

{kind=link}
There may be quite a lot of confusion about how search engine optimisation professionals ought to each perceive and, extra importantly, leverage “entities” in search engine optimisation.
I perceive the place this comes from, particularly with the standard method to search engine optimisation being round phrases and phrases.
Certainly, many of the algorithms that the primary wave of search engine optimisation professionals (like me) grew up with had no idea of an “entity” in search. search engine optimisation principals – from content material writing to anchor textual content in hyperlinks to SERPs monitoring – have been (and largely nonetheless are) keyword-driven, and many individuals nonetheless discover it exhausting to grasp what has modified.
However during the last decade, all search has been shifting in the direction of understanding the world as a string of phrases and as a collection of interconnected entities.
Working with entities in search engine optimisation is the inspiration for a future-proof search technique.
They’re additionally vital for a future with generative AI and ChatGPT.
This text talks about why. It covers:
- What are entities?
- What’s the Information Graph?
- A quick historical past of entities in search: Freebase, Wikidata, and entities.
- How entities work and the way they’re used for rating.
- Examples of entities in Google.
- Learn how to optimize for entities.
- Utilizing Schema to assist outline entities.
What Are Entities?
SEOs typically confuse entities with key phrases.
An entity (in search phrases) is a report in a database. An entity usually has a selected report establish.
In Google, that is perhaps:
“MREID=/m/23456” or “KGMID=/g/121y50m4.”
It’s definitely not a “phrase” or “phrase.” I consider that the confusion with key phrases stems from two root causes:
- The primary is that search engine optimisation professionals realized their craft pre-2010 when it comes to key phrases and phrases. Many nonetheless do.
- The second is that each entity comes with a label – which is usually a key phrase or descriptor.
So whereas “Eiffel Tower” may look like a wonderfully identifiable “entity” to us as people, Google sees it as “KGMID=/m/02j81” and actually doesn’t care if you happen to name it “Eiffel Tower,” or “ Torre Eiffel,” or “ایفل بورجو” (Which is Azerbaijan for “Eiffel Tower”). It is aware of that you’re in all probability referring to that underlying entity in its Information Graph.
This comes on to the following level:
What Is “The Information Graph”?
There are delicate however vital variations between “a data graph,” “The Information Graph,” and “The Information Panel.”
- A data graph is a semi-structured database containing entities.
- The Information Graph is usually the title given to Google’s Information Graph, though hundreds of others exist. Wikidata (itself a data graph) makes an attempt to cross-reference identifiers from totally different respected information sources.
- The Information Panel is a selected illustration of outcomes from Google’s Information Graph. It’s the pane typically displaying on the best of the outcomes (SERPs) in a desktop search, giving extra particulars about an individual, place, occasion, or different entity.
A Transient Historical past Of Entities In Search
Metaweb
In 2005, Metaweb began to construct out a database, then referred to as Freebase, which it described as an “open, shared database of the world’s data.”
I’d describe it as a semi-structured encyclopedia.
It gave each “entity” (or article, to increase the metaphor) its personal distinctive ID quantity – and from there, as a substitute of a standard article in phrases, the system tried to attach articles by way of their relationships with different ID numbers within the system.
Some $50 million {dollars} in capital funding, and 5 years later, the undertaking was bought to Google.
No business product was ever constructed, however the basis was set for a 10-year transition, for Google, from a keyword-based search engine to an entity-based one.
Wikidata
In 2016 – some six years after the acquisition – Google formally closed down Freebase as a result of it had migrated and developed the concepts into its personal “data graph,” the trendy time period for these databases.
At the moment, it’s helpful to notice that Google publicly said that it had synced a lot of its entity information with Wikidata and that, shifting ahead, Wikidata (which underpins the information utilized in Wikipedia) was a technique during which Google’s Information Graph might interface with the surface world.
How Entities Work And How They Are Used For Rating
Entities In The Core Algorithm
Entities are primarily used to disambiguate concepts, to not rank pages with the identical concepts.
That isn’t to say that intelligent use of entities can’t assist your web site’s content material rank extra successfully. It may. However when Google tries to serve up outcomes to a consumer search, it goals before everything for an correct reply.
Not essentially probably the most deserving.
Subsequently, Google spends appreciable time changing textual content passages into underlying entities. This occurs each when indexing your web site and when analyzing a consumer question.
For instance, if I sort in “The names of the eating places beneath the Eiffel Tower,” Google is aware of that the searcher just isn’t searching for “names” or the “Eiffel Tower.”
