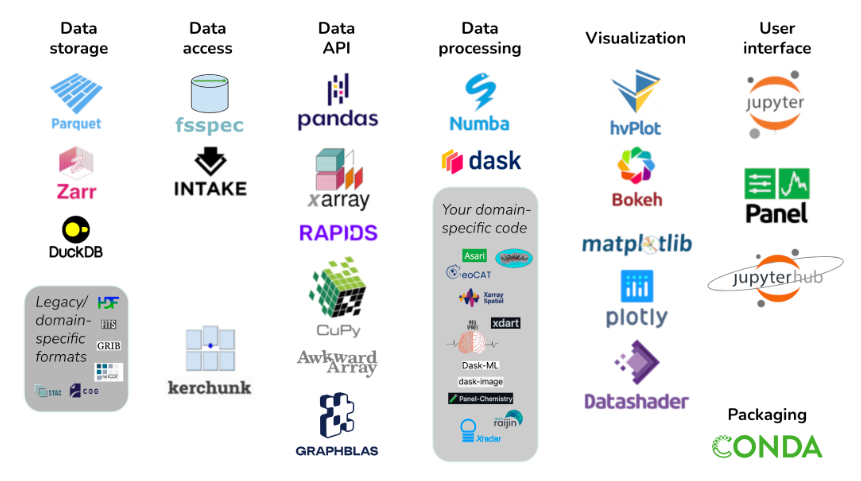
Members of the Pandata ecosystem
“As the dimensions of scientific information evaluation grows, conventional domain-specific software program instruments are hitting limits when managing elevated information measurement and complexity,” Bednar and Durant write within the paper. “These instruments additionally face sustainability challenges resulting from a comparatively slender consumer base, a restricted pool of contributors, and constrained funding sources. We introduce the Pandata open-source software program stack as an answer, emphasizing using domain-independent instruments at important phases of the info life cycle, with out compromising the depth of domain-specific analyses.”
The instruments within the Pandata stack, which is distributed beneath a BSD-3-Clause license, all use vectorized computing or JIT compilation and may run on any pc, from the smallest single-core laptop computer to the biggest thousand-node clusters, Bednar and Durant write. The instruments are cloud pleasant and in addition run on a number of working programs and processor varieties, they write.
There are different traits uniting the instruments within the Pandata stack, they write. They’re compositional, which suggests they are often mixed collectively to resolve your downside. They’re visualizable, which suggests they assist rendering even the biggest datasets with out conversion or approximation. They’re interactive, which suggests they assist absolutely interactive exploration, not simply rendering static photographs or textual content information. They’re shareable, which suggests they’re deployable as Net apps to be used by anybody wherever. And lastly, their open supply, which suggests they can be utilized for analysis or business use, with out restrictive licensing.
Anaconda, which has been a pressure for standardization of Python-based instruments up to now, says there are various examples of Pandata getting used already. Among the many organizations utilizing Pandata are Pangeo, a supplier of Python-based instruments for geographic information, in addition to Challenge Pythia, which is Pangeo’s training working group.
Whereas the instruments within the Pandata stack are extensible and appropriate with one another, that doesn’t imply they play properly with instruments in different stacks, even when they had been inbuilt Python or leverage different instruments within the Python ecosystems.
For example, the Ray represents an alternative choice to distributed computation that’s not supported by the Pandata instruments. “And so if a undertaking makes use of Ray to handle distributed computation, then they can not (presently) simply choose hvPlot for visualization with out first changing the info buildings into one thing hvPlot understands,” Bednar and Durant write.
Equally, issues like Vaex and Polars present options to the Pandas/Dask dataframes supported in Pandas, they write, whereas instruments like VegaFusion present a solution to render giant information units, however which aren’t appropriate with Pandata. There are different built-in stacks of instruments, resembling Hadoop and Spark within the Apache ecosystem. Nevertheless, these instruments typicaly require Java, however the heaviness of the JVM makes it troublesome to mix these Java instruments with lighter weight Python-based instruments, they write.
“The Pandata stack is able to use at the moment, as an in depth foundation for scientific computing in any analysis space and throughout many various communities,” Bednar and Durant conclude within the paper. “There are options for every of the parts of the Pandata stack, however the benefit of getting this very big selection of performance that works nicely collectively is that researchers in any explicit area can simply get on with their precise work in that area, free of having to reimplement fundamental information dealing with in all its types and free of the restrictions of legacy domain-specific stacks. Every thing concerned is open supply, so be happy to make use of any of those instruments in any mixture to resolve any issues that you’ve got!”
Associated Objects:
Anaconda Bolsters Information Literacy with Strikes Into Training
Anaconda Unveils New Coding Notebooks and Coaching Portal
Anaconda Unveils PyScript, the ‘Minecraft for Software program Growth’