

{kind=link}
On the planet of information engineering, there are operations which were used for the reason that beginning of ETL. You filter. You be part of. You mixture. Lastly, you write the end result. Whereas these knowledge operations have remained the identical over time, the vary of latency and throughput necessities has modified dramatically. Processing a couple of occasions at a time or a pair gigabytes a day will not do. To fulfill in the present day’s enterprise necessities, terabytes and even petabytes of information should be processed every day, with job latencies measured in minutes and seconds.
Structured Streaming in Apache SparkTM is the main open supply stream processing engine, optimized for big knowledge volumes and low latency, and it’s the core expertise that makes the Databricks Lakehouse the most effective platform for streaming. Due to the improved performance being delivered with Challenge Lightspeed, now you’ll be able to carry out all of those basic knowledge operations inside a single stream.
Beginning in Databricks Runtime 13.1 and the upcoming Apache SparkTM 3.5.0 launch, a stream can include a number of stateful operators. There isn’t any longer a necessity to put in writing out to a sink after a be part of, then learn the information again into one other stream to mixture. Performing joins and aggregations inside one stream as a substitute of breaking it into a number of reduces complexity, latency, and value. On this put up we’ll give a quick overview of some stateful streaming ideas, after which we’ll dive proper into examples of this thrilling function!
What are Stateful Operators?
Structured Streaming performs operations on small batches of information at a time, known as microbatches. Operators in Structured Streaming could be damaged down into two classes – statemuch less and stateful.
Stateless streams carry out operations that don’t have to know something concerning the knowledge that got here in earlier microbatches. Filtering information to solely retain rows with values higher than 10, for instance, is stateless as a result of it doesn’t require information of any knowledge in addition to what’s being labored on in the mean time.
Stateful streams are performing operations that want extra data in addition to what’s within the present microbatch. If you wish to calculate a depend of values over 5-minute home windows, for instance, Structured Streaming wants to avoid wasting the operating depend for every key within the aggregation for five minutes-worth of information, regardless of what number of microbatches the information are unfold throughout. This saved knowledge is known as state, and operators that require saving state are stateful operators. The commonest stateful operators you will see are aggregations, joins and deduplication.
What are Watermarks?
All stateful operators in Structured Streaming require you to specify a watermark. A watermark provides you management over two issues – the allowed lateness of the information and the way lengthy to retain state.
Say we’re processing a dataset the place every of the information incorporates an occasion timestamp, and we’re aggregating over 5-minute home windows based mostly on that timestamp. What if some information arrive out of order? If a file with a timestamp of 12:04 arrives after we have processed information with a timestamp of 12:11, can we need to return and embody that file within the 12:00-12:05 aggregation? How lengthy can we need to settle for late knowledge and hold the state for that 12:00-12:05 window round? We do not need to hold state knowledge eternally – if we do not usually purge it, the state knowledge can ultimately refill reminiscence and trigger efficiency degradation. That is the place watermarks are available.
Through the use of the .withWatermark setting, you’ll be able to specify what number of seconds, minutes, hours or days late the information are allowed to be, and consequently allow Structured Streaming to know when information saved in state are not wanted. On this instance, we’re specifying that knowledge will probably be accepted as much as 10 minutes late, based mostly on the event_timestamp column within the knowledge:
.withWatermark("event_timestamp", "10 minutes")Structured Streaming calculates and saves a watermark timestamp on the finish of every microbatch by taking the most recent occasion timestamp that it obtained and subtracting the time interval specified within the withWatermark setting. Originally of every microbatch it compares the occasion timestamps of the incoming information and the information at the moment in state with the watermark timestamps. Enter information and state with timestamps which can be sooner than the watermark values are dropped.
This watermarking mechanism is what permits Structured Streaming to correctly deal with late information and state no matter what number of stateful operators are in a single stream. You will note watermarks in use within the examples under.
Examples
Now that you’ve the overall thought of what stateful operators are, we will present a few of them in motion. Let’s go over a pair examples of the best way to use a number of stateful operators in the identical stream.