They’re searching for eating places. Not any restaurant, however ones in a selected location. The 2 related entities on this search are “restaurant” within the context of “Champ de Mars, 5 Av. Anatole France, Paris” (The deal with of the Eiffel Tower).
This helps Google to determine how one can mix its varied search outcomes – photographs, Maps, Google companies, adverts, and natural internet pages, to call just a few.
Most significantly, for the search engine optimisation professional, it is rather vital for (say) the Jules Verne restaurant’s web site to speak about its spectacular view of the Eiffel Tower if it needs Google to acknowledge that the web page is related to this search question.
This is perhaps tough for the reason that Jules Verne restaurant is contained in the Eiffel Tower.
Language Agnostic
Entities are nice for search engines like google as a result of they’re language-agnostic. Furthermore, that concept signifies that an entity could be described by way of a number of media.
A picture can be an apparent strategy to describe the Eiffel Tower since it’s so iconic. It may also be a speech file or the official web page for the tower.
These all symbolize legitimate labels for the entity and, in some circumstances, legitimate identifiers in different data graphs.
Connections Between Entities
The interaction between entities permits an search engine optimisation professional to develop coherent methods for creating related natural visitors.
Naturally, probably the most “authoritative” web page for the Eiffel Tower is more likely to be the official web page or Wikipedia. Except you might be actually the search engine optimisation professional for the Eiffel Tower, there may be little that you are able to do to problem this reality.
Nonetheless, the interaction between entities means that you can write content material that may rank. We already talked about “eating places” and “Eiffel Tower” – however what about “Metro” and “Eiffel Tower,” or “Reductions” and “Eiffel Tower”?
As quickly as two entities come into play, the variety of related search outcomes drops dramatically. By the point you get to “Discounted Eiffel Tower tickets whenever you journey by Metro,” you turn out to be certainly one of only a tiny choice of pages specializing in the juxtaposition between Metro tickets, Eiffel Tower tickets, and reductions.
Many fewer folks sort on this phrase, however the conversion charge might be a lot greater.
It might additionally show a extra monetizable idea for you! (This instance is to clarify the precept. I have no idea if such reductions exist. However they need to.)
This idea could be scaled to create exceptionally robust pages by first breaking all of the competing pages for a search term right into a desk displaying the underlying entities and their relative significance to the primary question.
This may then act as a content material plan for a author to construct up a brand new piece of content material that’s extra authoritative than any of the opposite competing items.
So though a search engine could declare that entities should not a rating issue, the technique goes to the guts of the philosophy that “Should you write good content material, they’ll come.”
Examples Of Entities In Google
Entities In Picture Search
