

{kind=link}
OpenSearch is an open-source RESTful search engine constructed on high of the Apache Lucene library. OpenSearch full-text search is quick, may give the results of complicated queries inside a fraction of a second. With OpenSearch, you may convert unstructured textual content into structured textual content utilizing completely different textual content analyzers, tokenizers, and filters to enhance search. OpenSearch makes use of a default analyzer, known as the commonplace analyzer, which works nicely for many use instances out of the field. However for some use instances, it might not work finest, and you should use a selected analyzer.
On this publish, we present how one can implement a suffix-based search. To discover a doc with the film title “saving non-public ryan” for instance, you should utilize the prefix “saving” with a prefix-based question. Sometimes, you additionally need to match suffixes as nicely, reminiscent of matching “Harry Potter Goblet of Hearth” with the suffix “Hearth” To try this, first reverse the string “eriF telboG rettoP yrraH” with the reverse token filter, then question for the prefix “eriF”.
Resolution overview
Textual content evaluation includes remodeling unstructured textual content, such because the content material of an electronic mail or a product description, right into a structured format that’s finely tuned for efficient looking out. An analyzer allows the implementation of full-text search utilizing tokenization, which entails breaking down a textual content into smaller fragments referred to as tokens, with these tokens generally representing particular person phrases. To implement a reversed discipline search, the analyzer does the next.
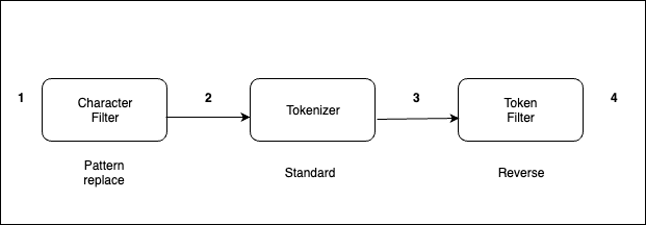
The analyzer processes textual content within the following order:
- Use a personality filter to interchange
-with_. For instance, from “My Driving License Quantity Is 123-456-789” to “My Driving License Quantity Is 123_456_789.” - The usual tokenizer splits texts into tokens. For instance, from “My Driving License Quantity Is 123_456_789” to “[ my, driving, license, number, is, 123, 456, 789 ].”
- The reverse token filter reverses every token in a stream. For instance, from [ my, driving, license, number, is, 123, 456, 789 ] to [ ym, gnivird, esnecil, rebmun, si, 321, 654, 987 ].
The usual analyzer (default analyzer) breaks down enter strings into tokens primarily based on phrase boundaries and removes most punctuation marks. For added details about analyzers, refer Construct-in analyzers.
Indexing and looking out
Each doc is a set of fields, every having its personal particular knowledge sort. Whenever you create a mapping in your knowledge, you create a mapping definition, which incorporates a listing of fields which might be pertinent to the doc. To know extra about index mappings discuss with index mapping.
Let’s take the instance of an analyzer with the reverse token filter utilized on the textual content discipline.
- First, create an index with mappings as proven within the following code. The brand new discipline ‘
reverse_title’ is derived from ‘title’ discipline for suffix search and authentic discipline ‘title’ shall be used for regular search.
- Insert some paperwork into the index:
- Run the next question to carry out a suffix/reverse search on derived discipline ‘
reverse_title’ for “Hearth”:
The next code reveals our outcomes:
- For non-reverse search you should utilize authentic discipline ‘
title’.
The next code reveals our consequence.
The question returns a doc with the film title “Harry Potter Goblet of Hearth”.
In case you’re curious to understand how search works at excessive stage, discuss with A question, or There and Again Once more.
Conclusion
On this publish, you walked by means of how textual content evaluation works in OpenSearch and the right way to implement suffix-based search utilizing a reverse token filter successfully.
If in case you have suggestions about this publish, submit your feedback within the feedback part.
In regards to the Authors
 Bharav Patel is a Specialist Resolution Architect, Analytics at Amazon Net Providers. He primarily works on Amazon OpenSearch Service and helps prospects with key ideas and design rules of working OpenSearch workloads on the cloud. Bharav likes to discover new locations and check out completely different cuisines.
Bharav Patel is a Specialist Resolution Architect, Analytics at Amazon Net Providers. He primarily works on Amazon OpenSearch Service and helps prospects with key ideas and design rules of working OpenSearch workloads on the cloud. Bharav likes to discover new locations and check out completely different cuisines.