Chained time window aggregations
On this instance, we’re receiving a stream of uncooked occasions. We need to depend the variety of occasions that occurred each 10 minutes by consumer, after which common these counts by hour earlier than writing out the end result. This can require chaining two windowed aggregations.
First we learn in our supply knowledge utilizing a typical readStream name, which is within the format of userId, eventTimestamp:
occasions = spark.readStream…Any of the streaming sources that include Structured Streaming can be utilized right here.
Subsequent, we carry out our first windowed aggregation on userId. Along with defining the timestamp column to base our window on and the window size, we have to outline a watermark to inform Structured Streaming how lengthy to attend for late knowledge earlier than emitting a end result and dropping the state. We have determined knowledge could be as much as one minute late. Right here is the code:
eventCount = occasions
.withWatermark("eventTimestamp", "1 minute")
.groupBy(
window(occasions.eventTimestamp, "10 minutes"),
occasions.userId
).depend()When doing a windowed aggregation, Structured Streaming routinely creates a window column within the end result. This window column is a struct with the beginning and finish timestamps that outline the window. After an hour, the output for userId 1 and a pair of appears one thing like this:
| window | userId | depend |
|---|---|---|
| {“begin”: “2023-06-02T11:00:00”, “finish”: “2023-06-02T11:10:00”} | 1 | 12 |
| {“begin”: “2023-06-02T11:00:00”, “finish”: “2023-06-02T11:10:00”} | 2 | 7 |
| {“begin”: “2023-06-02T11:10:00”, “finish”: “2023-06-02T11:20:00”} | 1 | 8 |
| {“begin”: “2023-06-02T11:10:00”, “finish”: “2023-06-02T11:20:00”} | 2 | 16 |
| {“begin”: “2023-06-02T11:20:00”, “finish”: “2023-06-02T11:30:00”} | 1 | 5 |
| {“begin”: “2023-06-02T11:20:00”, “finish”: “2023-06-02T11:30:00”} | 2 | 10 |
| {“begin”: “2023-06-02T11:30:00”, “finish”: “2023-06-02T11:40:00”} | 1 | 15 |
| {“begin”: “2023-06-02T11:30:00”, “finish”: “2023-06-02T11:40:00”} | 2 | 6 |
| {“begin”: “2023-06-02T11:40:00”, “finish”: “2023-06-02T11:50:00”} | 1 | 9 |
| {“begin”: “2023-06-02T11:40:00”, “finish”: “2023-06-02T11:50:00”} | 2 | 19 |
| {“begin”: “2023-06-02T11:50:00”, “finish”: “2023-06-02T12:00:00”} | 1 | 11 |
| {“begin”: “2023-06-02T11:50:00”, “finish”: “2023-06-02T12:00:00”} | 2 | 17 |
To be able to take these counts and common them by hour, we’ll have to outline one other windowed aggregation utilizing timestamps from the above window column. Earlier than we enabled a number of stateful operators, at this level you’ll have needed to write out the above end result to a sink with a writeStream, then learn the information into a brand new stream to carry out the second aggregation, as proven within the following diagram.
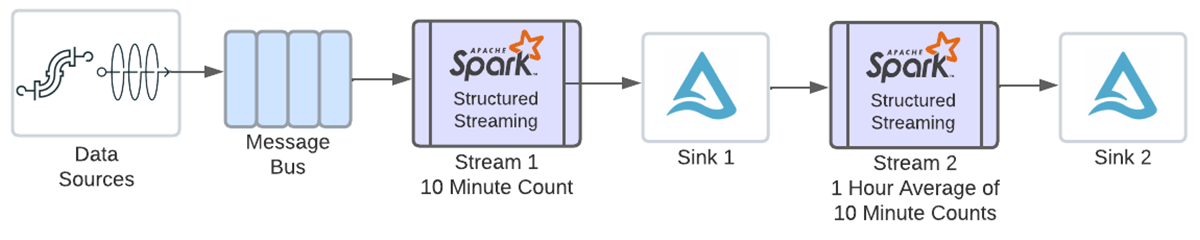
Due to this new function, now you can chain each operations in the identical stream.
