
{kind=link}
Overview
The kerasformula bundle presents a high-level interface for the R interface to Keras. It’s fundamental interface is the kms operate, a regression-style interface to keras_model_sequential that makes use of formulation and sparse matrices.
The kerasformula bundle is out there on CRAN, and may be put in with:
# set up the kerasformula bundle
set up.packages("kerasformula")
# or devtools::install_github("rdrr1990/kerasformula")
library(kerasformula)
# set up the core keras library (if you have not already achieved so)
# see ?install_keras() for choices e.g. install_keras(tensorflow = "gpu")
install_keras()The kms() operate
Many basic machine studying tutorials assume that knowledge are available a comparatively homogenous type (e.g., pixels for digit recognition or phrase counts or ranks) which might make coding considerably cumbersome when knowledge is contained in a heterogenous knowledge body. kms() takes benefit of the pliability of R formulation to clean this course of.
kms builds dense neural nets and, after becoming them, returns a single object with predictions, measures of match, and particulars concerning the operate name. kms accepts a lot of parameters together with the loss and activation features present in keras. kms additionally accepts compiled keras_model_sequential objects permitting for even additional customization. This little demo exhibits how kms can support is mannequin constructing and hyperparameter choice (e.g., batch measurement) beginning with uncooked knowledge gathered utilizing library(rtweet).
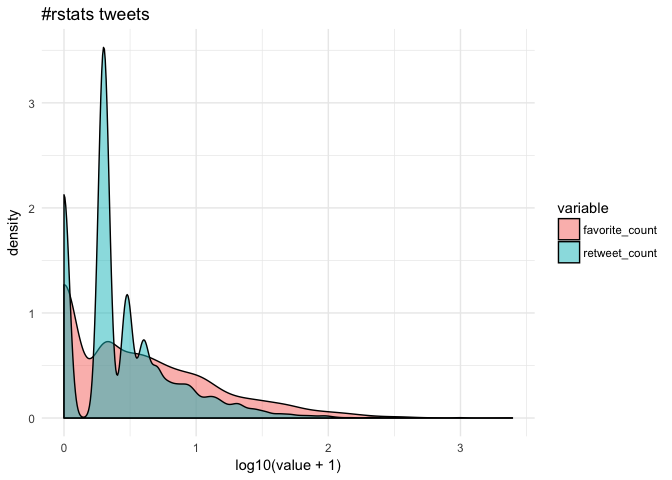
Let’s have a look at #rstats tweets (excluding retweets) for a six-day interval ending January 24, 2018 at 10:40. This occurs to present us a pleasant affordable variety of observations to work with when it comes to runtime (and the aim of this doc is to point out syntax, not construct significantly predictive fashions).
rstats <- search_tweets("#rstats", n = 10000, include_rts = FALSE)
dim(rstats) [1] 2840 42Suppose our aim is to foretell how well-liked tweets will likely be based mostly on how usually the tweet was retweeted and favorited (which correlate strongly).
cor(rstats$favorite_count, rstats$retweet_count, technique="spearman") [1] 0.7051952Since few tweeets go viral, the information are fairly skewed in the direction of zero.

Getting essentially the most out of formulation
Let’s suppose we’re eager about placing tweets into classes based mostly on reputation however we’re undecided how finely-grained we wish to make distinctions. A number of the knowledge, like rstats$mentions_screen_name is available in a listing of various lengths, so let’s write a helper operate to depend non-NA entries.
Let’s begin with a dense neural internet, the default of kms. We are able to use base R features to assist clear the information–on this case, reduce to discretize the result, grepl to search for key phrases, and weekdays and format to seize completely different features of the time the tweet was posted.
breaks <- c(-1, 0, 1, 10, 100, 1000, 10000)
reputation <- kms(reduce(retweet_count + favorite_count, breaks) ~ screen_name +
supply + n(hashtags) + n(mentions_screen_name) +
n(urls_url) + nchar(textual content) +
grepl('photograph', media_type) +
weekdays(created_at) +
format(created_at, '%H'), rstats)
plot(reputation$historical past)
+ ggtitle(paste("#rstat reputation:",
paste0(spherical(100*reputation$evaluations$acc, 1), "%"),
"out-of-sample accuracy"))
+ theme_minimal()
reputation$confusion
reputation$confusion
(-1,0] (0,1] (1,10] (10,100] (100,1e+03] (1e+03,1e+04]
(-1,0] 37 12 28 2 0 0
(0,1] 14 19 72 1 0 0
(1,10] 6 11 187 30 0 0
(10,100] 1 3 54 68 0 0
(100,1e+03] 0 0 4 10 0 0
(1e+03,1e+04] 0 0 0 1 0 0The mannequin solely classifies about 55% of the out-of-sample knowledge appropriately and that predictive accuracy doesn’t enhance after the primary ten epochs. The confusion matrix means that mannequin does greatest with tweets which might be retweeted a handful of instances however overpredicts the 1-10 degree. The historical past plot additionally means that out-of-sample accuracy isn’t very steady. We are able to simply change the breakpoints and variety of epochs.
