

Giant language fashions like Llama 2 and ChatGPT are the place a lot of the motion is in AI. However how effectively do at present’s information middle–class computer systems execute them? Fairly effectively, in keeping with the newest set of benchmark outcomes for machine studying, with the perfect in a position to summarize greater than 100 articles in a second. MLPerf’s twice-a-year information supply was launched on 11 September and included, for the primary time, a take a look at of a giant language mannequin (LLM), GPT-J. Fifteen laptop firms submitted efficiency outcomes on this first LLM trial, including to the greater than 13,000 different outcomes submitted by a complete of 26 firms. In one of many highlights of the data-center class, Nvidia revealed the primary benchmark outcomes for its Grace Hopper—an H100 GPU linked to the corporate’s new Grace CPU in the identical bundle as in the event that they had been a single “superchip.”
Generally referred to as “the Olympics of machine studying,” MLPerf consists of seven benchmark exams: picture recognition, medical-imaging segmentation, object detection, speech recognition, natural-language processing, a brand new recommender system, and now an LLM. This set of benchmarks examined how effectively an already-trained neural community executed on totally different laptop techniques, a course of referred to as inferencing.
[For more details on how MLPerf works in general, go here.]
The LLM, referred to as GPT-J and launched in 2021, is on the small facet for such AIs. It’s made up of some 6 billion parameters in comparison with GPT-3’s 175 billion. However going small was on goal, in keeping with MLCommons government director David Kanter, as a result of the group needed the benchmark to be achievable by a giant swath of the computing trade. It’s additionally in keeping with a development towards extra compact however nonetheless succesful neural networks.
This was model 3.1 of the inferencing contest, and as in earlier iterations, Nvidia dominated each within the variety of machines utilizing its chips and in efficiency. Nonetheless, Intel’s Habana Gaudi2 continued to nip on the Nvidia H100’s heels, and Qualcomm’s Cloud AI 100 chips made a powerful exhibiting in benchmarks centered on energy consumption.
Nvidia Nonetheless on Prime
This set of benchmarks noticed the arrival of the Grace Hopper superchip, an Arm-based 72-core CPU fused to an H100 via Nvidia’s proprietary C2C hyperlink. Most different H100 techniques depend on Intel Xeon or AMD Epyc CPUs housed in a separate bundle.
The closest comparable system to the Grace Hopper was an Nvidia DGX H100 laptop that mixed two Intel Xeon CPUs with an H100 GPU. The Grace Hopper machine beat that in each class by 2 to 14 %, relying on the benchmark. The largest distinction was achieved within the recommender system take a look at and the smallest distinction within the LLM take a look at.
Dave Salvatore, director of AI inference, benchmarking, and cloud at Nvidia, attributed a lot of the Grace Hopper benefit to reminiscence entry. By the proprietary C2C hyperlink that binds the Grace chip to the Hopper chip, the GPU can immediately entry 480 gigabytes of CPU reminiscence, and there may be a further 16 GB of high-bandwidth reminiscence hooked up to the Grace chip itself. (The subsequent era of Grace Hopper will add much more reminiscence capability, climbing to 140 GB from its 96 GB complete at present, Salvatore says.) The mixed chip may steer further energy to the GPU when the CPU is much less busy, permitting the GPU to ramp up its efficiency.
Moreover Grace Hopper’s arrival, Nvidia had its traditional superb exhibiting, as you may see within the charts beneath of all of the inference efficiency outcomes for information middle–class computer systems.
MLPerf Information-center Inference v3.1 Outcomes
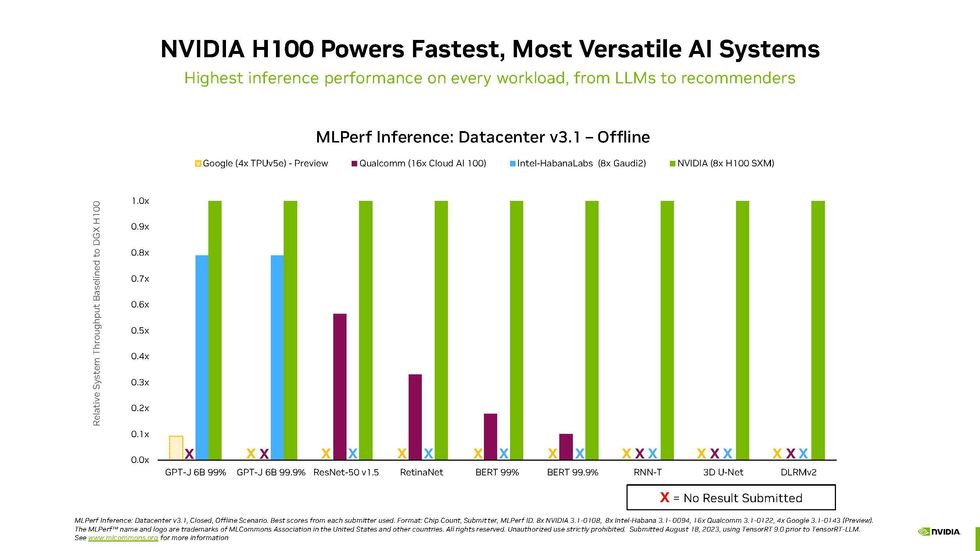
Nvidia continues to be the one to beat in AI inferencing.
Nvidia
Issues might get even higher for the GPU big. Nvidia introduced a brand new software program library that successfully doubled the H100’s efficiency on GPT-J. Known as TensorRT-LLM, it wasn’t prepared in time for MLPerf v3.1 exams, which had been submitted in early August. The important thing innovation is one thing referred to as inflight batching, says Salvatore. The work concerned in executing an LLM can range quite a bit. For instance, the identical neural community could be requested to show a 20-page article right into a one-page essay or summarize a one-page article in 100 phrases. TensorRT-LLM principally retains these queries from stalling one another, so small queries can get finished whereas huge jobs are in course of, too.

{kind=link}
Intel Closes In
Intel’s Habana Gaudi2 accelerator has been stalking the H100 in earlier rounds of benchmarks. This time, Intel solely trialed a single 2-CPU, 8-accelerator laptop and solely on the LLM benchmark. That system trailed Nvidia’s quickest machine by between 8 and 22 % on the job.
“In inferencing we’re at virtually parity with H100,” says Jordan Plawner, senior director of AI merchandise at Intel. Clients, he says, are coming to see the Habana chips as “the one viable various to the H100,” which is in enormously excessive demand.
He additionally famous that Gaudi2 is a era behind the H100 by way of chip-manufacturing know-how. The subsequent era will use the identical chip know-how as H100, he says.
Intel has additionally traditionally used MLPerf to point out how a lot could be finished utilizing CPUs alone, albeit CPUs that now include a devoted matrix-computation unit to assist with neural networks. This spherical was no totally different. Six techniques of two Intel Xeon CPUs every had been examined on the LLM benchmark. Whereas they didn’t carry out wherever close to GPU requirements—the Grace Hopper system was typically 10 occasions as quick as any of them and even quicker—they may nonetheless spit out a abstract each second or so.
Information-middle Effectivity Outcomes
Solely Qualcomm and Nvidia chips had been measured for this class. Qualcomm has beforehand emphasised its accelerators’ energy effectivity, however Nvidia H100 machines competed effectively, too.
From Your Web site Articles
Associated Articles Across the Internet