
{kind=link}
Introduction
Google says that BERT is a significant step ahead, one of many greatest enhancements within the historical past of Search. It helps Google perceive what persons are searching for extra precisely. Visible BERT mastery is particular as a result of it will probably perceive phrases in a sentence by wanting on the phrases earlier than and after them. This helps it perceive the which means of sentences higher. It’s like after we perceive a sentence by contemplating all its phrases.

BERT helps computer systems perceive the which means of textual content in numerous conditions. For instance, it will probably assist classify textual content, perceive folks’s emotions in a message, reply recognised questions, and the names of issues or folks. Utilizing BERT in Google Search reveals how language fashions have come a great distance and make our interactions with computer systems extra pure and useful.
Studying Targets
- Be taught what BERT stands for (Bidirectional Encoder Representations from Transformers).
- Data of how BERT is skilled on a considerable amount of textual content information.
- Perceive the idea of pre-training and the way it helps BERT develop language understanding.
- Acknowledge that BERT considers each the left and proper contexts of phrases in a sentence.
- Use BERT in search engines like google and yahoo to know consumer queries higher.
- Discover the masked language mannequin and subsequent sentence prediction duties utilized in BERT’s coaching.
This text was revealed as part of the Knowledge Science Blogathon.
What’s Bert?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a particular laptop mannequin that helps computer systems perceive and course of human language. It’s an clever device that may learn and perceive textual content like ours.
What makes BERT particular is that it will probably perceive the which means of phrases in a sentence by wanting on the phrases earlier than and after them. It’s like studying a sentence and understanding what it means by contemplating all of the phrases collectively.

BERT is skilled utilizing textual content from books, articles, and web sites. This helps it study patterns and connections between phrases. So, after we give BERT a sentence, it will probably determine the which means and context of every phrase primarily based on its coaching.
This highly effective skill of BERT to know language is utilized in many various methods. It could possibly additionally assist with duties like classifying textual content, understanding the sentiment or emotion in a message, and answering questions.
SST2 Dataset
Dataset Hyperlink: https://github.com/clairett/pytorch-sentiment-classification/tree/grasp/information/SST2
On this article, we’ll use the above dataset, which consists of sentences extracted from film critiques. The worth 1 represents a optimistic label, and the 0 represents a damaging label for every sentence.

By coaching a mannequin on this dataset, we will educate the mannequin to categorise new sentences as optimistic or damaging primarily based on the patterns it learns from the labeled information.
Fashions: Sentence Sentiment Classification
We intention to create a sentiment evaluation mannequin to categorise sentences as optimistic or damaging.
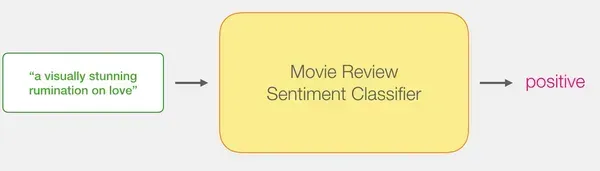

By combining the ability of DistilBERT’s sentence processing capabilities with the classification talents of logistic regression, we will construct an environment friendly and correct sentiment evaluation mannequin.

Generate Sentence Embeddings with DistilBERT: Make the most of the pre-trained DistilBERT mannequin to generate sentence embeddings for two,000 sentences.

These sentence embeddings seize vital details about the which means and context of the sentences.
Carry out Practice/Check Break up: Break up the dataset into coaching and check units.

Use the coaching set to coach the logistic regression mannequin, whereas the check set can be for analysis.
Practice the Logistic Regression Mannequin: Make the most of the coaching set to coach the logistic regression mannequin utilizing scikit-learn.

The logistic regression mannequin learns to categorise the sentences as optimistic or damaging primarily based on the sentence embeddings.
By following this plan, we will leverage the ability of DistilBERT to generate informative sentence embeddings after which practice a logistic regression mannequin to carry out sentiment classification. The analysis step permits us to evaluate the mannequin’s efficiency in predicting the sentiment of latest sentences.
How A Single Prediction is Calculated?
Right here’s an evidence of how a skilled mannequin calculates its prediction utilizing the instance sentence “a visually gorgeous rumination on love”:
Tokenization: Every phrase within the phrase is split into smaller parts often called tokens. The tokenizer moreover inserts particular tokens resembling ‘CLS’ firstly and ‘SEP’ on the finish.