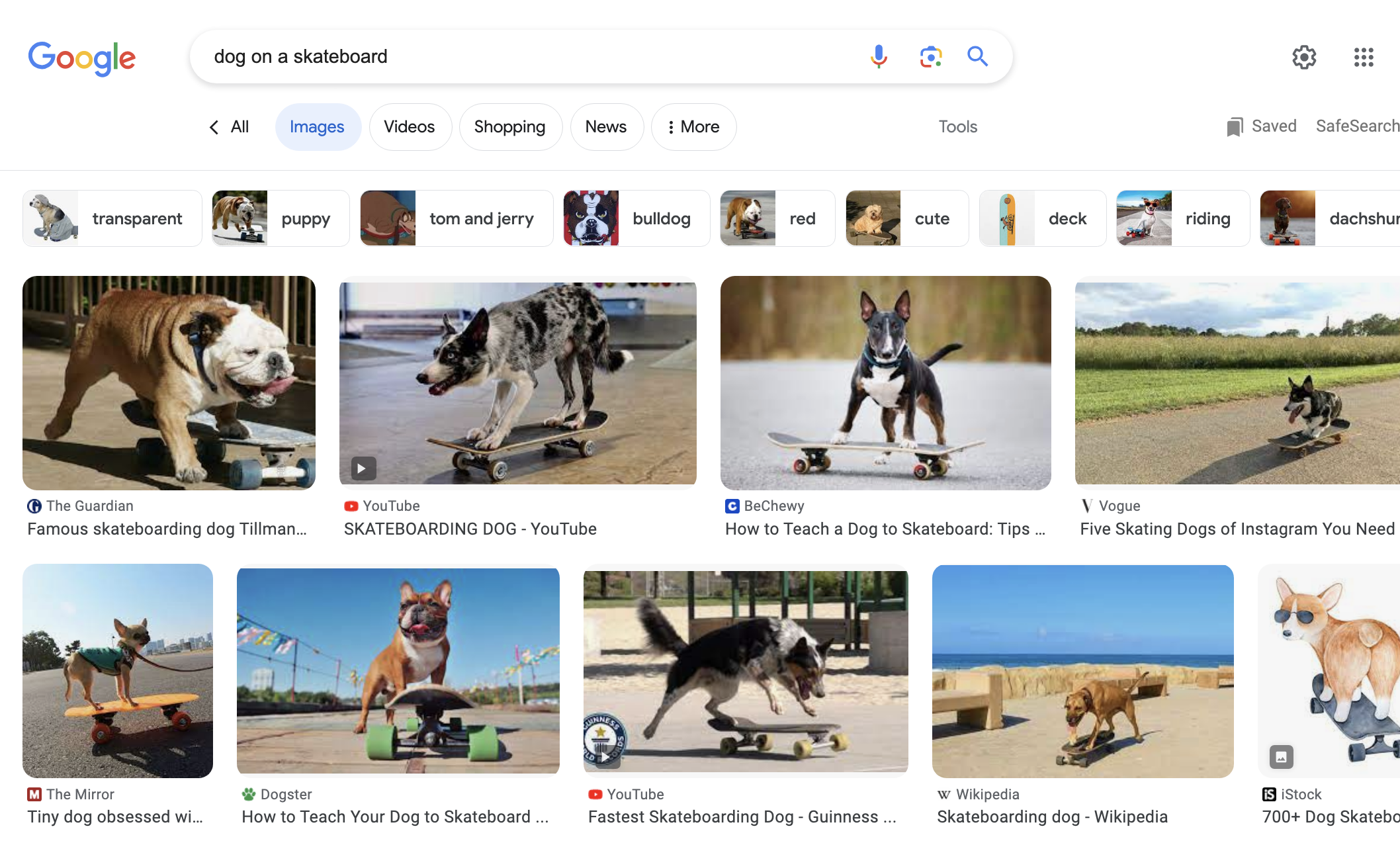 Screenshot from seek for [dog on a skateboard], Google, August 2023
Screenshot from seek for [dog on a skateboard], Google, August 2023Entities can be very useful in optimizing photographs.
Google has labored very exhausting to investigate photographs utilizing machine studying. So usually, Google is aware of the primary imagery in most images.
So take [a dog on a skateboard] as a search time period…ensuring that your content material absolutely helps the picture will help your content material be extra seen, simply when the consumer is looking for it.
Entities In Google Uncover
One of the underrated visitors sources for search engine optimisation professionals is Google Uncover.
Google gives a feed of fascinating pages for customers, even when they aren’t actively searching for one thing.
This occurs on Android telephones and likewise within the Google app on iPhones. While information closely influences this feed, non-news websites can get visitors from “Uncover.”
How? Nicely – I consider that entities play an enormous issue!
 Screenshot from Google Search Console, August 2023
Screenshot from Google Search Console, August 2023Don’t be disheartened if you don’t see a “Uncover” tab in your Google Search Console. However whenever you do, it may be a welcome signal that a minimum of certainly one of your internet pages has aligned with entities sufficient that a minimum of one particular person’s pursuits overlap together with your content material sufficient to have the web page in a feed focused particularly to the consumer.
Within the instance above, regardless that “Uncover” outcomes should not displayed on the actual time {that a} consumer is looking out, there may be nonetheless a 4.2% click-through charge.
It is because Google can align the pursuits and habits of a lot of its customers to the content material on the Web by mapping entities.
The place a robust correlation happens, Google can provide up a web page for a consumer.
How To Optimize For Entities
Some Analysis From A Googler
In 2014, a paper got here out that I discover fairly useful in demonstrating that Google (or a minimum of, its researchers) have been eager to separate out the concepts of utilizing key phrases to grasp matters vs. utilizing entities.
On this paper, Dunietz and Gillick word how NLP programs moved in the direction of entity-based processing. They spotlight how a binary “salience” system can be utilized on giant information units to outline the entities in a doc (webpage).
A “binary scoring system” means that Google may determine {that a} doc both IS or ISN’T about any given entity.
Later clues recommend that “salience” is now measured by Google on a sliding scale from 0 to 1 (for instance, the scoring given in its NLP API).
Even so, I discover this paper actually useful in seeing the place Google’s analysis thinks “entities” ought to seem on a web page to “rely” as being salient.
I like to recommend studying the paper for critical analysis, however they checklist how they categorized “salience as a examine of ‘New York Instances’ articles.”
Particularly, they cited:
1st-loc
This was the primary sentence during which a point out of an entity first seems.
The suggestion is that mentioning the entity early in your internet web page may enhance the possibilities of an entity being seen as “salient” to the article.
