
{kind=link}
Offloading analytics from MongoDB establishes clear isolation between write-intensive and read-intensive operations. Elasticsearch is one device to which reads will be offloaded, and, as a result of each MongoDB and Elasticsearch are NoSQL in nature and provide comparable doc construction and knowledge varieties, Elasticsearch could be a common alternative for this objective. In most situations, MongoDB can be utilized as the first knowledge storage for write-only operations and as help for fast knowledge ingestion. On this scenario, you solely have to sync the required fields in Elasticsearch with customized mappings and settings to get all the benefits of indexing.
This weblog submit will look at the varied instruments that can be utilized to sync knowledge between MongoDB and Elasticsearch. It is going to additionally talk about the varied benefits and downsides of building knowledge pipelines between MongoDB and Elasticsearch to dump learn operations from MongoDB.
Instruments to Sync Knowledge Between Elasticsearch and MongoDB
When organising an information pipeline between MongoDB and Elasticsearch, it’s essential to decide on the fitting device.
To start with, it’s essential to decide if the device is appropriate with the MongoDB and Elasticsearch variations you’re utilizing. Moreover, your use case would possibly have an effect on the best way you arrange the pipeline. You probably have static knowledge in MongoDB, you could want a one-time sync. Nonetheless, a real-time sync will likely be required if steady operations are being carried out in MongoDB and all of them should be synced. Lastly, you’ll want to contemplate whether or not or not knowledge manipulation or normalization is required earlier than knowledge is written to Elasticsearch.

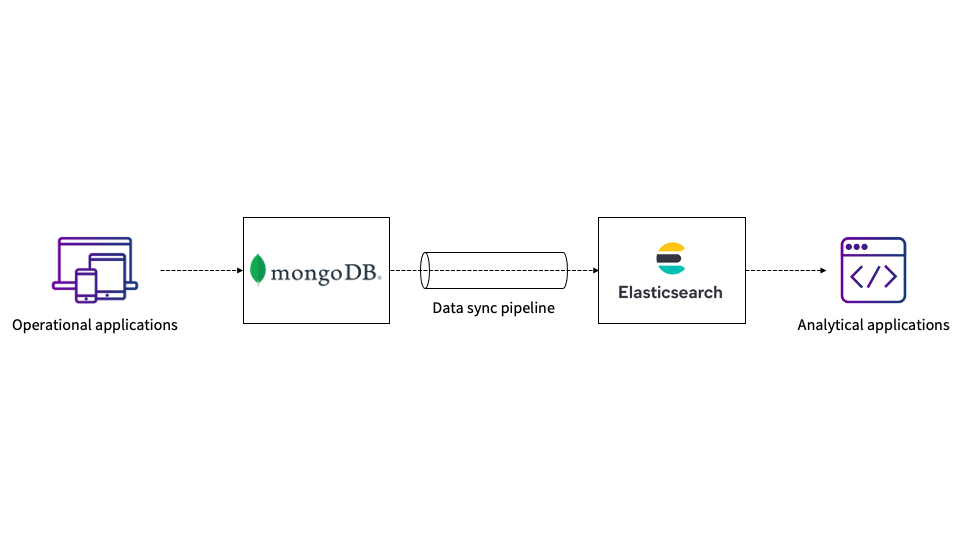
Determine 1: Utilizing a pipeline to sync MongoDB to Elasticsearch
If it’s essential to replicate each MongoDB operation in Elasticsearch, you’ll have to depend on MongoDB oplogs (that are capped collections), and also you’ll have to run MongoDB in cluster mode with replication on. Alternatively, you possibly can configure your software in such a means that every one operations are written to each MongoDB and Elasticsearch situations with assured atomicity and consistency.
With these issues in thoughts, let’s take a look at some instruments that can be utilized to duplicate MongoDB knowledge to Elasticsearch.
Monstache
Monstache is without doubt one of the most complete libraries obtainable to sync MongoDB knowledge to Elasticsearch. Written in Go, it helps as much as and together with the newest variations of MongoDB and Elasticsearch. Monstache can be obtainable as a sync daemon and a container.
