
{kind=link}
In his 2016 e book, The Fourth Industrial Revolution, Klaus Schwab, the founding father of the World Financial Discussion board, predicted the appearance of the subsequent technological revolution, underpinned by synthetic intelligence (AI). He argued that, like its predecessors, the AI revolution would wield world socio-economic repercussions. Schwab’s writing was prescient. In November 2022, OpenAI launched ChatGPT, a massive language mannequin (LLM) embedded with a dialog agent. The reception was phenomenal, with greater than 100 million folks accessing it throughout the first two months. Not solely did ChatGPT garner widespread private use, however lots of of companies promptly integrated it and different LLMs to optimize their processes and to allow new merchandise. On this weblog submit, tailored from our current whitepaper, we study the capabilities and limitations of LLMs. In a future submit, we’ll current 4 case research that discover potential purposes of LLMs.
Regardless of the consensus that this know-how revolution may have world penalties, specialists differ on whether or not the influence shall be constructive or detrimental. On one hand, OpenAI’s acknowledged mission is to create techniques that profit all of humanity. Alternatively, following the discharge of ChatGPT, greater than a thousand researchers and know-how leaders signed an open letter calling for a six-month hiatus on the event of such techniques out of concern for societal welfare.
As we navigate the fourth industrial revolution, we discover ourselves at a juncture the place AI, together with LLMs, is reshaping sectors. However with new applied sciences come new challenges and dangers. Within the case of LLMs, these embody disuse—the untapped potential of opportune LLM purposes; misuse—dependence on LLMs the place their utilization could also be unwarranted; and abuse—exploitation of LLMs for malicious intent. To harness the benefits of LLMs whereas mitigating potential harms, it’s crucial to deal with these points.
This submit begins by describing the basic rules underlying LLMs. We then delve into a spread of sensible purposes, encompassing knowledge science, coaching and schooling, analysis, and strategic planning. Our goal is to show excessive leverage use-cases and establish methods to curtail misuse, abuse, and disuse, thus paving the way in which for extra knowledgeable and efficient use of this transformative know-how.
The Rise of GPT
On the coronary heart of ChatGPT is a sort of LLM known as a generative pretrained transformer (GPT). GPT-4 is the fourth in a sequence of GPT foundational fashions tracing again to 2018. Like its predecessor, GPT-4 can settle for textual content inputs, reminiscent of questions or requests, and produce written responses. Its competencies mirror the large corpora of information that it was educated with. GPT-4 reveals human-level efficiency on tutorial {and professional} benchmarks together with the Uniform Bar Examination, LSAT, SAT, GRE, and AP topic assessments. Furthermore, GPT-4 performs nicely on laptop coding issues, common sense reasoning, and sensible duties that require synthesizing data from many various sources. GPT-4 outperforms its predecessor in all these areas. Much more considerably, GPT-4 is multimodal, which means that it might settle for each textual content and picture inputs. This functionality permits GPT-4 to be utilized to completely new issues.
OpenAI facilitated public entry to GPT-4 through a chatbot named ChatGPT Plus, providing no-code choices for using GPT-4. They additional prolonged its attain by releasing a GPT-4 plugin, offering low-code choices for integrating it into enterprise purposes. These strikes by OpenAI have considerably lowered the limitations to adopting this transformative know-how. Concurrently, the emergence of open-source GPT-4 options reminiscent of LLaMA and Alpaca has catalyzed widespread experimentation and prototyping.
What are LLMs?
Though GPT-4 is new, language fashions are usually not. The complexity and richness of language is among the distinguishing traits of human cognition. Because of this, AI researchers have lengthy tried to emulate human language utilizing computer systems. Certainly, pure language processing (NLP) will be traced to the origins of AI. Within the 1950 article “Computing Equipment and Intelligence,” Alan Turning included automated era and understanding of human language as a criterion for AI.
Within the years since, NLP has undergone a number of paradigm shifts. Early work on symbolic NLP relied on hand-crafted guidelines. This reliance gave option to statistical NLP within the Nineteen Nineties, which used machine studying to deduce techniques of language a lot as people do. Advances in computing {hardware} and algorithms led to neural NLP within the 2010s. The household of strategies used for neural NLP—collectively generally known as deep studying—are extra versatile and expressive than ones used for statistical NLP. Additional advances in deep studying, together with the applying of those strategies to datasets a number of orders of magnitude bigger than what was beforehand doable, have now allowed pre-trained LLMs to satisfy the criterion issued by Turing in his seminal work on AI.