Token to ID Conversion: The tokenizer then replaces every token with its corresponding ID from the embedding desk. The embedding desk is a element that comes with the skilled mannequin and maps tokens to their numerical representations.
The form of Enter: After tokenizing and changing, DistilBERT transforms the enter sentence into the right form for processing. It represents the sentence as a sequence of token IDs with the addition of distinctive tokens.

Be aware which you can carry out all these steps, together with tokenization and ID conversion, utilizing a single line of code with the tokenizer offered by the library.

Flowing Via DistilBERT
Certainly, passing the enter vector via DistilBERT follows the same course of as with BERT. The output would encompass a vector for every enter token, the place every vector incorporates 768 numbers (floats).

Within the case of sentence classification, we focus solely on the primary vector, which corresponds to the [CLS] token. The [CLS] token is designed to seize the general context of the whole sequence, so utilizing solely the primary vector (the [CLS] token) for sentence classification in fashions like BERT works. The situation of this token, its operate in pre-training, and the pooling approach all contribute to its capability to encode vital info for classification duties. Moreover, using solely the [CLS] token reduces computational complexity and reminiscence necessities whereas permitting the mannequin to make correct predictions for a variety of classification duties. This vector is handed because the enter to the logistic regression mannequin.
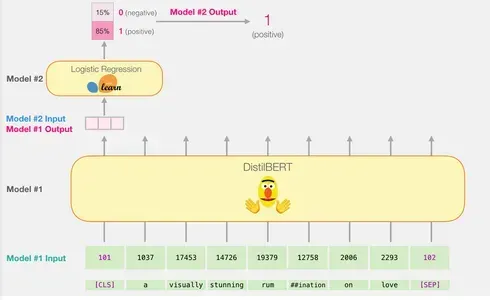
The logistic regression mannequin’s position is to categorise this vector primarily based on what it realized throughout its coaching part. We will envision the prediction calculation as follows:
- The logistic regression mannequin takes the enter vector (related to the [CLS] token) as its enter.
- It applies a set of realized weights to every of the 768 numbers within the vector.
- The weighted numbers are summed, and a further bias time period is added.
Lastly, the summation result’s handed via a sigmoid operate to supply the prediction rating.

The coaching part of the logistic regression mannequin and the entire code for the whole course of can be mentioned within the subsequent part.
Implementation From Scratch
This part will spotlight the code to coach this sentence classification mannequin.
Load the Library
Let’s begin by importing the instruments of the commerce. We will use df.head() to have a look at the primary 5 rows of the dataframe to see how the information seems to be.

Importing Pre-trained DistilBERT Mannequin and Tokenizer
We’ll tokenize the dataset however with a slight distinction from the earlier instance. As an alternative of tokenizing and processing one sentence at a time, we’ll course of all of the sentences collectively as a batch.
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer,
'distilbert-base-uncased')
## Need BERT as an alternative of distilBERT?
##Uncomment the next line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer,
'bert-base-uncased')
# Load pre-trained mannequin/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
mannequin = model_class.from_pretrained(pretrained_weights)
For instance, let’s say now we have a dataset of film critiques, and we wish to tokenize and course of 2,000 critiques concurrently. We’ll use a tokenizer known as DistilBertTokenizer, a device particularly designed for tokenizing textual content utilizing the DistilBERT mannequin.
The tokenizer takes the whole batch of sentences and performs tokenization, which entails splitting the sentences into smaller items known as tokens. It additionally provides particular tokens, like [CLS] originally and [SEP] on the finish of every sentence.
Tokenization
Consequently, every sentence turns into a listing of ids. The dataset consists of a listing of lists (or a pandas Sequence/DataFrame). Shorter phrases should be padded with the token id 0 to make all of the vectors the identical size. Now now we have a matrix/tensor that may be offered to BERT after the padding:
tokenized = df[0].apply((lambda x: tokenizer.
encode(x, add_special_tokens=True)))

