

{kind=link}
This put up is a continuation of a two-part sequence. Within the first half, we delved into Apache Flink‘s inner mechanisms for checkpointing, in-flight knowledge buffering, and dealing with backpressure. We lined these ideas so as to perceive how buffer debloating and unaligned checkpoints enable us to reinforce efficiency for particular circumstances in Apache Flink functions.
In Half 1, we launched and examined find out how to use buffer debloating to enhance in-flight knowledge processing. On this put up, we give attention to unaligned checkpoints. This function has been out there since Apache Flink 1.11 and has obtained many enhancements since then. Unaligned checkpoints assist, below particular circumstances, to scale back checkpointing time for functions struggling momentary backpressure, and might be now enabled in Amazon Managed Service for Apache Flink functions operating Apache Flink 1.15.2 by means of a assist ticket.
Regardless that this function would possibly enhance efficiency in your checkpoints, in case your software is continually failing due to checkpoints timing out, or is affected by having fixed backpressure, you might require a deeper evaluation and redesign of your software.
Aligned checkpoints
As mentioned in Half 1, Apache Flink checkpointing permits functions to file state in case of failure. We’ve already mentioned how checkpoints, when triggered by the job supervisor, sign all supply operators to snapshot their state, which is then broadcasted as a particular file known as a checkpoint barrier. This course of achieves exactly-once consistency for state in a distributed streaming software by means of the alignment of those obstacles.
Let’s stroll by means of the method of aligned checkpoints in a typical Apache Flink software. Do not forget that Apache Flink distributes the workload horizontally: every operator (a node within the logical circulate of your software, together with sources and sinks) is break up into a number of sub-tasks based mostly on its parallelism.
Barrier alignment
The alignment of checkpoint obstacles is essential for attaining exactly-once consistency in Apache Flink functions throughout checkpoint runs. To recap, when a job supervisor triggers a checkpoint, all sub-tasks of supply operators obtain a sign to provoke the checkpoint course of. Every sub-task independently snapshots its state to the state backend and broadcasts a particular file generally known as a checkpoint barrier to all outgoing streams.
When an software operates with a parallelism increased than 1, a number of situations of every process—known as sub-tasks—allow parallel message consumption and processing. A sub-task can obtain distinct partitions of the identical stream from completely different upstream sub-tasks, reminiscent of after a stream repartitioning with keyBy or rebalance operations. To keep up exactly-once consistency, all sub-tasks should await the arrival of all checkpoint obstacles earlier than taking a snapshot of the state. The next diagram illustrates the checkpoint obstacles circulate.

This part is named checkpoint alignment. Throughout alignment, the sub-task stops processing data from the partitions from which it has already obtained obstacles, as proven within the following determine.

Nonetheless, it continues to course of partitions which are behind the barrier.

When obstacles from all upstream partitions have arrived, the sub-task takes a snapshot of its state.

Then it broadcasts the barrier downstream.

The time a sub-task spends ready for all obstacles to reach is measured by the checkpoint Alignment Length metric, which might be noticed within the Apache Flink UI.
If the applying experiences backpressure, a rise on this metric may result in longer checkpoint durations and even checkpoint failures because of timeouts. That is the place unaligned checkpoints turn into a viable choice to probably improve checkpointing efficiency.
Unaligned checkpoints
Unaligned checkpoints tackle conditions the place backpressure isn’t just a short lived spike, however leads to timeouts for aligned checkpoints, because of barrier queuing inside the stream. As mentioned in Half 1, checkpoint obstacles can’t overtake common data. Due to this fact, important backpressure can decelerate the motion of obstacles throughout the applying, probably inflicting checkpoint timeouts.
The target of unaligned checkpoints is to allow barrier overtaking, permitting obstacles to maneuver swiftly from supply to sink even when the info circulate is slower than anticipated.
Constructing on what we noticed in Half 1 regarding checkpoints and what aligned checkpoints are, let’s discover how unaligned checkpoints modify the checkpointing mechanism.
Upon emission, every supply’s checkpoint barrier is injected into the stream flowing throughout sub-tasks. It travels from the supply output community buffer queue into the enter community buffer queue of the following operator.
Upon the arrival of the primary barrier within the enter community buffer queue, the operator initially waits for barrier alignment. If the required alignment timeout expires as a result of not all obstacles have reached the top of the enter community buffer queue, the operator switches to unaligned checkpoint mode.
The alignment timeout might be set programmatically by env.getCheckpointConfig().setAlignedCheckpointTimeout(Length.ofSeconds(30)), however modifying the default just isn’t advisable in Apache Flink 1.15.

