

{kind=link}
We’re thrilled to announce nice enhancements to onboard extra workloads to Unity Catalog clusters in shared entry mode, Databricks’ extremely environment friendly, safe multi-user clusters. Knowledge groups can now develop and run SQL, Python and Scala workloads securely on shared compute sources. With that, Databricks is the one platform within the business providing fine-grained entry management on shared compute for Scala, Python and SQL Spark workloads.
Beginning with Databricks Runtime 13.3 LTS, you may seamlessly transfer your workloads to shared clusters, due to the next options which are out there on shared clusters:
- Cluster libraries and Init scripts: Streamline cluster setup by putting in cluster libraries and executing init scripts on startup, with enhanced safety and governance to outline who can set up what.
- Scala: Securely run multi-user Scala workloads alongside Python and SQL, with full person code isolation amongst concurrent customers and imposing Unity Catalog permissions.
- Python and Pandas UDFs. Execute Python and (scalar) Pandas UDFs securely, with full person code isolation amongst concurrent customers.
- Single-node Machine Studying: Run scikit-learn, XGBoost, prophet and different common ML libraries utilizing the Spark driver node,, and use MLflow for managing the end-to-end machine studying lifecycle.
- Structured Streaming: Develop real-time information processing and evaluation options utilizing structured streaming.
Cluster Entry Modes in Unity Catalog made simple(er)
When making a cluster to work with information ruled by Unity Catalog, you may select between two entry modes:
- Clusters in shared entry mode – or simply shared clusters – are the beneficial compute possibility for many workloads. Shared clusters enable any variety of customers to connect and concurrently execute workloads on the identical compute useful resource, permitting for vital price financial savings, simplified cluster administration and holistic information governance together with fine-grained entry management. That is achieved by Unity Catalog’s person workload isolation which runs any SQL, Python and Scala person code in full isolation with no entry to lower-level sources.
- Clusters in single person entry mode are beneficial for workloads requiring privileged machine entry or utilizing RDD APIs, distributed ML, GPUs, Databricks Container Service or R.
Whereas single-user clusters observe the normal Spark structure, the place person code runs on Spark with privileged entry to the underlying machine, shared clusters guarantee person isolation of that code. The determine under illustrates the structure and isolation primitives distinctive to shared clusters: Any client-side person code (Python, Scala) runs totally remoted and UDFs operating on Spark executors execute in remoted environments. With this structure, we will securely multiplex workloads on the identical compute sources and provide a collaborative, cost-efficient and safe answer on the similar time.
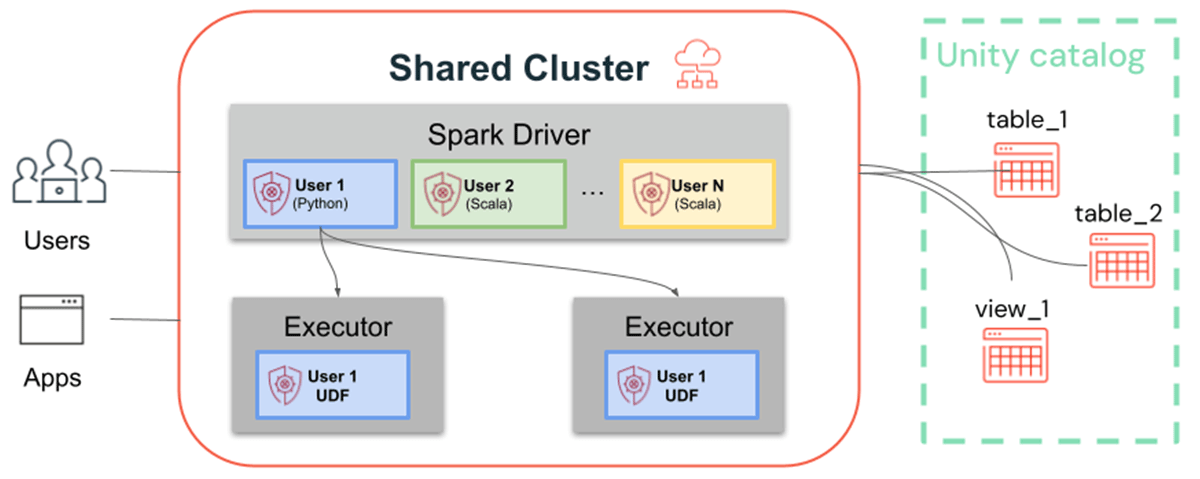
What’s New for Shared Clusters in Element
Configure your shared cluster utilizing cluster libraries & init scripts
Cluster libraries will let you seamlessly share and handle libraries for a cluster and even throughout a number of clusters, making certain constant variations and lowering the necessity for repetitive installations. Whether or not that you must incorporate machine studying frameworks, database connectors, or different important elements into your clusters, cluster libraries present a centralized and easy answer now out there on shared clusters.