Essentially, immediately’s language fashions share an goal of historic NLP approaches—to foretell the subsequent phrase(s) in a sequence. This enables the mannequin to ‘rating’ the chance of various combos of phrases making up sentences. On this approach, language fashions can reply to human prompts in syntactically and semantically right methods.
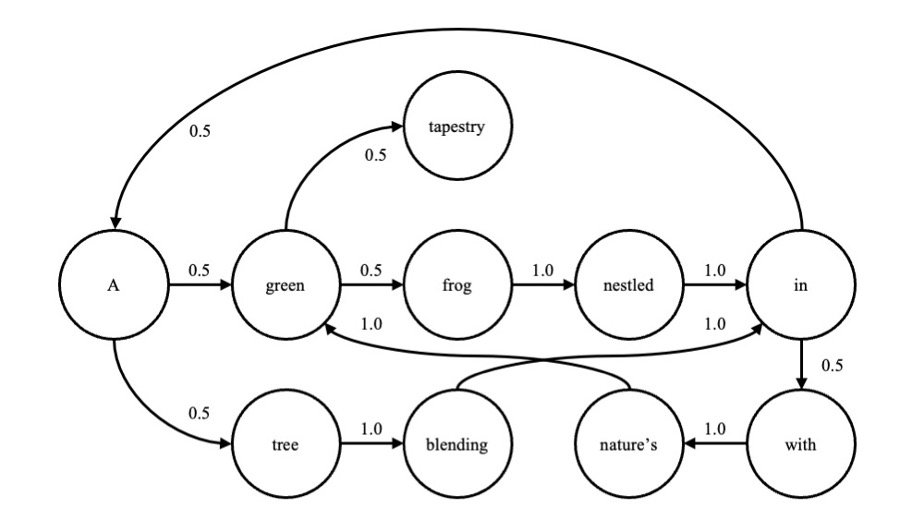
Think about the sentence, “A inexperienced frog nestled in a tree, mixing in with nature’s inexperienced tapestry.” By merging repeated phrases, it’s doable to create a graph of transition chances; that’s, the chance of every phrase given the earlier one (Determine 1).
{kind=link}
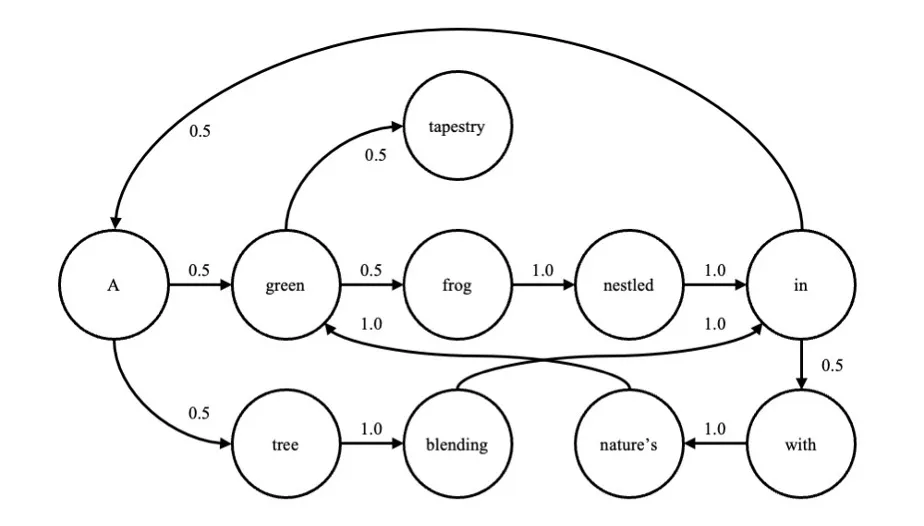
Determine 1: Easy Language Mannequin Representing Phrase Transition Chances
The graph will be expressed as
P(xn|xn-1).
These transition chances will be instantly approximated from a big corpus of textual content. In fact, the chance of every phrase will depend on extra than simply the earlier one. A extra full mannequin would calculate the chance given the earlier n phrases. For instance, for n = 10, this may be expressed as
P(xn|xn-1, xn-2, xn-3, xn-4, xn-5, xn-6, xn-7, xn-8, xn-9, xn-10).
Herein lies the problem. Because the size of the sequence will increase, the transition matrix turns into intractably massive. Furthermore, solely a small fraction of doable combos of phrases has occurred or will ever happen.