The operator waits till all checkpoint obstacles are current within the enter community buffer queue earlier than triggering the checkpoint. Not like aligned checkpoints, the operator doesn’t want to attend for all obstacles to achieve the queue’s finish, permitting the operator to have in-flight knowledge from the buffer that hasn’t been processed earlier than checkpoint initiation.

In spite of everything obstacles have arrived within the enter community buffer queue, the operator advances the barrier to the top of the output community buffer queue. This enhances checkpointing velocity as a result of the barrier can easily traverse the applying from supply to sink, unbiased of the applying’s end-to-end latency.

After forwarding the barrier to the output community buffer queue, the operator initiates the snapshot of in-flight knowledge between the obstacles within the enter and output community buffer queues, together with the snapshot of the state.
Though processing is momentarily paused throughout this course of, the precise writing to the distant persistent state storage happens asynchronously, stopping potential bottlenecks.

The native snapshot, encompassing in-flight messages and state, is saved asynchronously within the distant persistent state retailer, whereas the barrier continues its journey by means of the applying.

When to make use of unaligned checkpoints
Bear in mind, barrier alignment solely happens between partitions coming from completely different sub-tasks of the identical operator. Due to this fact, if an operator is experiencing momentary backpressure, enabling unaligned checkpoints could also be useful. This fashion, the applying doesn’t have to attend for all obstacles to achieve the operator earlier than performing the snapshot of state or transferring the barrier ahead.
Momentary backpressure may come up from the next:
- A surge in knowledge ingestion
- Backfilling or catching up with historic knowledge
- Elevated message processing time because of delayed exterior techniques
One other state of affairs the place unaligned checkpoints show advantageous is when working with exactly-once sinks. Using the two-phase commit sink operate for exactly-once sinks, unaligned checkpoints can expedite checkpoint runs, thereby lowering end-to-end latency.
When to not use unaligned checkpoints
Unaligned checkpoints received’t cut back the time required for savepoints (known as snapshots within the Amazon Managed Service for Apache Flink implementation) as a result of savepoints completely make the most of aligned checkpoints. Moreover, as a result of Apache Flink doesn’t allow concurrent unaligned checkpoints, savepoints received’t happen concurrently with unaligned checkpoints, probably elongating savepoint durations.
Unaligned checkpoints received’t repair any underlying subject in your software design. In case your software is affected by persistent backpressure or fixed checkpointing timeouts, this would possibly point out knowledge skewness or underprovisioning, which can require enhancing and tuning the applying.
Utilizing unaligned checkpoints with buffer debloating
One various for lowering the dangers related to an elevated state measurement is to mix unaligned checkpoints with buffer debloating. This method leads to having much less in-flight knowledge to snapshot and retailer within the state, together with much less knowledge for use for restoration in case of failure. This synergy facilitates enhanced efficiency and environment friendly checkpoint runs, resulting in smaller checkpointing sizes and quicker restoration occasions. When testing using unaligned checkpoints, we suggest doing so with buffer debloating to forestall the state measurement from rising.
Limitations
Unaligned checkpoints are topic to the next limitations:
- They supply no profit for operators with a parallelism of 1.
- They solely enhance efficiency for operators the place barrier alignment would have occurred. This alignment occurs provided that data are coming from completely different sub-tasks of the identical operator, for instance, by means of repartitioning or
keyByoperations. - Operators receiving enter from a number of sources or collaborating in joins won’t expertise enhancements, as a result of the operator can be receiving knowledge from completely different operators in these instances.