Libraries could be put in from Unity Catalog volumes (AWS, Azure, GCP) , Workspace recordsdata (AWS, Azure, GCP), PyPI/Maven and cloud storage places, utilizing the prevailing Cluster UI or API.
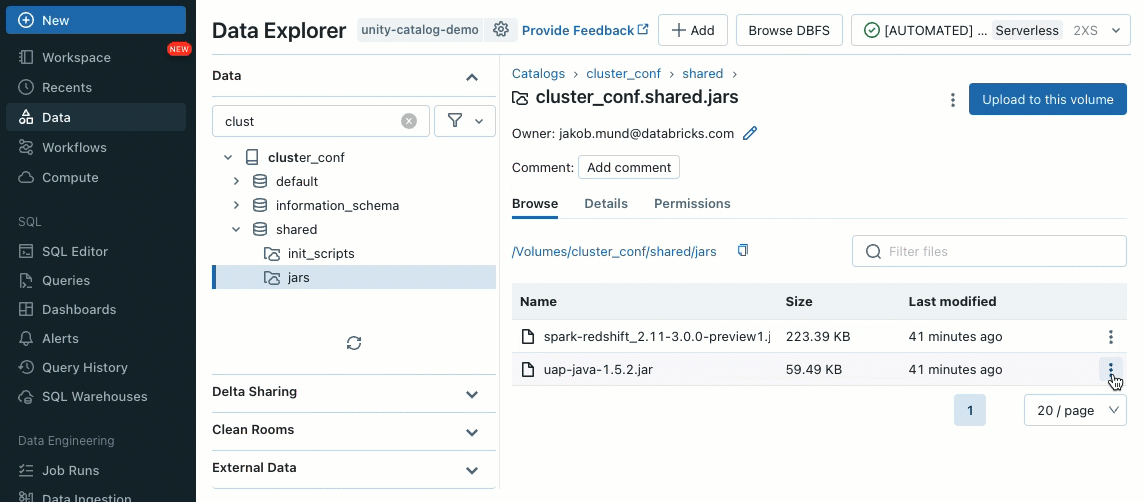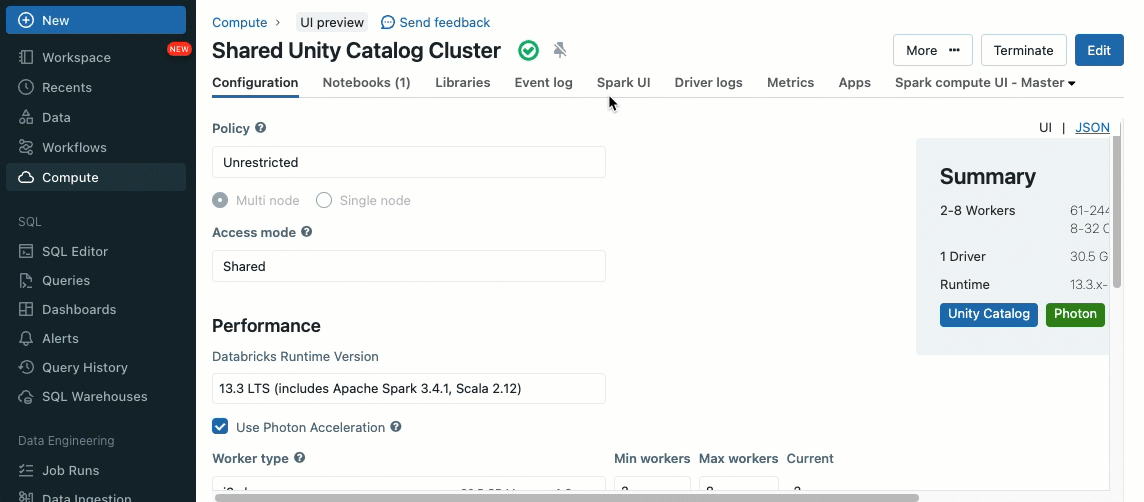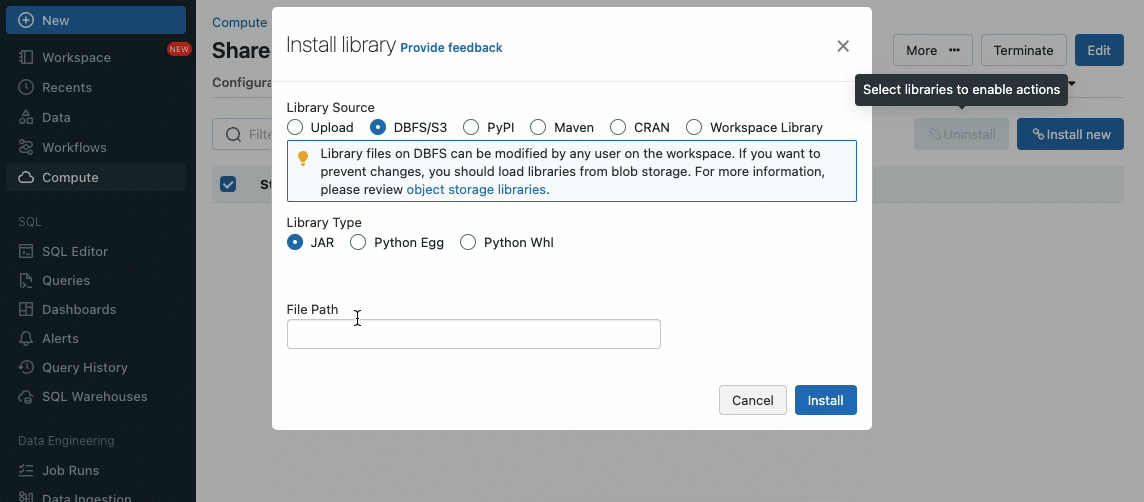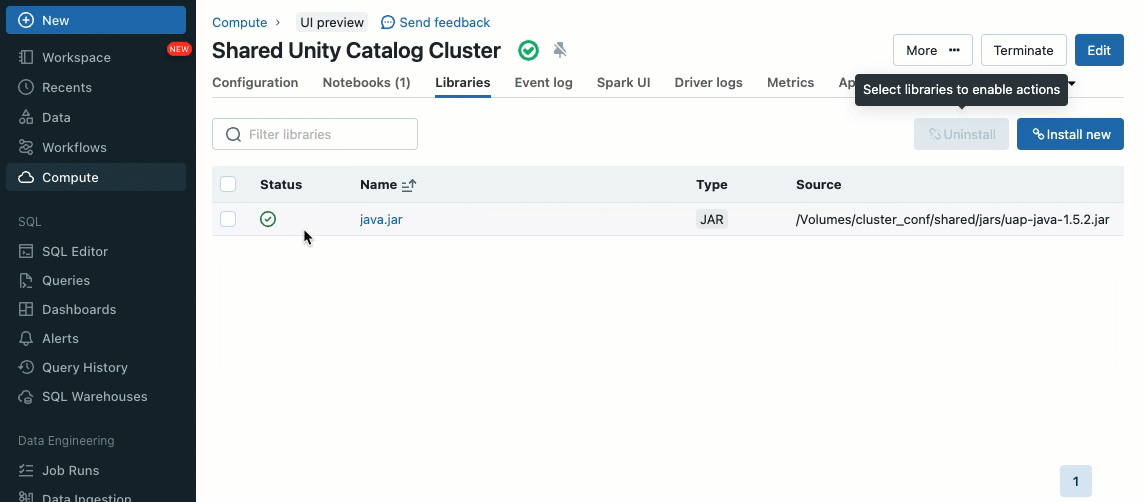
