
{kind=link}
The mix of the setting a person experiences and their genetic predispositions determines nearly all of their danger for numerous illnesses. Massive nationwide efforts, comparable to the UK Biobank, have created massive, public assets to higher perceive the hyperlinks between setting, genetics, and illness. This has the potential to assist people higher perceive keep wholesome, clinicians to deal with sicknesses, and scientists to develop new medicines.
One problem on this course of is how we make sense of the huge quantity of medical measurements — the UK Biobank has many petabytes of imaging, metabolic assessments, and medical information spanning 500,000 people. To greatest use this knowledge, we want to have the ability to signify the knowledge current as succinct, informative labels about significant illnesses and traits, a course of known as phenotyping. That’s the place we will use the power of ML fashions to choose up on refined intricate patterns in massive quantities of information.
We’ve beforehand demonstrated the power to make use of ML fashions to rapidly phenotype at scale for retinal illnesses. Nonetheless, these fashions had been educated utilizing labels from clinician judgment, and entry to clinical-grade labels is a limiting issue as a result of time and expense wanted to create them.
In “Inference of continual obstructive pulmonary illness with deep studying on uncooked spirograms identifies new genetic loci and improves danger fashions”, revealed in Nature Genetics, we’re excited to spotlight a technique for coaching correct ML fashions for genetic discovery of illnesses, even when utilizing noisy and unreliable labels. We show the power to coach ML fashions that may phenotype straight from uncooked medical measurement and unreliable medical report data. This lowered reliance on medical area consultants for labeling drastically expands the vary of purposes for our method to a panoply of illnesses and has the potential to enhance their prevention, prognosis, and remedy. We showcase this methodology with ML fashions that may higher characterize lung operate and continual obstructive pulmonary illness (COPD). Moreover, we present the usefulness of those fashions by demonstrating a greater capability to determine genetic variants related to COPD, improved understanding of the biology behind the illness, and profitable prediction of outcomes related to COPD.
ML for deeper understanding of exhalation
For this demonstration, we centered on COPD, the third main explanation for worldwide dying in 2019, wherein airway irritation and impeded airflow can progressively cut back lung operate. Lung operate for COPD and different illnesses is measured by recording a person’s exhalation quantity over time (the report is known as a spirogram; see an instance under). Though there are tips (known as GOLD) for figuring out COPD standing from exhalation, these use just a few, particular knowledge factors within the curve and apply mounted thresholds to these values. A lot of the wealthy knowledge from these spirograms is discarded on this evaluation of lung operate.
We reasoned that ML fashions educated to categorise spirograms would have the ability to use the wealthy knowledge current extra fully and lead to extra correct and complete measures of lung operate and illness, much like what we have now seen in different classification duties like mammography or histology. We educated ML fashions to foretell whether or not a person has COPD utilizing the total spirograms as inputs.
 |
| Spirometry and COPD standing overview. Spirograms from lung operate take a look at displaying a pressured expiratory volume-time spirogram (left), a pressured expiratory flow-time spirogram (center), and an interpolated pressured expiratory flow-volume spirogram (proper). The profile of people w/o COPD is totally different. |
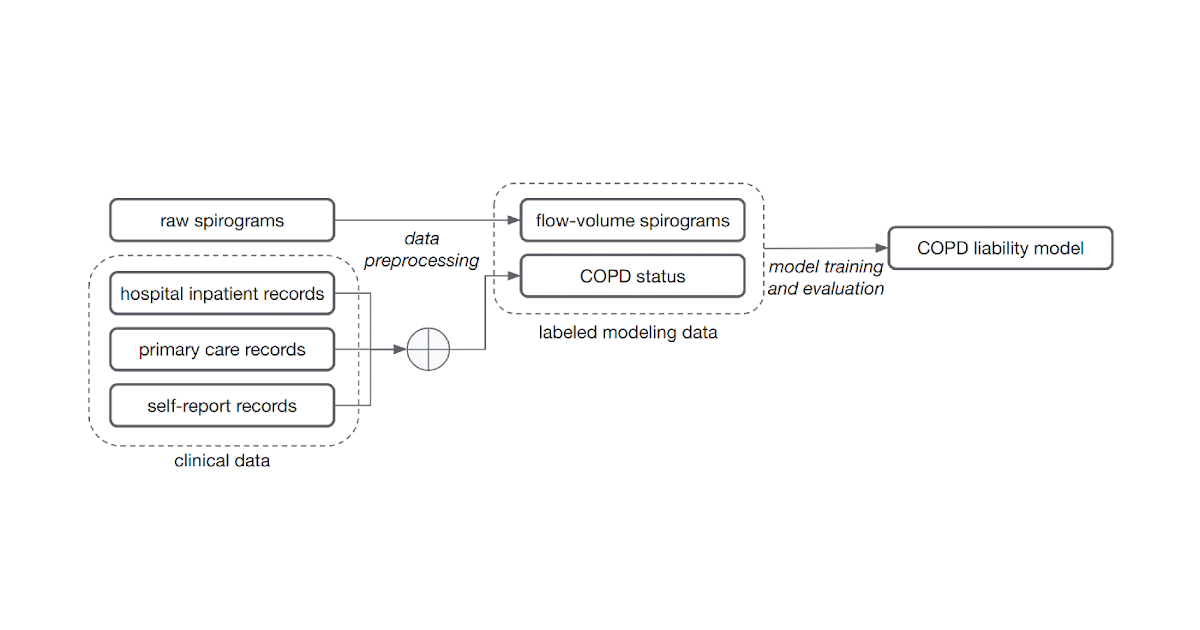
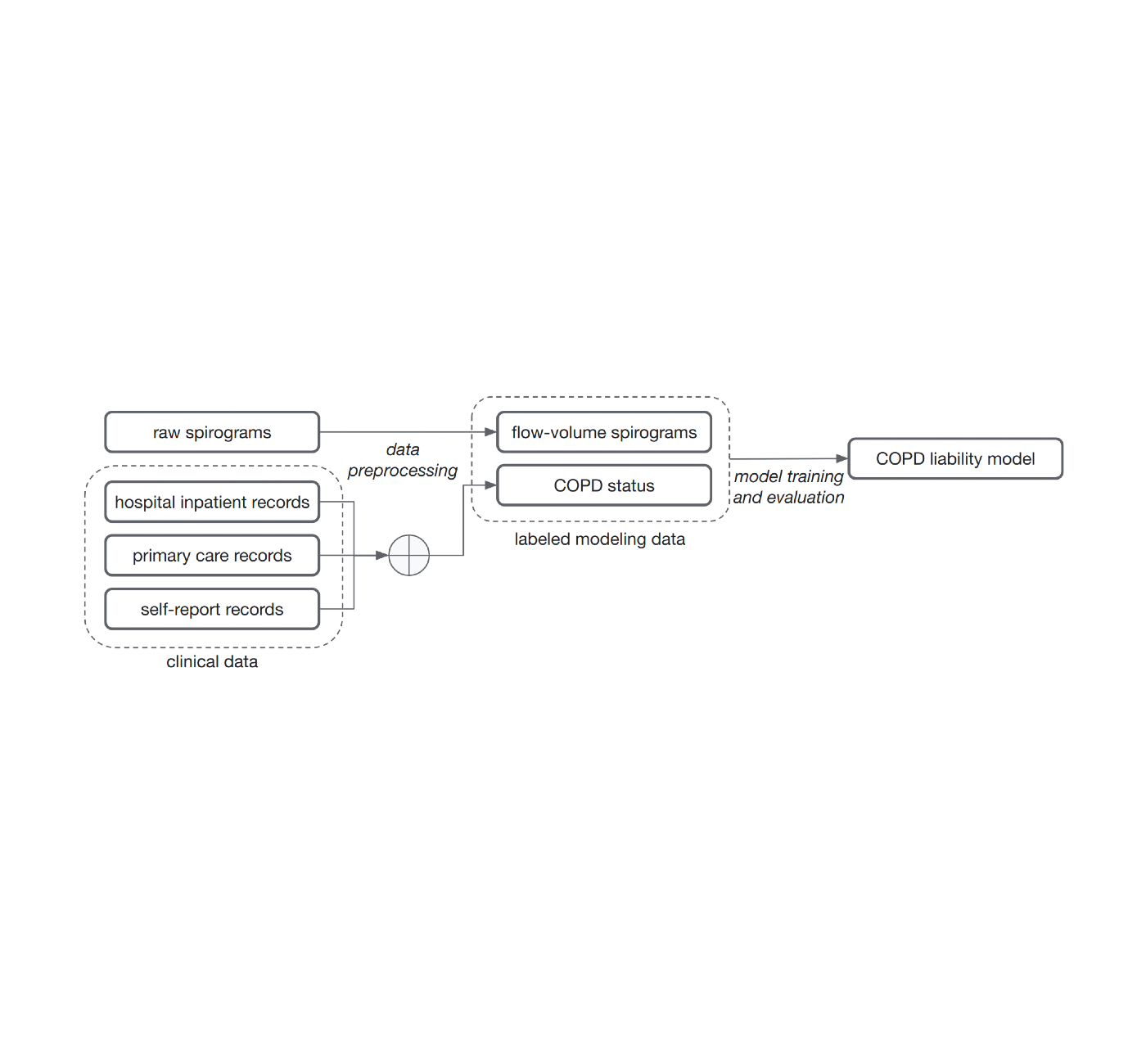
The widespread methodology of coaching fashions for this downside, supervised studying, requires samples to be related to labels. Figuring out these labels can require the trouble of very time-constrained consultants. For this work, to point out that we don’t essentially want medically graded labels, we determined to make use of a wide range of broadly out there sources of medical report data to create these labels with out medical knowledgeable evaluation. These labels are much less dependable and noisy for 2 causes. First, there are gaps within the medical information of people as a result of they use a number of well being companies. Second, COPD is commonly undiagnosed, that means many with the illness won’t be labeled as having it even when we compile the entire medical information. Nonetheless, we educated a mannequin to foretell these noisy labels from the spirogram curves and deal with the mannequin predictions as a quantitative COPD legal responsibility or danger rating.
 |
| Noisy COPD standing labels had been derived utilizing numerous medical report sources (medical knowledge). A COPD legal responsibility mannequin is then educated to foretell COPD standing from uncooked flow-volume spirograms. |
Predicting COPD outcomes
We then investigated whether or not the chance scores produced by our mannequin might higher predict a wide range of binary COPD outcomes (for instance, a person’s COPD standing, whether or not they had been hospitalized for COPD or died from it). For comparability, we benchmarked the mannequin relative to expert-defined measurements required to diagnose COPD, particularly FEV1/FVC, which compares particular factors on the spirogram curve with a easy mathematical ratio. We noticed an enchancment within the capability to foretell these outcomes as seen within the precision-recall curves under.
 |
| Precision-recall curves for COPD standing and outcomes for our ML mannequin (inexperienced) in comparison with conventional measures. Confidence intervals are proven by lighter shading. |
We additionally noticed that separating populations by their COPD mannequin rating was predictive of all-cause mortality. This plot means that people with larger COPD danger usually tend to die earlier from any causes and the chance most likely has implications past simply COPD.
 |
| Survival evaluation of a cohort of UK Biobank people stratified by their COPD mannequin’s predicted danger quartile. The lower of the curve signifies people within the cohort dying over time. For instance, p100 represents the 25% of the cohort with best predicted danger, whereas p50 represents the 2nd quartile. |
Figuring out the genetic hyperlinks with COPD
For the reason that purpose of enormous scale biobanks is to deliver collectively massive quantities of each phenotype and genetic knowledge, we additionally carried out a take a look at known as a genome-wide affiliation examine (GWAS) to determine the genetic hyperlinks with COPD and genetic predisposition. A GWAS measures the power of the statistical affiliation between a given genetic variant — a change in a selected place of DNA — and the observations (e.g., COPD) throughout a cohort of circumstances and controls. Genetic associations found on this method can inform drug growth that modifies the exercise or merchandise of a gene, in addition to broaden our understanding of the biology for a illness.
We confirmed with our ML-phenotyping methodology that not solely will we rediscover virtually all identified COPD variants discovered by handbook phenotyping, however we additionally discover many novel genetic variants considerably related to COPD. As well as, we see good settlement on the impact sizes for the variants found by each our ML strategy and the handbook one (R2=0.93), which gives sturdy proof for validity of the newly discovered variants.
 |
| Left: A plot evaluating the statistical energy of genetic discovery utilizing the labels for our ML mannequin (y-axis) with the statistical energy of the handbook labels from a conventional examine (x-axis). A price above the y = x line signifies larger statistical energy in our methodology. Inexperienced factors point out vital findings in our methodology that aren’t discovered utilizing the normal strategy. Orange factors are vital within the conventional strategy however not ours. Blue factors are vital in each. Proper: Estimates of the affiliation impact between our methodology (y-axis) and conventional methodology (x-axis). Be aware that the relative values between research are comparable however the absolute numbers will not be. |
Lastly, our collaborators at Harvard Medical College and Brigham and Girls’s Hospital additional examined the plausibility of those findings by offering insights into the doable organic function of the novel variants in growth and development of COPD (you possibly can see extra dialogue on these insights within the paper).
Conclusion
We demonstrated that our earlier strategies for phenotyping with ML may be expanded to a variety of illnesses and may present novel and worthwhile insights. We made two key observations through the use of this to foretell COPD from spirograms and discovering new genetic insights. First, area information was not essential to make predictions from uncooked medical knowledge. Apparently, we confirmed the uncooked medical knowledge might be underutilized and the ML mannequin can discover patterns in it that aren’t captured by expert-defined measurements. Second, we don’t want medically graded labels; as an alternative, noisy labels outlined from broadly out there medical information can be utilized to generate clinically predictive and genetically informative danger scores. We hope that this work will broadly broaden the power of the sector to make use of noisy labels and can enhance our collective understanding of lung operate and illness.
Acknowledgments
This work is the mixed output of a number of contributors and establishments. We thank all contributors: Justin Cosentino, Babak Alipanahi, Zachary R. McCaw, Cory Y. McLean, Farhad Hormozdiari (Google), Davin Hill (Northeastern College), Tae-Hwi Schwantes-An and Dongbing Lai (Indiana College), Brian D. Hobbs and Michael H. Cho (Brigham and Girls’s Hospital, and Harvard Medical College). We additionally thank Ted Yun and Nick Furlotte for reviewing the manuscript, Greg Corrado and Shravya Shetty for assist, and Howard Yang, Kavita Kulkarni, and Tammi Huynh for serving to with publication logistics.