- Though checkpoint obstacles can surpass data within the community’s buffer queue, this received’t happen if the sub-task is presently processing a message. If processing a message takes an excessive amount of time (for instance, a flat-map operation emitting quite a few data for every enter file), barrier dealing with might be delayed.
- As now we have seen, savepoints all the time use aligned checkpoints. If the savepoints of your functions are sluggish because of barrier alignment, unaligned checkpoints won’t assist.
- Further limitations have an effect on watermarks, message ordering, and broadcast state in restoration. For extra particulars, check with Limitations.
Issues
Issues for implementing unaligned checkpoints:
- Unaligned checkpoints introduce further I/O to checkpoint storage
- Checkpoints embody not solely operator state but in addition in-flight knowledge inside community buffer queues, resulting in elevated state measurement
Suggestions
We provide the next suggestions:
- Think about enabling unaligned checkpoints provided that each of the next circumstances are true:
- Checkpoints are timing out.
- The common checkpoint Async Length of any operator is greater than 50% of the entire checkpoint period for the operator (sum of Sync Length + Async Length).
- Think about enabling buffer debloating first, and consider whether or not it solves the issue of checkpoints timing out.
- If buffer debloating doesn’t assist, contemplate enabling unaligned checkpoints together with buffer debloating. Buffer debloating mitigates the drawbacks of unaligned checkpoints, lowering the quantity of in-flight knowledge.
- If unaligned checkpoints and buffer debloating collectively don’t enhance checkpoint alignment period, contemplate testing unaligned checkpoints alone.
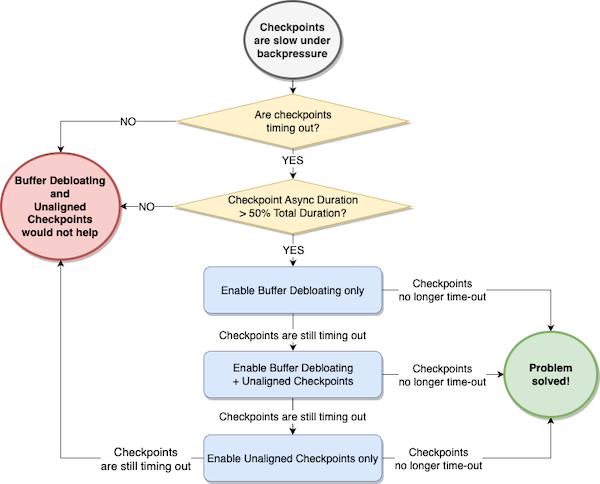
Lastly, however most significantly, all the time check unaligned checkpoints in a non-production surroundings first, operating some comparative efficiency testing with a sensible workload, and confirm that unaligned checkpoints really cut back checkpoint period.
Conclusion
This two-part sequence explored superior methods for optimizing checkpointing inside your Amazon Managed Service for Apache Flink functions. By harnessing the potential of buffer debloating and unaligned checkpoints, you possibly can unlock important efficiency enhancements and streamline checkpoint processes. Nonetheless, it’s essential to grasp when these strategies will present enhancements and when they won’t. In case you consider your software might profit from checkpoint efficiency enchancment, you possibly can allow these options in your Amazon Managed Service For Apache Flink model 1.15 functions. We suggest first enabling buffer debloating and testing the applying. In case you are nonetheless not seeing the anticipated final result, allow buffer debloating with unaligned checkpoints. This fashion, you possibly can instantly cut back the state measurement and the extra I/O to state backends. Lastly, you might strive utilizing unaligned checkpoints by itself, making an allowance for the issues we’ve talked about.
With a deeper understanding of those strategies and their applicability, you’re higher outfitted to maximise the effectivity of checkpoints and mitigate the impact of backpressure in your Apache Flink software.
Concerning the Authors
 Lorenzo Nicora works as Senior Streaming Answer Architect serving to clients throughout EMEA. He has been constructing cloud-native, data-intensive techniques for over 25 years, working within the finance business each by means of consultancies and for FinTech product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of tasks, together with Apache Flink.
Lorenzo Nicora works as Senior Streaming Answer Architect serving to clients throughout EMEA. He has been constructing cloud-native, data-intensive techniques for over 25 years, working within the finance business each by means of consultancies and for FinTech product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of tasks, together with Apache Flink.
 Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS clients serving to them design real-time analytics architectures utilizing AWS providers, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.
Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS clients serving to them design real-time analytics architectures utilizing AWS providers, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.