

{kind=link}
Abstract:
- Pagination is a method used to divide a result-set into smaller, extra manageable chunks
- Traditionally, Rockset used the Restrict-Offset methodology to implement pagination, however question outcomes could be gradual and inconsistent when coping with very massive information units in real-time
- Rockset has now carried out a cursor-based method for pagination, making queries sooner, extra constant, and doubtlessly cheaper for giant information units
- That is accessible in the present day for all prospects
Pagination is a well-known approach within the database world. For those who’ve run a SQL question with Restrict-Offset on a database like PostgreSQL then you definitely already know what we’re speaking about right here. Nevertheless, for individuals who have by no means heard of the time period, pagination is a method used to divide a result-set of a question into smaller, extra manageable chunks, typically within the type of ‘pages’ of knowledge that’s offered one ‘web page’ at a time. The first purpose to separate up the result-set is to reduce the information dimension so it’s simpler to handle. We’ve seen that the majority of our buyer’s shopper apps can’t deal with greater than 100MiB at a time so that they want a strategy to break it up.
Let’s stroll via the instance of displaying participant’s rank on a gaming leaderboard like this one:

picture supply: https://pngtree.com/freepng/game-leaderboard-design_6064125.html
It’s doubtless that pagination was used within the background, particularly if there’s a lengthy checklist of gamers collaborating within the sport. The question would possibly ask for the primary few pages of all prime gamers, so gamers can view their rating in comparison with the opposite prime gamers. Or one other question may very well be to ask for a listing of the gamers ranked instantly above and beneath a sure participant, say all 250 above and 250 beneath.
Every of those queries requires fairly a little bit of computation energy since not solely are you querying stay rating information, which continuously modifications in real-time, additionally, you will be querying all profile information in regards to the gamers. That would imply retrieving numerous information. Whereas Rockset has already carried out pagination utilizing Restrict-Offset, this methodology not solely can take a very long time however can be useful resource heavy as a result of Restrict-Offset methodology recomputes the complete information set each time you request a special subset of the general information.
Why did we construct a brand new strategy to paginate?
Rockset gives real-time analytics so some might imagine that pagination isn’t a problem. In spite of everything, for those who care about real-time information, you most likely wouldn’t be fascinating in stale information that outcomes from pagination. But, Rockset has a number of prospects who’ve requested for pagination as a result of their result-set information dimension was too large to handle they usually wished a way of coping with smaller information sizes. As a result of Restrict-Offset requires Rockset to compute the complete question for each subset of the outcome, it may be difficult with a big result-set.
Listed here are some actual examples from our prospects that spotlight these challenges:
- Giant Knowledge Export: A safety analytics firm permits its prospects to affix information the corporate collected with proprietary information the purchasers uploaded themselves. In flip, they supply the potential for purchasers to obtain the mixed information. The dimensions of the export typically exceeded the shopper’s 100MiB restrict. They want a strategy to parse this information into smaller chunks.
- Giant Search: A job market firm should shortly show job search outcomes over a number of pages, however the outcomes had been typically too massive, crashing their shopper. They want a strategy to paginate the information and solely obtain the subset of outcomes.
As you possibly can see, Restrict-Offset has two most important points: Sluggish queries and inconsistent outcomes.
Contemplate operating the beneath question to tug the highest scores between customers ranked 1,000,000 to 1,000,100:
Choose * from customers order by rating restrict 100 offset 1000000
- Sluggish Queries. With such a big Offset worth (1,000,000 on this instance), the latency can be unacceptably gradual as a result of Rockset might want to scan via the complete million paperwork every time the web page masses the subsequent 100 outcome web page. Although the person solely needs to see the outcomes for 100 customers, the question would want to run via all million customers and would rerun this again and again for every subsequent web page. That is grossly inefficient.
- Inconsistent Outcomes. Restrict-Offset queries are run one after one other, in a serialized method. So the primary 100 outcomes could be based mostly on information at one time limit and the subsequent 100 outcomes could be based mostly on information at a special time limit shortly sooner or later. This can lead to inconsistent evaluation. Because the information is collected in real-time, the information might need modified between the primary and second queries so outcomes could be inaccurate.
What’s our new pagination methodology?