Processing with DistilBERT
The padded token matrix is now become an enter tensor, which we undergo DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = mannequin(input_ids)
The outputs of DistilBERT are saved in last_hidden_states after finishing this step. Since we solely thought-about 2000 situations, in our state of affairs, this can be 2000 (the variety of tokens within the longest sequence from the 2000 examples) and 768 (the variety of hidden items within the DistilBERT mannequin).
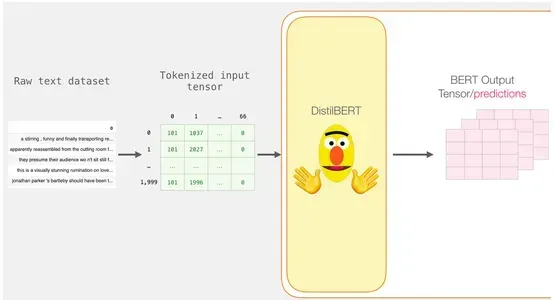
Unpacking the BERT Output Tensor
Let’s examine the 3D output tensor’s dimensions and extract it. Assuming you’ve gotten the last_hidden_states variable, which incorporates the DistilBERT output tensor.
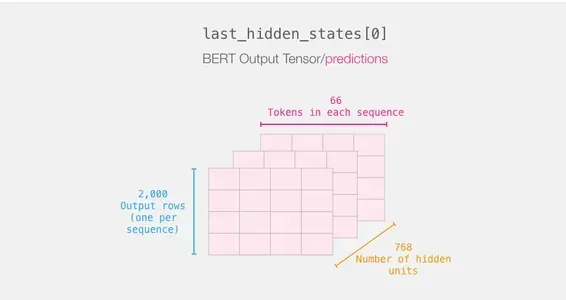
Recapping a Sentence’s Journey
Every row has a textual content from our dataset connected to it. To assessment the primary sentence’s processing circulate, image it as follows:

Slicing the Necessary Half
We solely select that slice of the dice for sentence categorization since we’re solely fascinated with BERT’s end result for the [CLS] token.

To acquire the second tensor we’re fascinated with from that 3d tensor, we slice it as follows:
# Slice the output for the primary place for all of the sequences, take all hidden unit outputs
options = last_hidden_states[0][:,0,:].numpy()Lastly, the characteristic is a second numpy array that features all the sentences’ sentence embeddings from our dataset.

Apply Logistic Regression
We’ve the dataset wanted to coach our logistic regression mannequin now that now we have the output of BERT. The 768 columns in our first dataset comprise the traits and labels.

We could outline and practice our Logistic Regression mannequin on the dataset after doing the traditional practice/check cut up of machine studying.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(options, labels)
Utilizing this, the dataset is split into coaching and check units:

The Logistic Regression mannequin is then skilled utilizing the coaching set.
lr_clf = LogisticRegression()
lr_clf.match(train_features, train_labels)
After the mannequin has been skilled, we could evaluate its outcomes to the check set:
lr_clf.rating(test_features, test_labels)Which provides the mannequin an accuracy of about 81%.
Conclusion
In conclusion, BERT is a robust language mannequin that helps computer systems perceive human language higher. By contemplating the context of phrases and coaching on huge quantities of textual content information, BERT can seize which means and enhance language understanding.
Key Takeaways
- BERT is a language mannequin that helps computer systems perceive human language higher.
- It considers the context of phrases in a sentence, making it smarter in understanding which means.
- BERT is skilled on plenty of textual content information to study language patterns.
- It may be fine-tuned for particular duties like textual content classification or query answering.
- BERT improves search outcomes and language understanding in purposes.
- It handles unfamiliar phrases by breaking them into smaller elements.
- TensorFlow and PyTorch are used with BERT.
BERT has improved purposes like search engines like google and yahoo and textual content classification, making them smarter and extra useful. Total, BERT is a major step in making computer systems perceive human language extra successfully.
Ceaselessly Requested Questions
A1: BERT can be utilized for varied language-related duties, together with classifying textual content, understanding sentiment or emotion, answering questions, and recognizing named entities.
A2: BERT is utilized in Google Search to know consumer queries higher and supply extra related search outcomes. It’s additionally employed in different purposes to reinforce language understanding and pure language processing duties.
A3: Tokenization entails breaking down sentences into smaller items known as tokens. Every token is then transformed to its corresponding numerical ID utilizing an embedding desk. Particular tokens like [CLS] (begin) and [SEP] (finish) are additionally added.
A4: DistilBERT generates sentence embeddings by processing tokenized sentences via its mannequin. The embedding equivalent to the [CLS] token is used because the sentence embedding, capturing the sentence’s general which means.
A5: Logistic regression is used to categorise the sentence embeddings generated by DistilBERT as both optimistic or damaging sentiment. It applies realized weights to the embeddings, sums them up, provides a bias time period, and passes the end result via a sigmoid operate to supply a prediction rating.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.