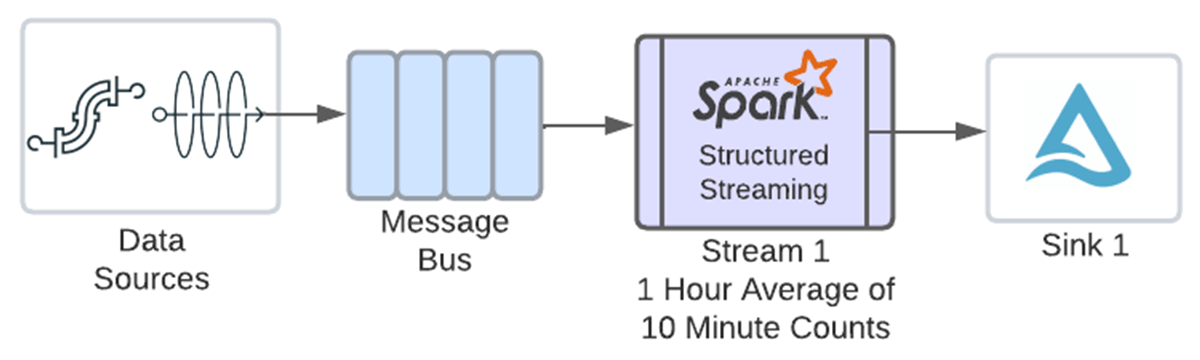
To let you simply chain windowed aggregations, we have added handy new syntax as a way to cross the window column created from the earlier aggregation on to the window operate. You may see the eventCount.window column being handed within the code under. The window operate will now correctly interpret the struct within the window column and let you create one other window with it. Right here is the second aggregation, which defines an hour window and averages the counts. Observe one other watermark doesn’t should be outlined, since we’re solely working with one enter supply and its watermark was specified earlier than the earlier aggregation:
eventAvg = eventCount
.groupBy(
window(eventCount.window, "1 hour"),
eventCount.userId
).avg(eventCount.depend)After our second aggregation, the information for userId 1 and a pair of would appear like this:
| window | userId | avg |
|---|---|---|
| {“begin”: “2023-06-02T11:00:00”, “finish”: “2023-06-02T12:00:00”} | 1 | 10 |
| {“begin”: “2023-06-02T11:00:00”, “finish”: “2023-06-02T12:00:00”} | 2 | 12.5 |
Lastly, we write the DataFrame out to a sink utilizing writeStream. On this instance we’re writing to a Delta desk:
eventAvg.writeStream
.outputMode("append")
.format("delta")
.choice("checkpointLocation",checkpointPath)
.set off(processingTime="30 seconds")
.queryName("eventRate")
.begin(outputPath)Any sink that helps the “append” output mode is supported. Since we’re utilizing append mode, the information just isn’t written to the sink for a given window till the window closes. The window is not going to shut till the watermark worth is later than the top of the window definition plus the allowed lateness time. For the instance hour window above, after we begin receiving knowledge with an occasion timestamp later than 12:01, the watermark worth will probably be later than the top of the outlined window plus the minute of allowed lateness. That can trigger the window to shut and the information to be emitted to the sink. The calculation of the watermark just isn’t associated to the clock time – it’s based mostly on the occasion timestamps within the knowledge that we’re receiving.
Stream-stream time interval be part of with a windowed aggregation
On this instance, we’re becoming a member of two streams collectively after which aggregating over a one hour window. We need to be part of the stream containing click on knowledge with the stream containing advert impressions, after which depend the variety of clicks per advert every hour.
A stream-stream be part of can also be a stateful operator. Data are saved in state for each be part of datasets as a result of matching information can come from totally different microbatches. We would like Structured Streaming to drop state information after a time period in order that the state would not develop indefinitely and trigger reminiscence and efficiency points. To ensure that that to occur, watermarks should be outlined on every enter stream and a time interval clause should be added to the be part of situation.