Mongo-Connector
Mongo-Connector, which is written in Python, is a broadly used device for syncing knowledge between MongoDB and Elasticsearch. It solely helps Elasticsearch by model 5.x and MongoDB by model 3.6.
Mongoosastic
Mongoosastic, written in NodeJS, is a plugin for Mongoose, a preferred MongoDB knowledge modeling device primarily based on ORM. Mongoosastic concurrently writes knowledge in MongoDB and Elasticsearch. No further processes are wanted for it to sync knowledge.

Determine 2: Writing concurrently to MongoDB and Elasticsearch
Logstash JDBC Enter Plugin
Logstash is Elastic’s official device for integrating a number of enter sources and facilitating knowledge syncing with Elasticsearch. To make use of MongoDB as an enter, you possibly can make use of the JDBC enter plugin, which makes use of the MongoDB JDBC driver as a prerequisite.
Customized Scripts
If the instruments described above don’t meet your necessities, you possibly can write customized scripts in any of the popular languages. Keep in mind that sound data of each the applied sciences and their administration is important to put in writing customized scripts.
Benefits of Offloading Analytics to Elasticsearch
By syncing knowledge from MongoDB to Elasticsearch, you take away load out of your main MongoDB database and leverage a number of different benefits supplied by Elasticsearch. Let’s check out a few of these.
Reads Don’t Intrude with Writes
In most situations, studying knowledge requires extra sources than writing. For sooner question execution, you could have to construct indexes in MongoDB, which not solely consumes numerous reminiscence but additionally slows down write velocity.
Further Analytical Performance
Elasticsearch is a search server constructed on prime of Lucene that shops knowledge in a singular construction often called an inverted index. Inverted indexes are notably useful for full-text searches and doc retrievals at scale. They will additionally carry out aggregations and analytics and, in some instances, present further providers not supplied by MongoDB. Widespread use instances for Elasticsearch analytics embody real-time monitoring, APM, anomaly detection, and safety analytics.
A number of Choices to Retailer and Search Knowledge
One other benefit of placing knowledge into Elasticsearch is the potential for indexing a single subject in a number of methods by utilizing some mapping configurations. This function assists in storing a number of variations of a subject that can be utilized for various kinds of analytic queries.
Higher Assist for Time Collection Knowledge
In functions that generate an enormous quantity of information, akin to IoT functions, reaching excessive efficiency for each reads and writes could be a difficult job. Utilizing MongoDB and Elasticsearch together could be a helpful method in these situations since it’s then very simple to retailer the time collection knowledge in a number of indices (akin to day by day or month-to-month indices) and search these indices’ knowledge by way of aliases.
Versatile Knowledge Storage and an Incremental Backup Technique
Elasticsearch helps incremental knowledge backups utilizing the _snapshot API. These backups will be carried out on the file system or on cloud storage straight from the cluster. This function deletes the previous knowledge from the Elasticsearch cluster as soon as the backup is taken. Every time entry to previous knowledge is important, it will possibly simply be restored from the backups utilizing the _restore API. This lets you decide how a lot knowledge needs to be saved within the stay cluster and in addition facilitates higher useful resource assignments for the learn operations in Elasticsearch.
Integration with Kibana
As soon as you place knowledge into Elasticsearch, it may be linked to Kibana, which makes it simple to discover the information, plus construct visualizations and dashboards.

Disadvantages of Offloading Analytics to Elasticsearch
Whereas there are a number of benefits to indexing MongoDB knowledge into Elasticsearch, there are a selection of potential disadvantages try to be conscious of as nicely, which we talk about under.