Utilizing init scripts, as a cluster administrator you may execute customized scripts in the course of the cluster creation course of to automate duties similar to establishing authentication mechanisms, configuring community settings, or initializing information sources.
Init scripts could be put in on shared clusters, both instantly throughout cluster creation or for a fleet of clusters utilizing cluster insurance policies (AWS, Azure, GCP). For optimum flexibility, you may select whether or not to make use of an init script from Unity Catalog volumes (AWS, Azure, GCP) or cloud storage.
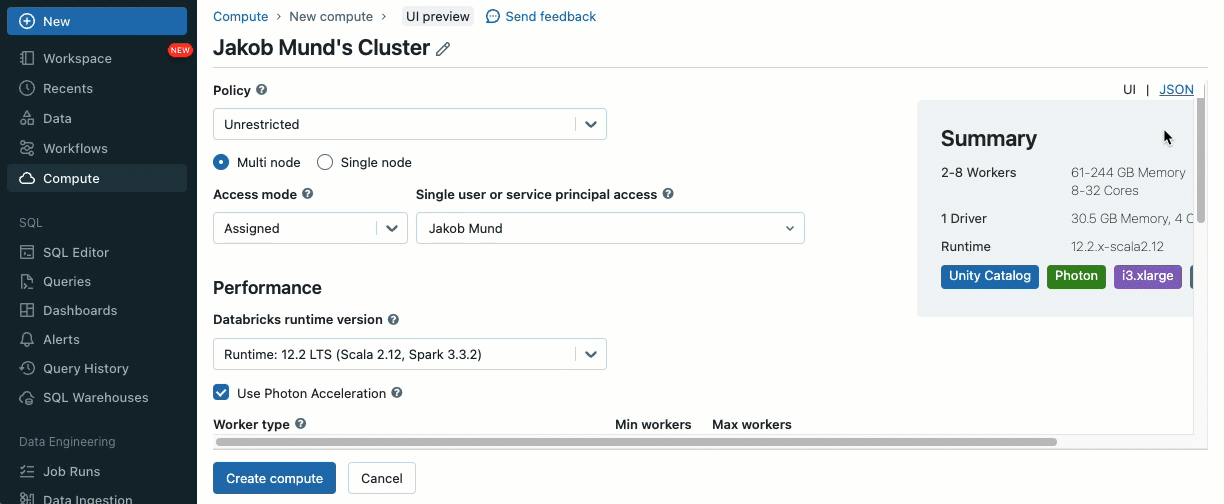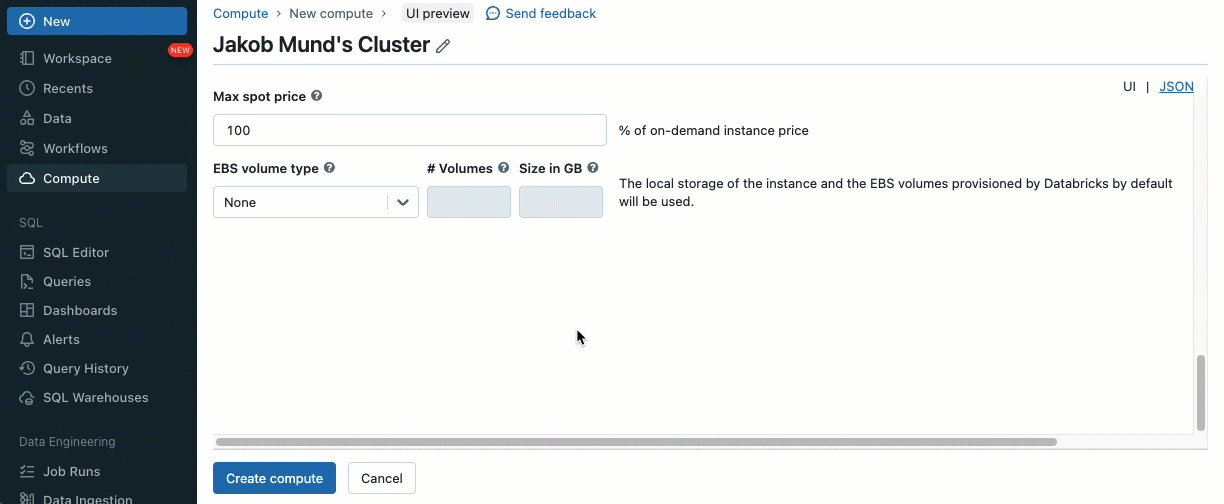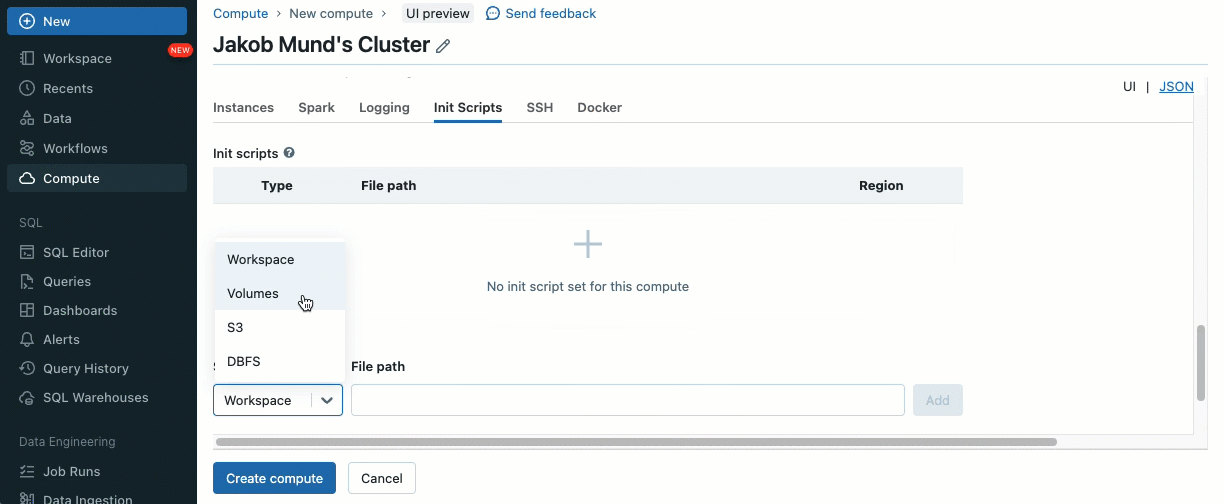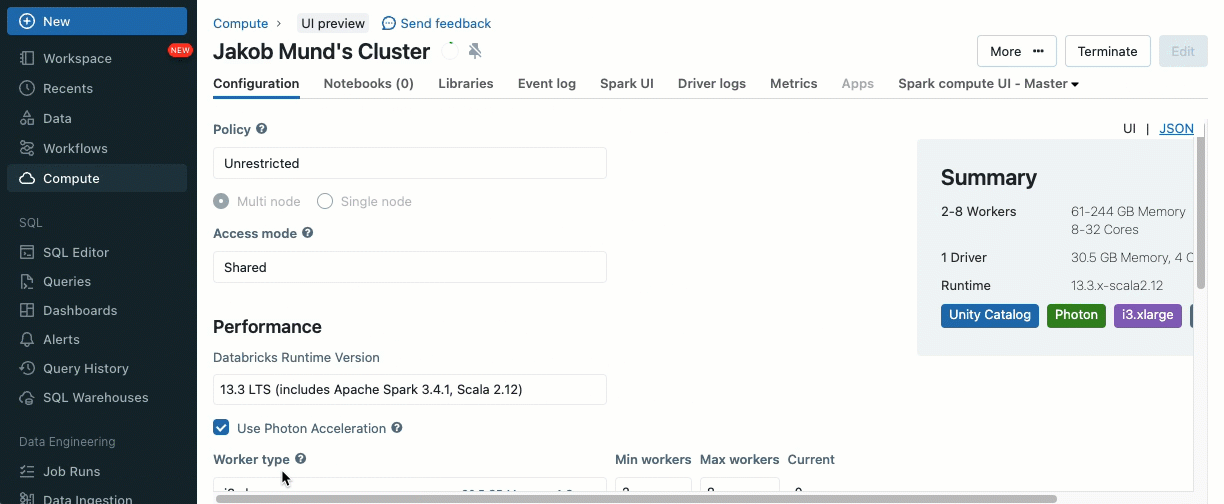