Neural networks are common operate approximators. Given sufficient hidden layers and models, a neural community can study to approximate an arbitrarily advanced operate, together with features just like the one proven above. This property of neural networks has led to their use in LLMs.
Parts of an LLM
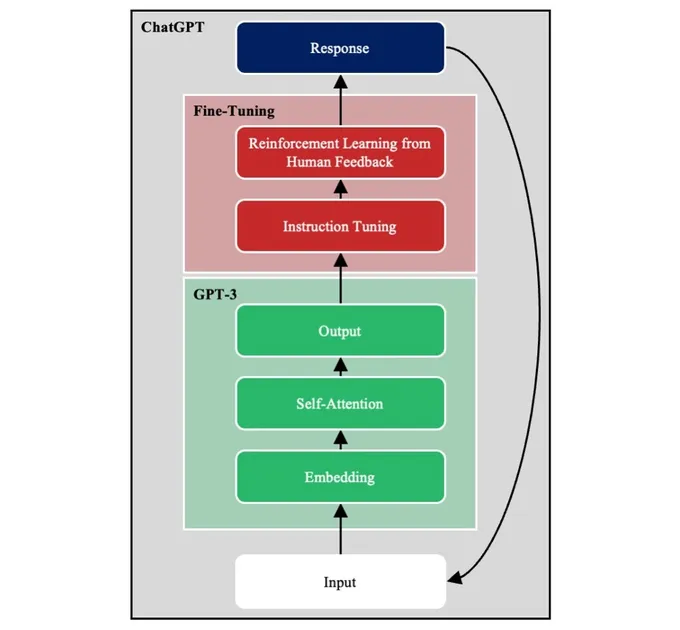
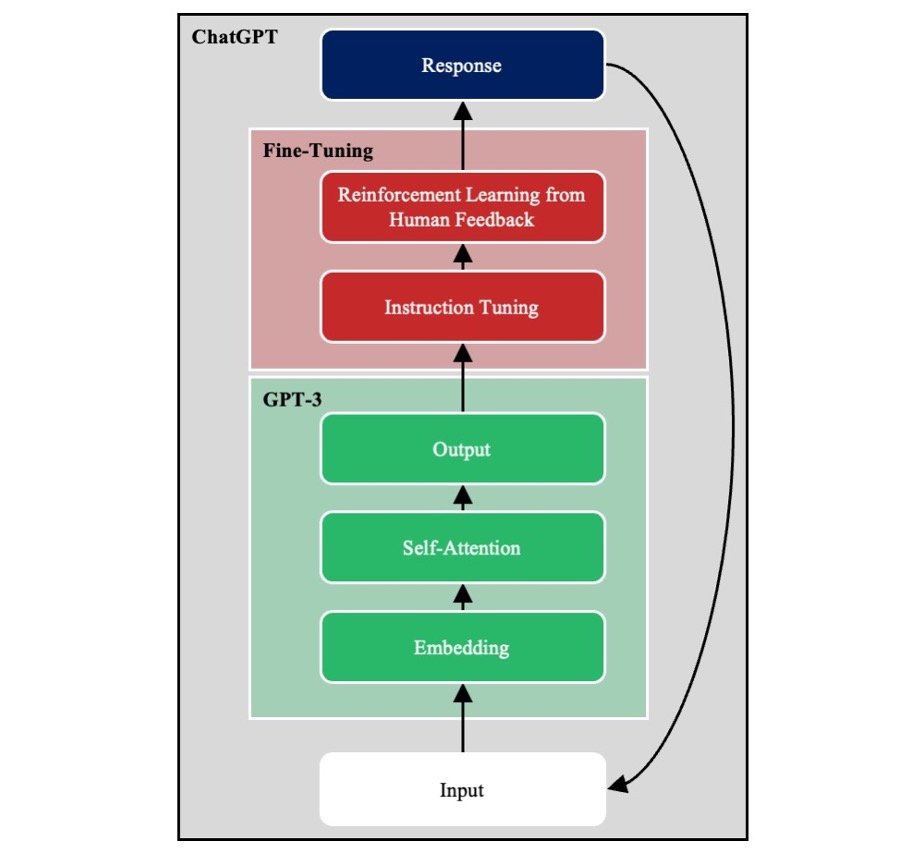
Determine 2 exhibits main elements of GPT-3, an exemplar LLM embedded within the conversational agent ChatGPT. We talk about every of those elements in flip.
