
{kind=link}
Introduction
Massive Language Fashions like langchain and deep lake have come a good distance in Doc Q&A and data retrieval. These fashions know loads in regards to the world, however typically, they battle to know after they don’t know one thing. This leads them to make issues as much as fill the gaps, which isn’t nice.

Nevertheless, a brand new methodology referred to as Retrieval Augmented Era (RAG) appears promising. Use RAG to question an LLM together with your non-public data base. It helps these fashions get higher by including additional info from their information sources. This makes them extra modern and helps scale back their errors after they don’t have sufficient info.
RAG works by enhancing prompts with proprietary information, in the end enhancing the data of those massive language fashions whereas concurrently lowering the prevalence of hallucinations.
Studying Goals
1. Understanding of the RAG strategy and its advantages
2. Acknowledge the challenges in Doc QnA
3. Distinction between Easy Era and Retrieval Augmented Era
4. Sensible implementation of RAG on an business use case like Doc-QnA
By the tip of this studying article, it is best to have a strong understanding of Retrieval Augmented Era (RAG) and its utility in enhancing the efficiency of LLMs in Doc Query Answering and Info Retrieval.
This text was revealed as part of the Information Science Blogathon.
Getting Began
Concerning Doc Query Answering, the perfect answer is to present the mannequin the particular info it wants proper when requested a query. Nevertheless, deciding what info is related could be difficult and is determined by what the big language mannequin is anticipated to do. That is the place the idea of RAG turns into necessary.
Allow us to see how a RAG pipeline works:
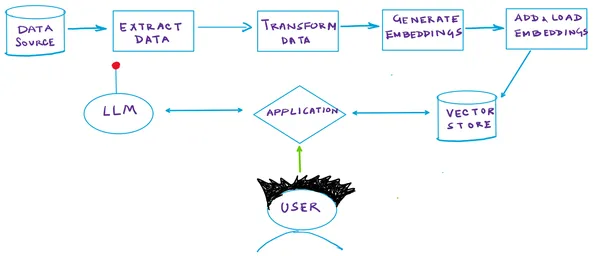
Retrieval Augmented Era
RAG, a cutting-edge generative AI structure, employs semantic similarity to establish pertinent info in response to queries autonomously. Right here’s a concise breakdown of how RAG features:
- Vector Database: In a RAG system, your paperwork are saved inside a specialised Vector DB. Every doc undergoes indexing based mostly on a semantic vector generated by an embedding mannequin. This strategy permits fast retrieval of paperwork carefully associated to a given question vector. Every doc is assigned a numerical illustration (the vector), signifying its semantic that means.
- Question Vector Era: When a question is submitted, the identical embedding mannequin produces a semantic vector that represents the question.
- Vector-Based mostly Retrieval: Subsequently, the mannequin makes use of vector search to establish paperwork throughout the DB that exhibit vectors carefully aligned with the question’s vector. This step is essential in pinpointing probably the most related paperwork.
- Response Era: After retrieving the pertinent paperwork, the mannequin employs them with the question to generate a response. This technique empowers the mannequin to entry exterior information exactly when required, augmenting its inner data.
The Illustration
The illustration beneath sums up the complete steps mentioned above:
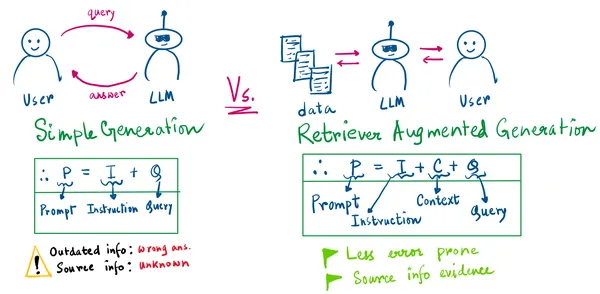
From the drawing above, there are 2 necessary issues to pinpoint :
- Within the Easy era, we’ll by no means know the supply info.
- Easy generation can result in flawed info era when the mannequin is outdated, or its data cutoff is earlier than the question is requested.
With the RAG strategy, our LLM’s immediate would be the instruction given by us, the retrieved context, and the person’s question. Now, we have now the proof of the data retrieved.
So, as a substitute of taking the effort of retraining the pipeline a number of instances to an ever-changing info situation, you may add up to date info to your vector shops/information shops. The person can come subsequent time and ask related questions whose solutions have now modified (take an instance of some finance data of an XYZ agency). You might be all set.
Hope this refreshes your thoughts on how RAG works. Now, let’s get to the purpose. Sure, the code.