Constructing and Sustaining a Knowledge Sync Pipeline
Whether or not you utilize a device or write a customized script to construct your knowledge sync pipeline, sustaining consistency between the 2 knowledge shops is at all times a difficult job. The pipeline can go down or just turn out to be arduous to handle attributable to a number of causes, akin to both of the information shops shutting down or any knowledge format adjustments within the MongoDB collections. If the information sync depends on MongoDB oplogs, optimum oplog parameters needs to be configured to guarantee that knowledge is synced earlier than it disappears from the oplogs. As well as, when it’s essential to use many Elasticsearch options, complexity can improve if the device you’re utilizing shouldn’t be customizable sufficient to help the required configurations, akin to customized routing, parent-child or nested relationships, indexing referenced fashions, and changing dates to codecs recognizable by Elasticsearch.
Knowledge Kind Conflicts
Each MongoDB and Elasticsearch are document-based and NoSQL knowledge shops. Each of those knowledge shops enable dynamic subject ingestion. Nonetheless, MongoDB is totally schemaless in nature, and Elasticsearch, regardless of being schemaless, doesn’t enable completely different knowledge kinds of a single subject throughout the paperwork inside an index. This could be a main problem if the schema of MongoDB collections shouldn’t be mounted. It’s at all times advisable to outline the schema upfront for Elasticsearch. This can keep away from conflicts that may happen whereas indexing the information.
Knowledge Safety
MongoDB is a core database and comes with fine-grained safety controls, akin to built-in authentication and person creations primarily based on built-in or configurable roles. Elasticsearch doesn’t present such controls by default. Though it’s achievable within the X-Pack model of Elastic Stack, it’s arduous to implement the security measures in free variations.
The Issue of Working an Elasticsearch Cluster
Elasticsearch is difficult to handle at scale, particularly should you’re already operating a MongoDB cluster and organising the information sync pipeline. Cluster administration, horizontal scaling, and capability planning include some limitations. Challenges come up when the applying is write-intensive and the Elasticsearch cluster doesn’t have sufficient sources to deal with that load. As soon as shards are created, they’ll’t be elevated on the fly. As a substitute, it’s essential to create a brand new index with a brand new variety of shards and carry out reindexing, which is tedious.
Reminiscence-Intensive Course of
Elasticsearch is written in Java and writes knowledge within the type of immutable Lucene segments. This underlying knowledge construction causes these segments to proceed merging within the background, which requires a major quantity of sources. Heavy aggregations additionally trigger excessive reminiscence utilization and should trigger out of reminiscence (OOM) errors. When these errors seem, cluster scaling is usually required, which could be a tough job if in case you have a restricted variety of shards per index or budgetary issues.
No Assist for Joins
Elasticsearch doesn’t help full-fledged relationships and joins. It does help nested and parent-child relationships, however they’re often gradual to carry out or require further sources to function. In case your MongoDB knowledge is predicated on references, it could be tough to sync the information in Elasticsearch and write queries on prime of them.
Deep Pagination Is Discouraged
One of many largest benefits of utilizing a core database is which you can create a cursor and iterate by the information whereas performing the kind operations. Nonetheless, Elasticsearch’s regular search queries don’t help you fetch greater than 10,000 paperwork from the entire search end result. Elasticsearch does have a devoted scroll API to realize this job, though it, too, comes with limitations.
Makes use of Elasticsearch DSL
Elasticsearch has its personal question DSL, however you want a superb hands-on understanding of its pitfalls to put in writing optimized queries. Whereas you may also write queries utilizing Lucene Syntax, its grammar is hard to be taught, and it lacks enter sanitization. Elasticsearch DSL shouldn’t be appropriate with SQL visualization instruments and, subsequently, provides restricted capabilities for performing analytics and constructing reviews.
Abstract
In case your software is primarily performing textual content searches, Elasticsearch could be a good choice for offloading reads from MongoDB. Nonetheless, this structure requires an funding in constructing and sustaining an information pipeline between the 2 instruments.
The Elasticsearch cluster additionally requires appreciable effort to handle and scale. In case your use case includes extra complicated analytics—akin to filters, aggregations, and joins—then Elasticsearch might not be your finest resolution. In these conditions, Rockset, a real-time indexing database, could also be a greater match. It offers each a local connector to MongoDB and full SQL analytics, and it’s supplied as a totally managed cloud service.

Study extra about offloading from MongoDB utilizing Rockset in these associated blogs: