
{kind=link}
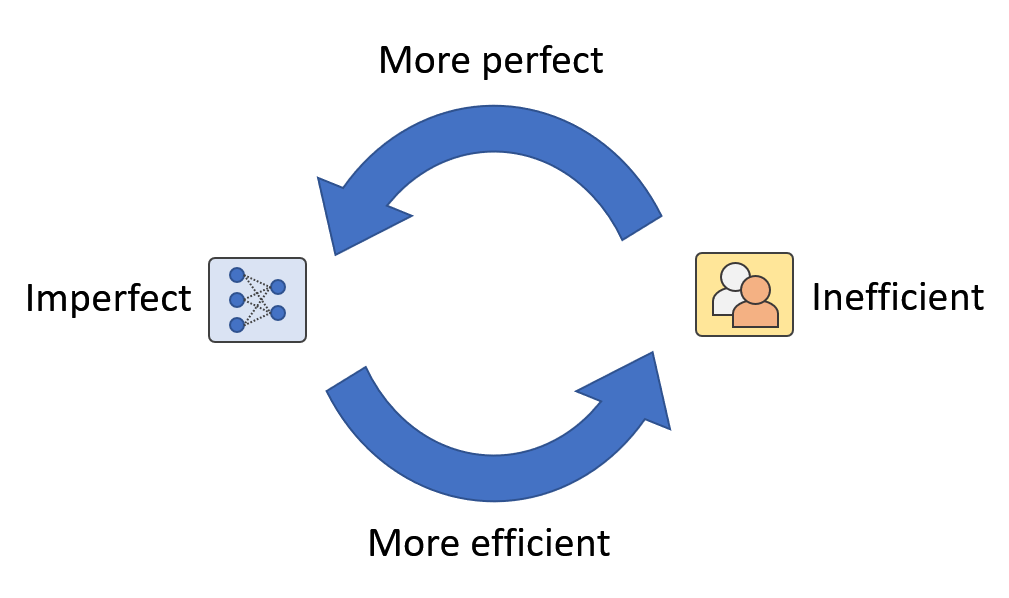
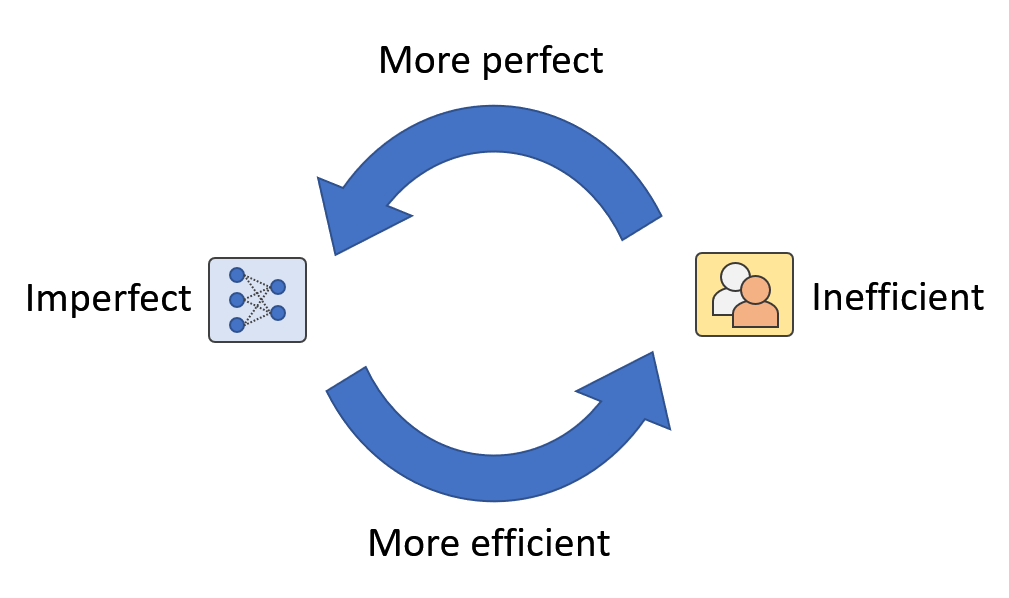
Determine 1: In real-world functions, we predict there exist a human-machine loop the place people and machines are mutually augmenting one another. We name it Synthetic Augmented Intelligence.
How can we construct and consider an AI system for real-world functions? In most AI analysis, the analysis of AI strategies includes a training-validation-testing course of. The experiments often cease when the fashions have good testing efficiency on the reported datasets as a result of real-world information distribution is assumed to be modeled by the validation and testing information. Nevertheless, real-world functions are often extra difficult than a single training-validation-testing course of. The most important distinction is the ever-changing information. For instance, wildlife datasets change at school composition on a regular basis due to animal invasion, re-introduction, re-colonization, and seasonal animal actions. A mannequin skilled, validated, and examined on present datasets can simply be damaged when newly collected information comprise novel species. Thankfully, we have now out-of-distribution detection strategies that may assist us detect samples of novel species. Nevertheless, once we wish to increase the popularity capability (i.e., having the ability to acknowledge novel species sooner or later), the most effective we will do is fine-tuning the fashions with new ground-truthed annotations. In different phrases, we have to incorporate human effort/annotations no matter how the fashions carry out on earlier testing units.
When human annotations are inevitable, real-world recognition methods change into a unending loop of information assortment → annotation → mannequin fine-tuning (Determine 2). In consequence, the efficiency of 1 single step of mannequin analysis doesn’t signify the precise generalization of the entire recognition system as a result of the mannequin will likely be up to date with new information annotations, and a brand new spherical of analysis will likely be performed. With this loop in thoughts, we predict that as a substitute of constructing a mannequin with higher testing efficiency, specializing in how a lot human effort might be saved is a extra generalized and sensible objective in real-world functions.
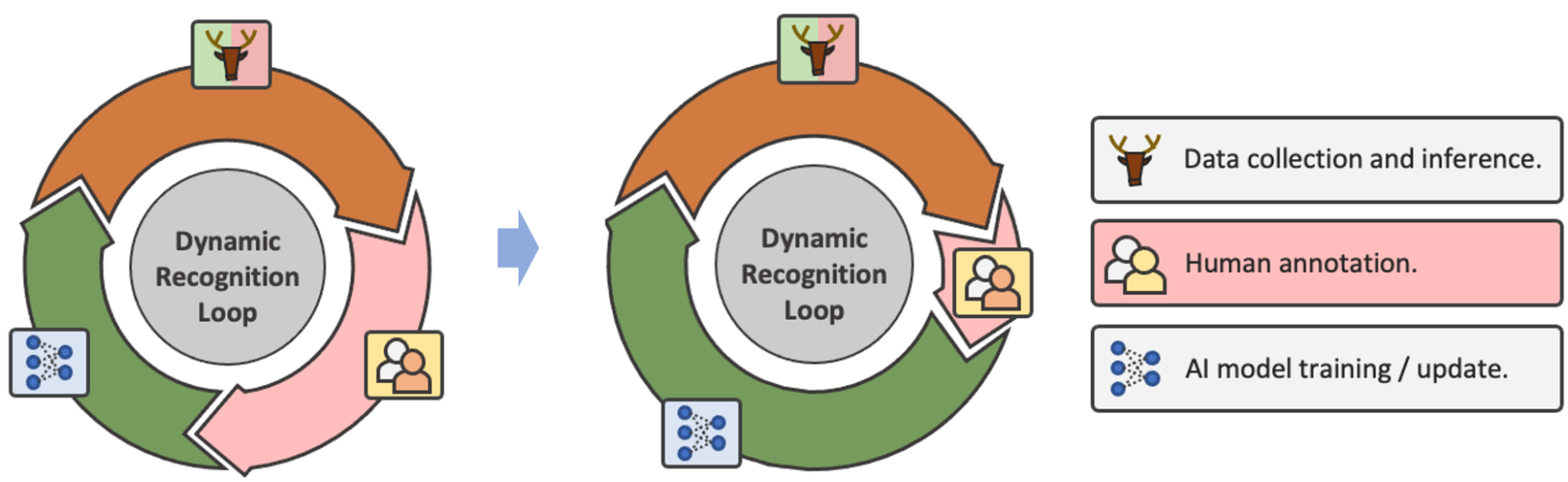
Determine 2: Within the loop of knowledge assortment, annotation, and mannequin replace, the objective of optimization turns into minimizing the requirement of human annotation somewhat than single-step recognition efficiency.
Within the paper we revealed final 12 months in Nature-Machine Intelligence [1], we mentioned the incorporation of human-in-the-loop into wildlife recognition and proposed to look at human effort effectivity in mannequin updates as a substitute of straightforward testing efficiency. For demonstration, we designed a recognition framework that was a mixture of energetic studying, semi-supervised studying, and human-in-the-loop (Determine 3). We additionally integrated a time part into this framework to point that the popularity fashions didn’t cease at any single time step. Usually talking, within the framework, at every time step, when new information are collected, a recognition mannequin actively selects which information needs to be annotated primarily based on a prediction confidence metric. Low-confidence predictions are despatched for human annotation, and high-confidence predictions are trusted for downstream duties or pseudo-labels for mannequin updates.
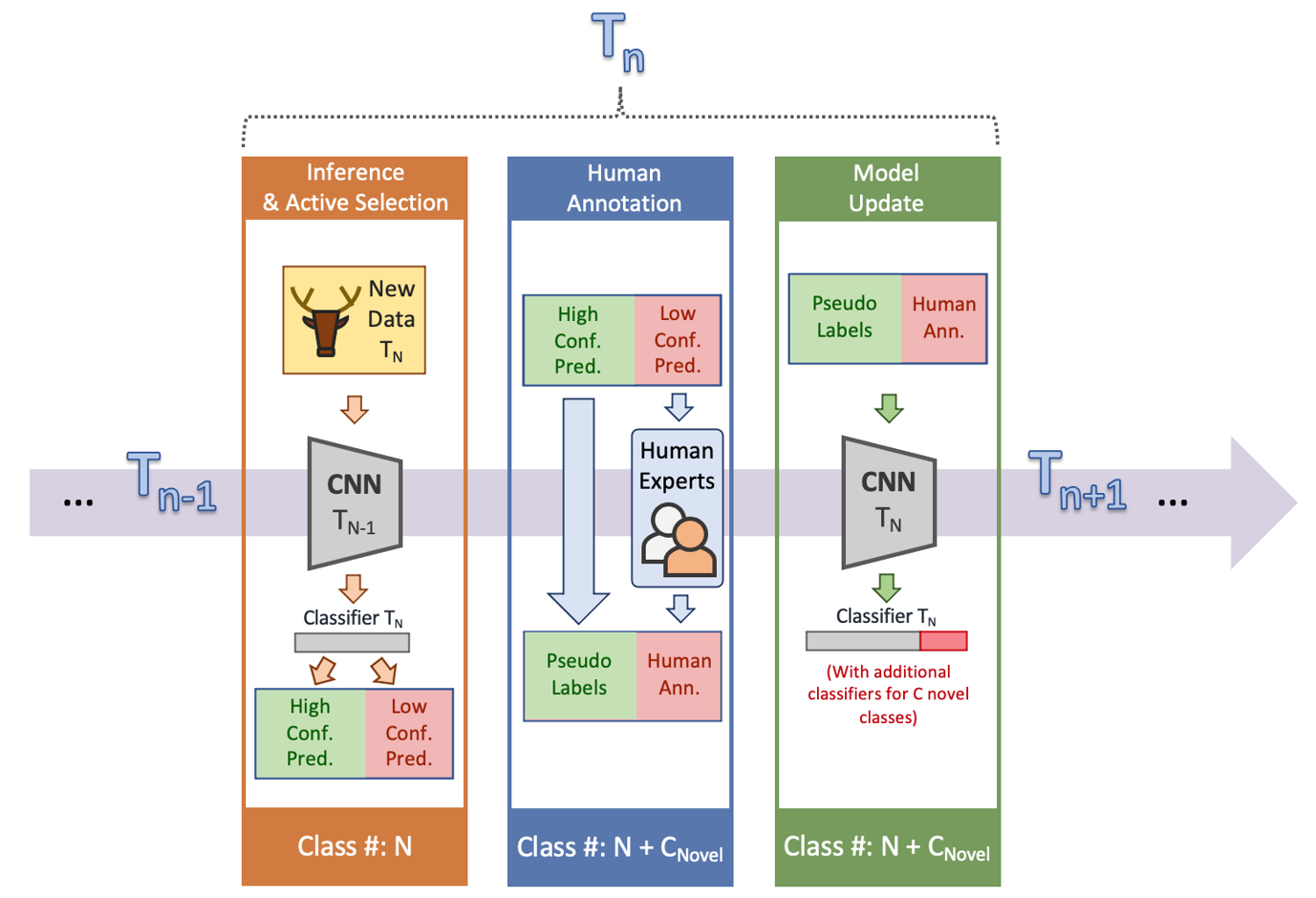
Determine 3: Right here, we current an iterative recognition framework that may each maximize the utility of contemporary picture recognition strategies and reduce the dependence on guide annotations for mannequin updating.
By way of human annotation effectivity for mannequin updates, we cut up the analysis into 1) the proportion of high-confidence predictions on validation (i.e., saved human effort for annotation); 2) the accuracy of high-confidence predictions (i.e., reliability); and three) the proportion of novel classes which can be detected as low-confidence predictions (i.e., sensitivity to novelty). With these three metrics, the optimization of the framework turns into minimizing human efforts (i.e., to maximise high-confidence proportion) and maximizing mannequin replace efficiency and high-confidence accuracy.