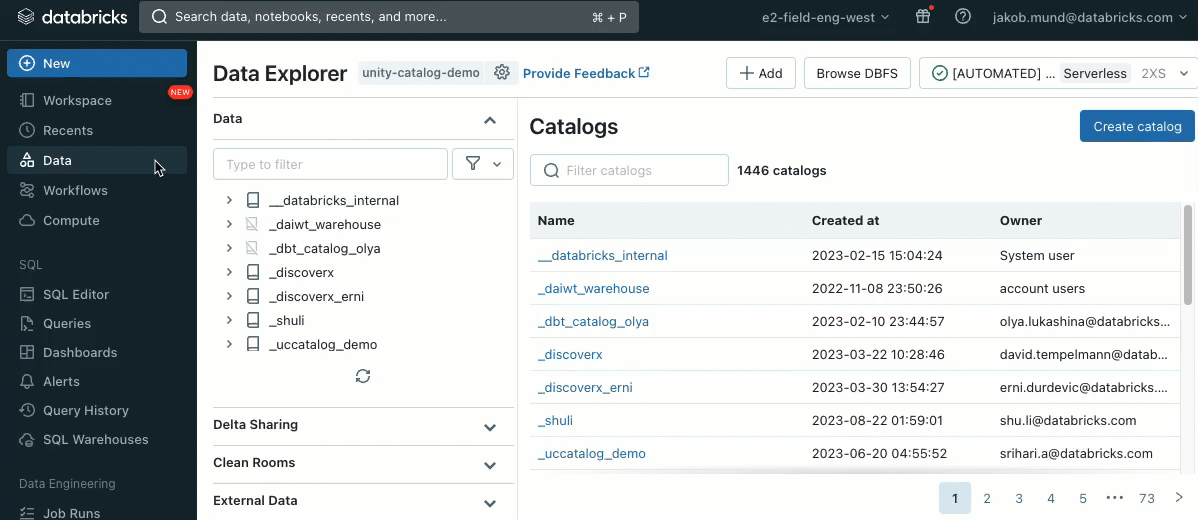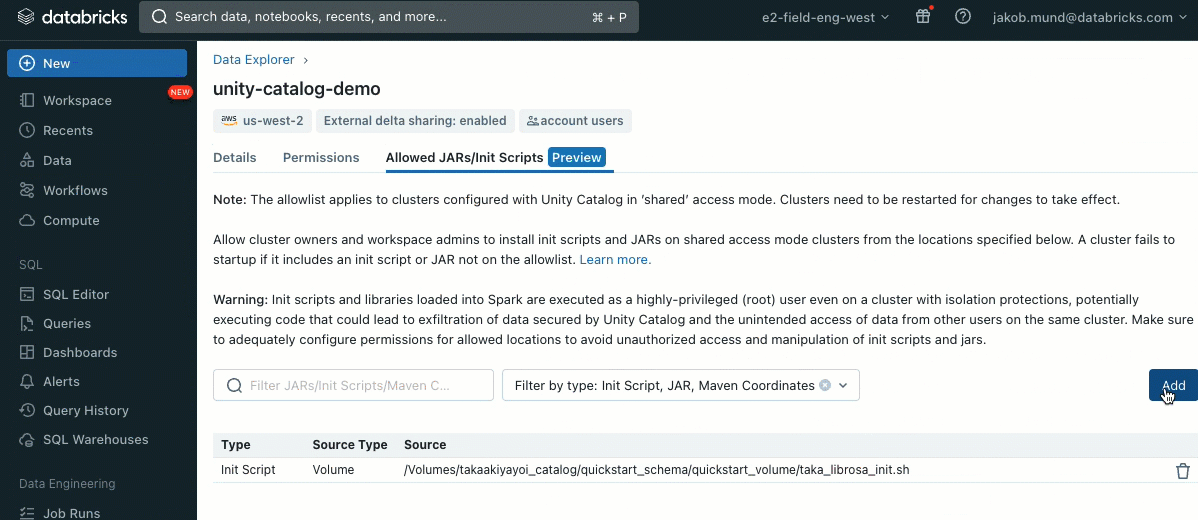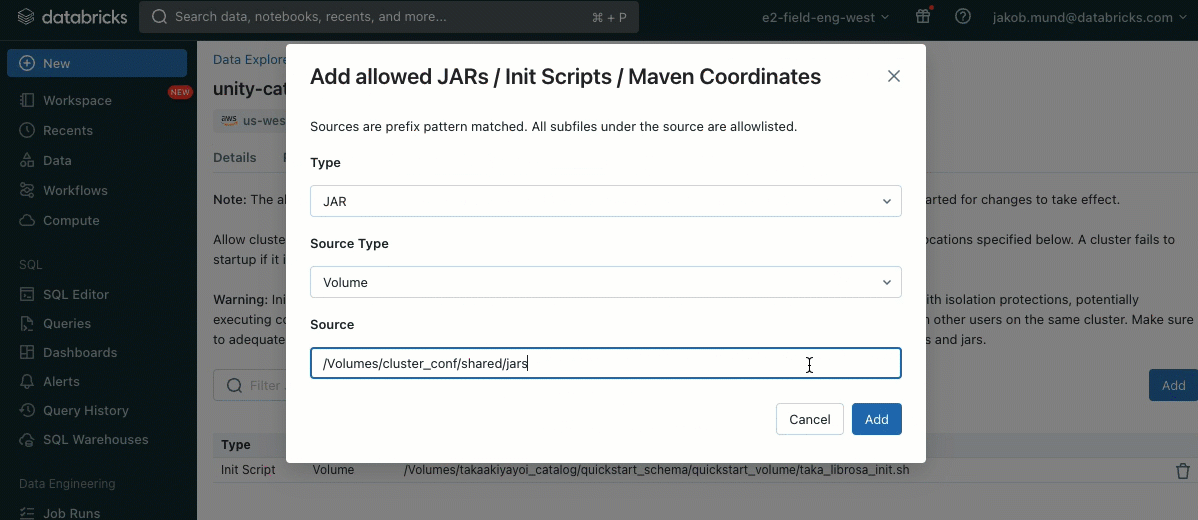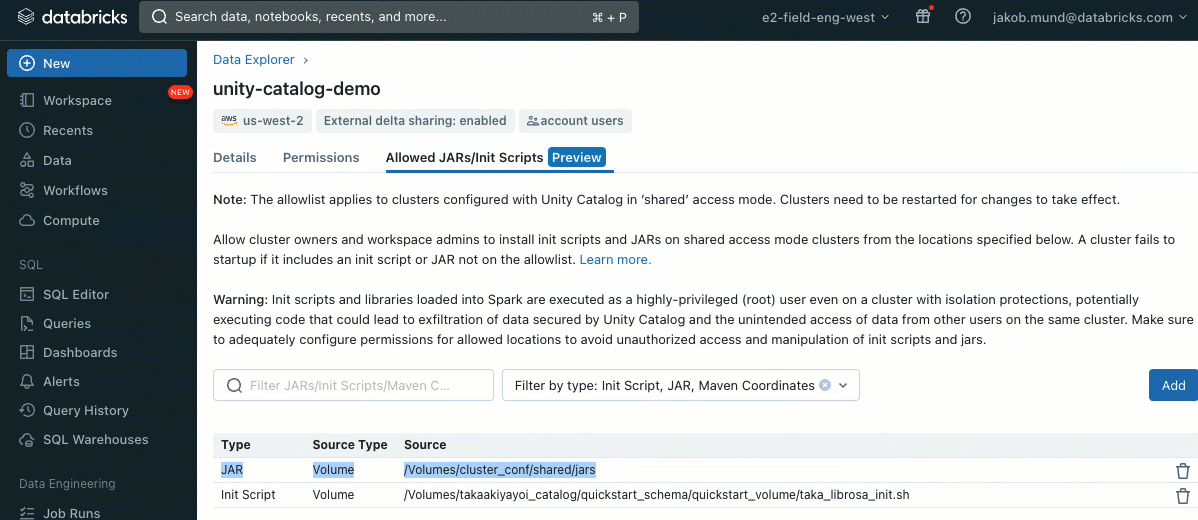
As an extra layer of safety, we introduce an allowlist (AWS, Azure, GCP) that governs the set up of cluster libraries (jars) and init scripts. This places directors accountable for managing them on shared clusters. For every metastore, the metastore admin can configure the volumes and cloud storage places from which libraries (jars) and init scripts could be put in, thereby offering a centralized repository of trusted sources and stopping unauthorized installations. This enables for extra granular management over the cluster configurations and helps keep consistency throughout your group’s information workflows.