{kind=link}
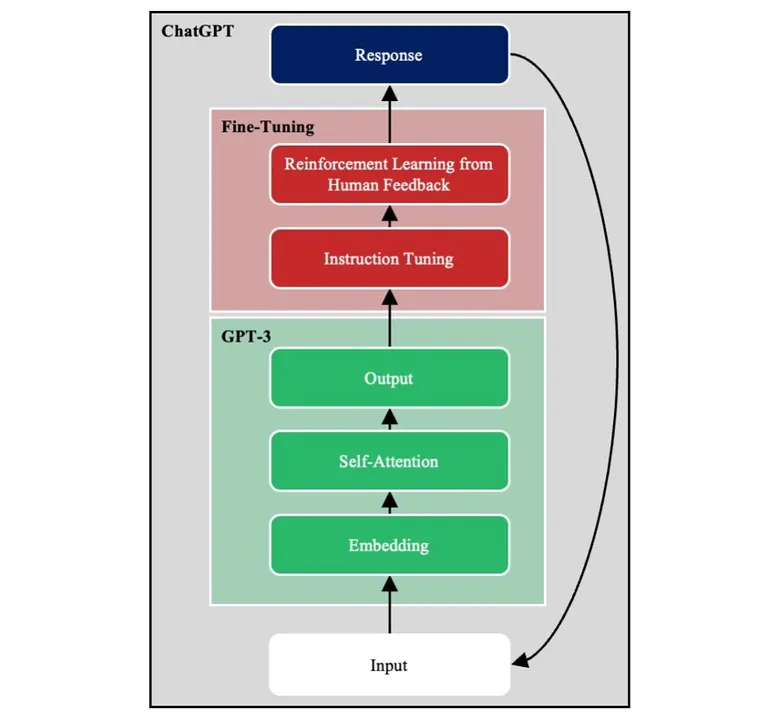
Determine 2: Primary Components of an LLM
Deep Neural Community
GPT-3 is a deep neural community (DNN). Its enter layer takes a passage of textual content damaged down into word-level tokens, and its output layer returns the possibilities of all doable phrases showing subsequent. The enter is remodeled throughout a sequence of hidden layers to supply the output.
GPT-3 is educated utilizing self-supervised studying. Passages from the coaching corpus are given as enter with the ultimate phrase masked, and the mannequin should predict the masked phrase. As a result of self-supervised studying doesn’t require labeled outputs, it permits fashions to be educated on vastly extra knowledge than could be doable utilizing supervised studying.
Textual content Embeddings
The English language alone accommodates lots of of 1000’s of phrases. GPT-3, like most different NLP fashions, initiatives phrase tokens onto embeddings. An embedding is a high-dimensional numeric vector that represents a phrase. At first look, it could appear pricey to characterize every phrase as a vector of lots of of numeric components. Actually, this course of compresses the enter from lots of of 1000’s of phrases to the lots of of dimensions that comprise the embedding house. Embeddings scale back the variety of downstream mannequin weights that have to be discovered. Furthermore, they protect similarities between phrases. Thus, the phrases Web and net are nearer to 1 one other within the embedding house than to the phrase plane.
Self-Consideration
GPT-3 is a transformer structure, which means that it makes use of self-attention. Think about the 2 sentences, “The investor went to the financial institution” and “The bear went to the financial institution.” The which means of financial institution will depend on whether or not the second phrase is investor or bear. To interpret the ultimate phrase, the mannequin should relate it to different phrases contained within the sentence.
Following the introduction of the transformer structure in 2017, self-attention has change into the popular option to seize long-range dependencies in language.[1] Self-attention copies the numeric vectors representing every phrase. Then, utilizing a set of discovered attentional weights, it adjusts the values for phrases primarily based on the encompassing ones (i.e., context). For instance, self-attention shifts the numeric illustration of financial institution towards a monetary establishment within the first sentence, and it shifts it towards a river within the second sentence.
Autoregression
GPT is an autoregressive mannequin (i.e., it’s educated to foretell the subsequent phrase in a passage). Different LLMs are educated to foretell randomly masked phrases masked throughout the physique of the passage. The selection between autoregression and masking relies upon partially on the aim of the LLM.
With one slight adjustment, an autoregressive mannequin can be utilized for pure language era. Throughout inference, GPT-3 is run a number of occasions. At every timestep, the output from the earlier timestep is appended to the enter, and GPT-3 is run once more. On this approach, GPT-3 completes its personal utterances.