Head-count
That is mainly the variety of instances the “head” phrase of the entity’s first point out seems.
“Head phrase” just isn’t particularly outlined within the article, however I take it to imply the phrase concatenated to its easiest kind.
Mentions
This refers not simply to the phrases/labels of the entity, but additionally to different components, akin to referrals of the entity (he/she/it)
Headline
The place when an entity seems in a headline.
Head-lex
Described because the “lowercased head phrase of the primary point out.”
Entity Centrality
The paper additionally talks about utilizing a variation of PageRank – the place they switched out internet pages for Freebase articles!
The instance they shared was a Senate ground debate involving FEMA, the Republican Celebration, (President) Obama, and a Republican senator.
After making use of a PageRank-like iterative algorithm to those entities and their proximity to one another within the data graph, they have been in a position to change the weightings of the significance of these entities within the doc.
Placing These Entity Indicators Collectively In search engine optimisation
With out being particular to Google, right here, an algorithm would create values for all of the above variables for each entity that an NLP or named entity extraction program (NEEP) finds on a web page of textual content (or, for that matter, all of the entities acknowledged in a picture).
Then a weighting can be utilized to every variable to provide a rating. Within the paper mentioned, this rating turns right into a 1 or 0 (salient or not salient), however a worth from 0-1 is extra doubtless.
Google won’t ever share the small print of these weightings, however what the paper additionally exhibits is that the weightings are decided solely after a whole bunch of hundreds of thousands of pages are “learn.”
That is the character of enormous language studying fashions.
However listed here are some high suggestions for search engine optimisation professionals who need to rank content material round two or extra entities. Returning to the instance “eating places close to the Eiffel Tower”:
- Determine on a “useless” time period for every entity. I would select “restaurant,” “Eiffel Tower,” and “distance” as a result of distance has a sound that means and article in Wikipedia. Cafe is perhaps an acceptable synonym for restaurant, as may “eating places” within the plural.
- Goal to have all three entities within the header and first sentence. For instance: “Eating places a small distance from the Eiffel Tower.”
- Goal within the textual content to speak in regards to the inter-relationship between these entities. For instance: “The Jules-Verne restaurant is actually inside it.” Assuming “it” clearly refers back to the Eiffel Tower within the context of the writing, it doesn’t should be written out each time. Maintain the language pure.
Is This Sufficient For Entity search engine optimisation?
No. Most likely not. (You’re welcome to learn my e book!) Nonetheless, not all components are in your management as a author or web site proprietor.
Two concepts that do appear to have an influence, although, are linking content material from different pages in context and including schema to assist with the definitions.
Utilizing Schema To Assist Outline Entities
Additional readability is perhaps given to search engines like google through the use of the “about” and “mentions” schema to assist a search engine disambiguate content material.
These two schema sorts assist to explain what a web page is speaking about.
By making a web page “about” one or two entities and “mentions” of possibly just a few extra, an search engine optimisation skilled can rapidly summarize a protracted piece of content material into its key areas in a manner that’s ready-made for data graphs to eat.
It must be famous, although, that Google has not expressly said a technique or one other whether or not it makes use of this schema in its core algorithms.
I’d in all probability add this schema to my article:
<script sort=”software/ld+json”> {
“@context”: “https://schema.org”,
“@sort”: “WebPage”,
“@id”: “https://www.yoursite.com/yourURL#ContentSchema”,
“headline”: “Eating places a small distance from the Eiffel Tower”,
“url”: “https://www.yoursite.com/yourURL”,
“about”: [
{“@type”: “Thing”, “name”: “Restaurant”, “sameAs”: “https://en.wikipedia.org/wiki/Restaurant”},
{“@type”: “Place”, “name”: “Eiffel Tower”, “sameAs”: “https://en.wikipedia.org/wiki/Eiffel_Tower”}
],
“mentions”: [
{“@type”: “Thing”, “name”: “distance”, “sameAs”: “https://en.wikipedia.org/wiki/Distance”},
{“@type”: “Place”, “name”: “Paris”, “sameAs”: “https://en.wikipedia.org/wiki/Paris”}
]
} </script>
The precise alternative of schema is as a lot a philosophical query as an search engine optimisation query.
However consider the schema you employ as “disambiguating” your content material quite than “optimizing your content material,” and you’ll hopefully find yourself with extra focused search visitors.
Editor’s word: Dixon Jones is the writer of Entity search engine optimisation: Transferring from Strings to Issues.
Extra sources:
Featured Picture: optimarc/Shutterstock