Deliver your Scala workloads
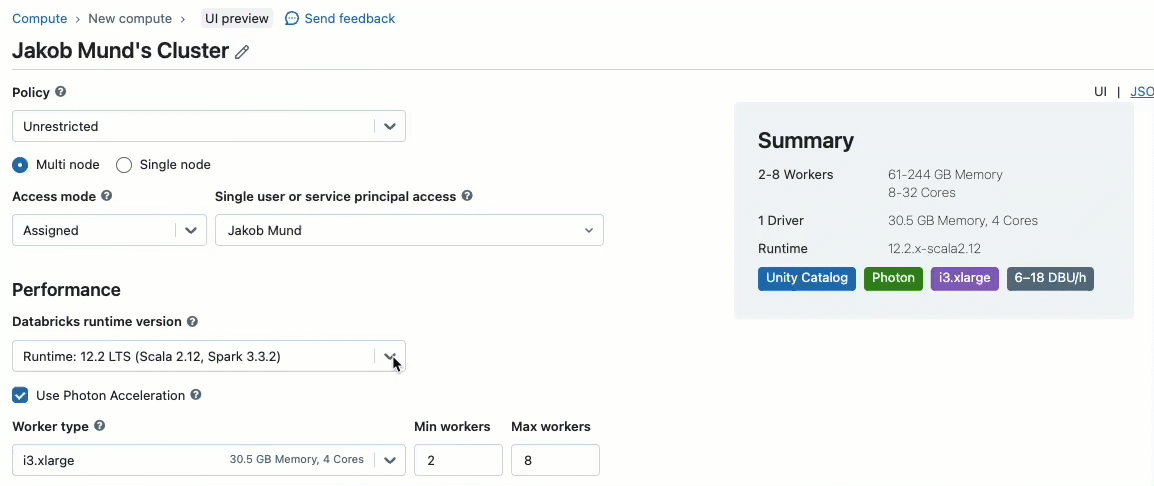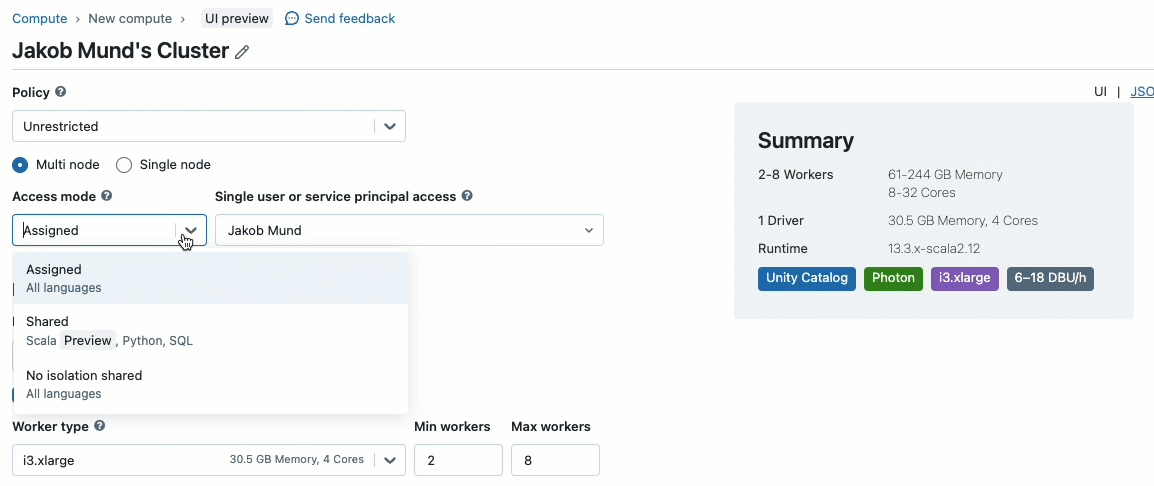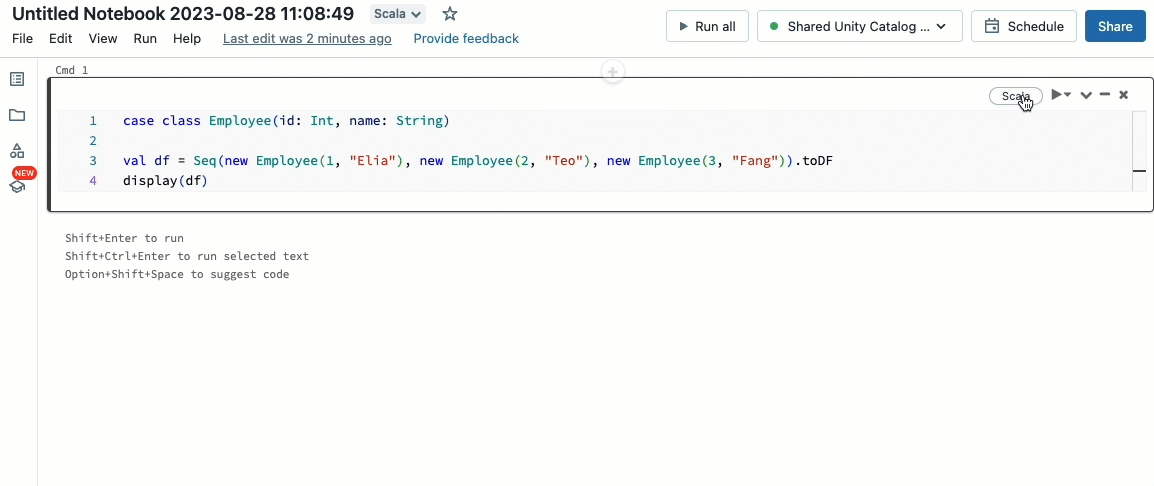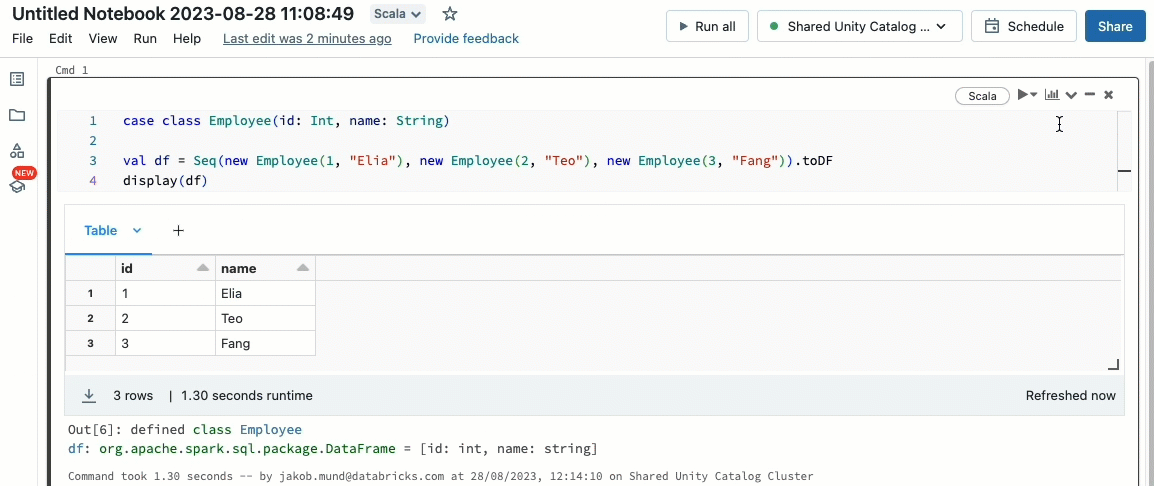
Scala is now supported on shared clusters ruled by Unity Catalog. Knowledge engineers can leverage Scala’s flexibility and efficiency to deal with all kinds of massive information challenges, collaboratively on the identical cluster and profiting from the Unity Catalog governance mannequin.
Integrating Scala into your present Databricks workflow is a breeze. Merely choose Databricks runtime 13.3 LTS or later when making a shared cluster, and you can be prepared to put in writing and execute Scala code alongside different supported languages.
Leverage Consumer-Outlined Capabilities (UDFs), Machine Studying & Structured Streaming
That is not all! We’re delighted to unveil extra game-changing developments for shared clusters.
Help for Python and Pandas Consumer Outlined Capabilities (UDFs): Now you can harness the facility of each Python and (scalar) Pandas UDFs additionally on shared clusters. Simply carry your workloads to shared clusters seamlessly – no code diversifications wanted. By isolating the execution of UDF person code on Spark executors in a sandboxed setting, shared clusters present an extra layer of safety on your information, stopping unauthorized entry and potential breaches.
Help for all common ML libraries utilizing Spark driver node and MLflow: Whether or not you are working with Scikit-learn, XGBoost, prophet, and different common ML libraries, now you can seamlessly construct, practice, and deploy machine studying fashions instantly on shared clusters. To put in ML libraries for all customers, you should utilize the brand new cluster libraries. And with built-in help for MLflow (2.2.0 or later), managing the end-to-end machine studying lifecycle has by no means been simpler.
Structured Streaming is now additionally out there on Shared Clusters ruled by Unity Catalog. This transformative addition allows real-time information processing and evaluation, revolutionizing how your information groups deal with streaming workloads collaboratively.
Begin at the moment, extra good issues to come back
Uncover the facility of Scala, Cluster libraries, Python UDFs, single-node ML, and streaming on shared clusters at the moment just by utilizing Databricks Runtime 13.3 LTS or above. Please discuss with the fast begin guides (AWS, Azure, GCP) to study extra and begin your journey towards information excellence.
Within the coming weeks and months, we are going to proceed to unify the Unity Catalog’s compute structure and make it even less complicated to work with Unity Catalog!