breaks <- c(-1, 0, 1, 25, 50, 75, 100, 500, 1000, 10000)
reputation <- kms(reduce(retweet_count + favorite_count, breaks) ~
n(hashtags) + n(mentions_screen_name) + n(urls_url) +
nchar(textual content) +
screen_name + supply +
grepl('photograph', media_type) +
weekdays(created_at) +
format(created_at, '%H'), rstats, Nepochs = 10)
plot(reputation$historical past)
+ ggtitle(paste("#rstat reputation (new breakpoints):",
paste0(spherical(100*reputation$evaluations$acc, 1), "%"),
"out-of-sample accuracy"))
+ theme_minimal()
That helped some (about 5% extra predictive accuracy). Suppose we wish to add a bit extra knowledge. Let’s first retailer the enter formulation.
pop_input <- "reduce(retweet_count + favorite_count, breaks) ~
n(hashtags) + n(mentions_screen_name) + n(urls_url) +
nchar(textual content) +
screen_name + supply +
grepl('photograph', media_type) +
weekdays(created_at) +
format(created_at, '%H')"Right here we use paste0 so as to add to the formulation by looping over consumer IDs including one thing like:
grepl("12233344455556", mentions_user_id)mentions <- unlist(rstats$mentions_user_id)
mentions <- distinctive(mentions[which(table(mentions) > 5)]) # take away rare
mentions <- mentions[!is.na(mentions)] # drop NA
for(i in mentions)
pop_input <- paste0(pop_input, " + ", "grepl(", i, ", mentions_user_id)")
reputation <- kms(pop_input, rstats)
That helped a contact however the predictive accuracy remains to be pretty unstable throughout epochs…
Customizing layers with kms()
We might add extra knowledge, maybe add particular person phrases from the textual content or another abstract stat (imply(textual content %in% LETTERS) to see if all caps explains reputation). However let’s alter the neural internet.
The enter.formulation is used to create a sparse mannequin matrix. For instance, rstats$supply (Twitter or Twitter-client software kind) and rstats$screen_name are character vectors that will likely be dummied out. What number of columns does it have?
[1] 1277Say we wished to reshape the layers to transition extra step by step from the enter form to the output.

kms builds a keras_sequential_model(), which is a stack of linear layers. The enter form is decided by the dimensionality of the mannequin matrix (reputation$P) however after that customers are free to find out the variety of layers and so forth. The kms argument layers expects a listing, the primary entry of which is a vector items with which to name keras::layer_dense(). The primary ingredient the variety of items within the first layer, the second ingredient for the second layer, and so forth (NA as the ultimate ingredient connotes to auto-detect the ultimate variety of items based mostly on the noticed variety of outcomes). activation can be handed to layer_dense() and should take values comparable to softmax, relu, elu, and linear. (kms additionally has a separate parameter to manage the optimizer; by default kms(... optimizer="rms_prop").) The dropout that follows every dense layer price prevents overfitting (however in fact isn’t relevant to the ultimate layer).
Selecting a Batch Measurement
By default, kms makes use of batches of 32. Suppose we have been pleased with our mannequin however didn’t have any explicit instinct about what the dimensions ought to be.
Nbatch <- c(16, 32, 64)
Nruns <- 4
accuracy <- matrix(nrow = Nruns, ncol = size(Nbatch))
colnames(accuracy) <- paste0("Nbatch_", Nbatch)
est <- listing()
for(i in 1:Nruns){
for(j in 1:size(Nbatch)){
est[[i]] <- kms(pop_input, rstats, Nepochs = 2, batch_size = Nbatch[j])
accuracy[i,j] <- est[[i]][["evaluations"]][["acc"]]
}
}
colMeans(accuracy) Nbatch_16 Nbatch_32 Nbatch_64
0.5088407 0.3820850 0.5556952 For the sake of curbing runtime, the variety of epochs was set arbitrarily brief however, from these outcomes, 64 is the most effective batch measurement.
Making predictions for brand spanking new knowledge
So far, we’ve been utilizing the default settings for kms which first splits knowledge into 80% coaching and 20% testing. Of the 80% coaching, a sure portion is put aside for validation and that’s what produces the epoch-by-epoch graphs of loss and accuracy. The 20% is barely used on the finish to evaluate predictive accuracy.
However suppose you wished to make predictions on a brand new knowledge set…
reputation <- kms(pop_input, rstats[1:1000,])
predictions <- predict(reputation, rstats[1001:2000,])
predictions$accuracy [1] 0.579As a result of the formulation creates a dummy variable for every display screen title and point out, any given set of tweets is all however assured to have completely different columns. predict.kms_fit is an S3 technique that takes the brand new knowledge and constructs a (sparse) mannequin matrix that preserves the unique construction of the coaching matrix. predict then returns the predictions together with a confusion matrix and accuracy rating.
In case your newdata has the identical noticed ranges of y and columns of x_train (the mannequin matrix), you may as well use keras::predict_classes on object$mannequin.
Utilizing a compiled Keras mannequin
This part exhibits tips on how to enter a mannequin compiled within the style typical to library(keras), which is helpful for extra superior fashions. Right here is an instance for lstm analogous to the imbd with Keras instance.
okay <- keras_model_sequential()
okay %>%
layer_embedding(input_dim = reputation$P, output_dim = reputation$P) %>%
layer_lstm(items = 512, dropout = 0.4, recurrent_dropout = 0.2) %>%
layer_dense(items = 256, activation = "relu") %>%
layer_dropout(0.3) %>%
layer_dense(items = 8, # variety of ranges noticed on y (consequence)
activation = 'sigmoid')
okay %>% compile(
loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = c('accuracy')
)
popularity_lstm <- kms(pop_input, rstats, okay)Drop me a line through the challenge’s Github repo. Particular due to @dfalbel and @jjallaire for useful ideas!!