With these two challenges in thoughts, our engineering staff labored arduous to implement a brand new strategy to paginate via a big outcome set. To be able to present consistency and pace for these queries, the staff moved to a cursor-based method for pagination as an alternative of the Restrict-Offset methodology. With a cursor-based method, Rockset queries all the information as soon as then as an alternative of sending the outcomes all to the client’s shopper, Rockset shops it quickly in non permanent storage. Now, because the shopper queries for a subset of knowledge, Rockset solely sends that subset. This removes the necessity to run the question on all information each time you want a subset of it.
To get extra detailed, the response from calling the question endpoint would come with the preliminary result-set (aka the primary web page), the entire variety of paperwork, the variety of paperwork within the present web page, a begin cursor, and a subsequent cursor which permits our customers to retrieve the subsequent set of paperwork following the preliminary result-set.
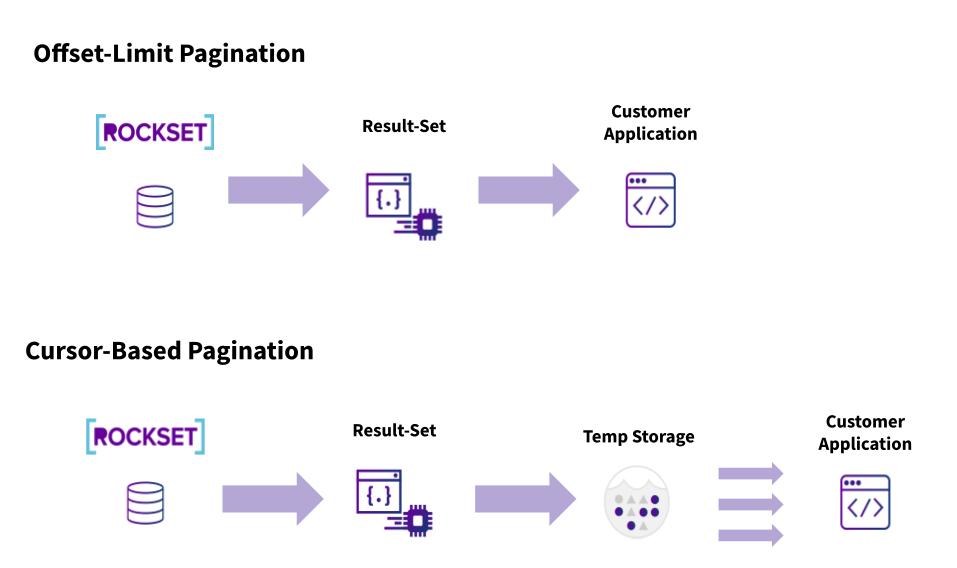
From this level onwards, the person can resolve tips on how to web page via the outcomes. They could be the identical dimension, smaller, or greater. If the subsequent cursor is null, it means the final set of outcomes was retrieved for this paginated question.
The outcome set will keep in non permanent storage for sufficient time to retrieve all the outcomes, a number of occasions. To verify if the outcome set remains to be accessible, the checklist of obtainable paginated queries, together with their begin cursor, could be retrieved via the queries endpoint.
Let’s see how pagination solved the above use-cases:
- Giant Knowledge Export: The safety analytics firm who was operating into points exporting massive quantities of buyer information without delay can now simply use the brand new cursor-based pagination and write the outcomes to a file one web page at a time
- Giant Search: The job market firm attempting to return a big outcome set for a search question can now use the cursor-based pagination to let customers flick thru a number of pages of the outcomes while not having to run the search question, time and again, additionally guaranteeing the outcomes will keep constant
Begin utilizing the brand new method to pagination in the present day!
In conclusion, although Rockset’s earlier methodology of pagination via Restrict-Offset was sufficient for many of our prospects, we wished to enhance the expertise for these with specialised wants so we carried out the cursor-based method to pagination. This brings a number of advantages:
- Cut back Processing Wants: By querying solely as soon as to get all of the outcome set saved in non permanent storage, Rockset can now pull completely different subsets with out repeatedly recomputing the question
- Improved Latency for Giant Outcome-Units: Whereas the preliminary question would possibly take longer to course of, the next requests to tug pages out of the paginated question endpoint could be very quick
- Constant Knowledge: Outcomes don’t change with each new question because the information is pulled solely as soon as and saved as quickly because the question finishes processing.
We’re very excited to have you ever strive it out! If you’re , please fill out the request kind right here.