First, we learn in every dataset and apply a watermark. The watermarks for the 2 streams do not need to specify the identical time interval. On this instance we’re permitting impressions to reach as much as 2 hours late and clicks as much as 3 hours late:
impressions = spark.readStream…
clicks = spark.readStream…
impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")Now we be part of the 2 enter streams collectively. Right here is the code:
joined = impressionsWithWatermark.be part of(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
"leftOuter"
)Observe the time interval clause – that is saying {that a} click on should happen inside 0 seconds to 1 hour after the advert impression to ensure that it to be included within the ensuing be part of set. This time constraint can also be permitting Structured Streaming to find out when rows are not wanted in state.
As soon as now we have the joined dataset, we will depend the clicks that occurred throughout every hour for every advert. You do not need to specify one other watermark or add something extra to the aggregation operate – the second stateful operator simply works!
adCounts = joined.groupBy(
joined.clickAdId,
window(joined.clickTime, "1 hour")
).depend()Lastly, write out the end result. The writeStream syntax is similar as within the earlier instance, simply with a unique question title, output location and checkpoint location.
Advantages
So simply how does chaining a number of stateful operators scale back complexity, latency and value? Let’s use the above stream-stream be part of adopted by a windowed aggregation for instance.
Earlier than this function every stateful operator required its personal stream, so there could be a stream for the be part of and a second stream for the windowed aggregation that used the output of the primary stream as its enter. Even when each streams had been operating on the identical Spark cluster every stream would have its personal overhead, equivalent to checkpointing offset and commit logs and monitoring metrics for plotting on the Spark UI. The primary stream would learn within the supply knowledge, be part of it and write it out to a sink on exterior storage. Then the second stream would learn the joined knowledge again in, do the windowed aggregation and write the end result out to a different sink. The streams would each should be monitored, and the dependency between them must be managed any time there was a logic change in both stream.
Now that a number of stateful operators could be mixed, each the be part of and the windowed aggregation could be in the identical stream.
- Complexity is diminished as a result of now there is just one stream to watch and no dependencies between streams to handle. Additionally since just one dataset is being saved there may be much less knowledge to control.
- Latency is diminished as a result of each the write of the intermediate dataset after the be part of and the learn of that dataset earlier than the windowed aggregation are eradicated.
- Value is diminished as a result of the elimination of the intermediate write and browse and the discount of the streaming overhead scale back the quantity of compute that’s required. Any storage prices for the intermediate dataset are additionally eradicated.
Take into consideration how a lot complexity, latency and value could be diminished you probably have three, 4 or 5 stateful operators!
Further Concerns
When utilizing a number of stateful operators in a single stream, there are a number of belongings you want to remember.
- First, it’s essential to use the “append” output mode. The “replace” and “full” output modes can’t be used, even when the vacation spot sink helps them. Because you’re utilizing append mode, output is not going to be written to the sink for a windowed aggregation till the window finish timestamp is lower than the watermark. An unmatched outer be part of row is not going to be written till its occasion timestamp is lower than the watermark.
- Subsequent, the mapGroupsWithState, flatMapGroupsWithState and applyInPandasWithState operators can solely be mixed with different stateful operators if the arbitrary stateful operator is the final one within the stream. If you could carry out different stateful operations after mapGroupsWithState, flatMapGroupsWithState or applyInPandsWithState, it’s essential to write out your arbitrary stateful operations to a sink first, then use different stateful operators in a second stream.
- Lastly, keep in mind that that is stateful streaming, so whether or not you are utilizing one or a number of stateful operators in your stream the identical finest practices apply. If you’re saving a number of state, think about using RocksDB for state administration since it might preserve 100 occasions extra state keys than the default mechanism. When operating on the Databricks Lakehouse Platform, you may as well enhance stateful streaming efficiency by utilizing asynchronous checkpoints and state rebalancing.
Conclusion
To fulfill in the present day’s enterprise necessities, it is turning into essential to course of bigger volumes of information quicker than ever earlier than. With Challenge Lightspeed Databricks is regularly enhancing all features of Structured Streaming – latency, performance, connectors, and ease of deployment and monitoring. This newest enhancement in performance now permits customers of Structured Streaming to have a number of stateful operators inside a single stream, which reduces latency, complexity and value. Strive it out in the present day on the Databricks Lakehouse Platform in runtime 13.1 and above, or within the upcoming Apache SparkTM 3.5.0 launch!