Instruction Tuning
GPT-3 is educated to finish passages. Consequently, when GPT-3 receives the immediate, Write an essay on rising applied sciences that can rework manufacturing, GPT-3 could reply, The essay should comprise 500 phrases. This response could be anticipated if the coaching set included descriptions of faculty assignments. The problem is that sentence completion just isn’t clearly aligned with the human intent of query answering.
To beat this limitation, GPT-3 is augmented with instruction tuning. Particularly, a bunch of human specialists create pairs of prompts and idealized responses. This new coaching set is used for supervised fine-tuning (SFT). SFT higher aligns GPT-3 with human intentions.
Reinforcement Studying from Human Suggestions
Following SFT, further fine-tuning is carried out utilizing reinforcement studying from human suggestions (RLHF). Briefly, GPT-3 generates a number of doable responses to a immediate, which human raters rank from greatest to worst. These knowledge are used to create a reward mannequin that predicts the goodness of mannequin responses. The reward mannequin is then used to coach GPT-3 at scale to supply responses higher aligned with human intent.
Probably the most direct software of SFT and RLHF is to shift GPT-3 from sentence completion to query answering. Nonetheless, system designers produce other goals, reminiscent of minimizing the usage of bias language. By modeling acceptable responses with SFT, and by downvoting inappropriate ones with RLHF, designers can align GPT-3 to different goals, reminiscent of eradicating bias or bigoted responses.
Engineered and Emergent Talents of LLMs
A complete analysis of GPT exhibits that it incessantly produces syntactically and semantically right responses throughout a variety of textual content and laptop programming prompts. Thus, it might encode, retrieve, and apply pre-existing information, and it might talk that information in syntactically right methods.
Extra surprisingly, LLMs like GPT-3 present unanticipated emergent skills.
- in-context studying—GPT-3 considers the previous dialog to generate responses which can be aligned with the given context. Thus, relying on the previous dialog, GPT-3 can reply to the identical immediate in very other ways, which known as in-context studying as a result of GPT-3 modifies its habits with out requiring adjustments to its pre-trained weights.
- instruction following—Instruction following is an instance of in-context studying. Think about the 2 prompts, Write a poem; embody flour, egg, and sugar and Write a receipt; embody flour, eggs, and sugar. Instruction establishes context, which shapes GPT-3’s response. On this approach, GPT-3 can carry out new duties with out re-training.
- few-shot studying—Few-shot studying is one other instance of in-context studying. The person offers examples of the categories and type of desired outputs. Examples set up context, which once more permits GPT-3 to generalize to new duties with out re-training.
Immediate engineering refers to issuing prompts in a sure option to evoke several types of response. It’s one other instance of in-context studying. Nonetheless, the usage of SFT and RLHF in GPT-3 reduces the necessity for immediate engineering for frequent duties, reminiscent of query answering.
Trying Forward
The AI revolution represents an expansive evolution of machine automation, encompassing each routine and non-routine duties. Parasuraman’s cautionary notes on automation’s misuse and abuse prolong their relevance to AI, together with LLMs.
Inside our dialogue, we hinted on the potential for misuse of LLMs. For instance, human customers could inadvertently settle for factually incorrect responses from ChatGPT. Furthermore, LLMs will be topic to abuse. For instance, adversaries could use them to generate misinformation or to unleash new types of malware. To handle these dangers, a complete danger mitigation plan should embody strategic system design, end-user coaching, testing and analysis, in addition to sturdy protection mechanisms. Nonetheless, though dangers will be lowered, they can’t be eradicated.
Parasuraman additionally cautioned in opposition to disuse, or the failure to undertake automation when it could be useful to take action. As soon as once more, this warning extends to AI.
Within the subsequent submit in thie sequence, we’ll discover 4 case research that current highly effective alternatives for LLMs to reinforce human intelligence. Because the AI revolution unfolds, due to this fact, we should stay aware of potential harms, whereas equally recognizing and embracing the outstanding potential for societal advantages.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., & Amodei, D. (2020). Language fashions are few-shot learners. Advances in neural data processing techniques, 33, 1877-1901.
OpenAI. (2023). GPT-4 Technical report.
Parasuraman, R., & Riley, V. (1997). People and automation: Use, misuse, disuse, abuse. Human elements, 39(2), 230-253.
Schwab, Okay. (2017). The Fourth Industrial Revolution. Crown Publishing, New York, NY
Turing, A. (1950). Computing Equipment and Intelligence. Thoughts, LI(236), 433–460.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Consideration is all you want. Advances in neural data processing techniques, 30.
The Messy Center of Massive Language Fashions with Jay Palat and Rachel Dzombak