We reported a two-step experiment on a large-scale wildlife digicam entice dataset collected from Mozambique Nationwide Park for demonstration functions. Step one was an initialization step to initialize a mannequin with solely a part of the dataset. Within the second step, a brand new set of knowledge with recognized and novel courses was utilized to the initialized mannequin. Following the framework, the mannequin made predictions on the brand new dataset with confidence, the place high-confidence predictions have been trusted as pseudo-labels, and low-confidence predictions have been supplied with human annotations. Then, the mannequin was up to date with each pseudo-labels and annotations and prepared for the long run time steps. In consequence, the proportion of high-confidence predictions on second step validation was 72.2%, the accuracy of high-confidence predictions was 90.2%, and the proportion of novel courses detected as low-confidence was 82.6%. In different phrases, our framework saved 72% of human effort on annotating all of the second step information. So long as the mannequin was assured, 90% of the predictions have been appropriate. As well as, 82% of novel samples have been efficiently detected. Particulars of the framework and experiments might be discovered within the unique paper.
By taking a more in-depth take a look at Determine 3, apart from the information assortment – human annotation – mannequin replace loop, there may be one other human-machine loop hidden within the framework (Determine 1). It is a loop the place each people and machines are continually bettering one another by way of mannequin updates and human intervention. For instance, when AI fashions can not acknowledge novel courses, human intervention can present data to increase the mannequin’s recognition capability. Alternatively, when AI fashions get an increasing number of generalized, the requirement for human effort will get much less. In different phrases, the usage of human effort will get extra environment friendly.
As well as, the confidence-based human-in-the-loop framework we proposed just isn’t restricted to novel class detection however can even assist with points like long-tailed distribution and multi-domain discrepancies. So long as AI fashions really feel much less assured, human intervention is available in to assist enhance the mannequin. Equally, human effort is saved so long as AI fashions really feel assured, and generally human errors may even be corrected (Determine 4). On this case, the connection between people and machines turns into synergistic. Thus, the objective of AI improvement modifications from changing human intelligence to mutually augmenting each human and machine intelligence. We name this kind of AI: Synthetic Augmented Intelligence (A2I).
Ever since we began engaged on synthetic intelligence, we have now been asking ourselves, what can we create AI for? At first, we believed that, ideally, AI ought to totally substitute human effort in easy and tedious duties corresponding to large-scale picture recognition and automotive driving. Thus, we have now been pushing our fashions to an thought referred to as “human-level efficiency” for a very long time. Nevertheless, this objective of changing human effort is intrinsically increase opposition or a mutually unique relationship between people and machines. In real-world functions, the efficiency of AI strategies is simply restricted by so many affecting elements like long-tailed distribution, multi-domain discrepancies, label noise, weak supervision, out-of-distribution detection, and so on. Most of those issues might be in some way relieved with correct human intervention. The framework we proposed is only one instance of how these separate issues might be summarized into high- versus low-confidence prediction issues and the way human effort might be launched into the entire AI system. We predict it isn’t dishonest or surrendering to onerous issues. It’s a extra human-centric approach of AI improvement, the place the main focus is on how a lot human effort is saved somewhat than what number of testing photographs a mannequin can acknowledge. Earlier than the belief of Synthetic Common Intelligence (AGI), we predict it’s worthwhile to additional discover the course of machine-human interactions and A2I such that AI can begin making extra impacts in varied sensible fields.

Determine 4: Examples of high-confidence predictions that didn’t match the unique annotations. Many high-confidence predictions that have been flagged as incorrect primarily based on validation labels (supplied by college students and citizen scientists) have been the truth is appropriate upon nearer inspection by wildlife specialists.
Acknowledgements: We thank all co-authors of the paper “Iterative Human and Automated Identification of Wildlife Photos” for his or her contributions and discussions in getting ready this weblog. The views and opinions expressed on this weblog are solely of the authors of this paper.
This weblog submit is predicated on the next paper which is revealed at Nature – Machine Intelligence:
[1] Miao, Zhongqi, Ziwei Liu, Kaitlyn M. Gaynor, Meredith S. Palmer, Stella X. Yu, and Wayne M. Getz. “Iterative human and automatic identification of wildlife photographs.” Nature Machine Intelligence 3, no. 10 (2021): 885-895.(Hyperlink to Pre-print)