I do know you didn’t come right here for the small speak. 👻
Let’s Skip to the Good Half!
1: Making the VSCode Undertaking Construction
Open VSCode or your most well-liked code editor and create a undertaking listing as follows (rigorously observe the folder construction) –
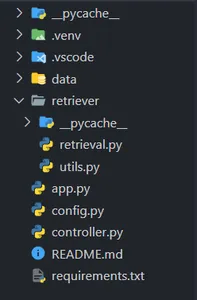
Keep in mind to create a digital atmosphere with Python ≥ 3.9 and set up the dependencies within the necessities.txt file. (Don’t fear, I’ll share the GitHub hyperlink for the sources.)
2: Making a Class for Retrieval and Embedding Operations
Within the controller.py file, paste the code beneath and reserve it.
from retriever.retrieval import Retriever
# Create a Controller class to handle doc embedding and retrieval
class Controller:
def __init__(self):
self.retriever = None
self.question = ""
def embed_document(self, file):
# Embed a doc if 'file' is offered
if file will not be None:
self.retriever = Retriever()
# Create and add embeddings for the offered doc file
self.retriever.create_and_add_embeddings(file.title)
def retrieve(self, question):
# Retrieve textual content based mostly on the person's question
texts = self.retriever.retrieve_text(question)
return texts
This can be a helper class for creating an object of our Retriever. It implements two features –
embed_document: generates the embeddings of the doc
retrieve: retrieves textual content when the person asks a question
Down the lane, we’ll get deeper into the create_and_add_embeddings and retrieve_text helper features in our Retriever!
3: Coding our Retrieval pipeline!
Within the retrieval.py file, paste the code beneath and reserve it.
3.1: Import the mandatory libraries and modules
import os
from langchain import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyMuPDFLoader
from langchain.chat_models.openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.reminiscence import ConversationBufferWindowMemory
from .utils import save
import config as cfg3.2: Initialize the Retriever Class
# Outline the Retriever class
class Retriever:
def __init__(self):
self.text_retriever = None
self.text_deeplake_schema = None
self.embeddings = None
self.reminiscence = ConversationBufferWindowMemory(ok=2, return_messages=True)csv3.3: Let’s write the code for creating and including the doc embeddings to Deep Lake
def create_and_add_embeddings(self, file):
# Create a listing named "information" if it would not exist
os.makedirs("information", exist_ok=True)
# Initialize embeddings utilizing OpenAIEmbeddings
self.embeddings = OpenAIEmbeddings(
openai_api_key=cfg.OPENAI_API_KEY,
chunk_size=cfg.OPENAI_EMBEDDINGS_CHUNK_SIZE,
)
# Load paperwork from the offered file utilizing PyMuPDFLoader
loader = PyMuPDFLoader(file)
paperwork = loader.load()
# Cut up textual content into chunks utilizing CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=cfg.CHARACTER_SPLITTER_CHUNK_SIZE,
chunk_overlap=0,
)
docs = text_splitter.split_documents(paperwork)
# Create a DeepLake schema for textual content paperwork
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
embedding_function=self.embeddings,
overwrite=True,
)
# Add the break up paperwork to the DeepLake schema
self.text_deeplake_schema.add_documents(docs)
# Create a textual content retriever from the DeepLake schema with search kind "similarity"
self.text_retriever = self.text_deeplake_schema.as_retriever(
search_type="similarity"
)
# Configure search parameters for the textual content retriever
self.text_retriever.search_kwargs["distance_metric"] = "cos"
self.text_retriever.search_kwargs["fetch_k"] = 15
self.text_retriever.search_kwargs["maximal_marginal_relevance"] = True
self.text_retriever.search_kwargs["k"] = 3
3.4: Now, let’s code the perform that may retrieve textual content!
def retrieve_text(self, question):
# Create a DeepLake schema for textual content paperwork in read-only mode
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
read_only=True,
embedding_function=self.embeddings,
)
# Outline a immediate template for giving instruction to the mannequin
prompt_template = """You might be a complicated AI able to analyzing textual content from
paperwork and offering detailed solutions to person queries. Your objective is to
supply complete responses to remove the necessity for customers to revisit
the doc. In the event you lack the reply, please acknowledge it somewhat than
making up info.
{context}
Query: {query}
Reply:
"""
# Create a PromptTemplate with the "context" and "query"
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# Outline chain kind
chain_type_kwargs = {"immediate": PROMPT}
# Initialize the ChatOpenAI mannequin
mannequin = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key=cfg.OPENAI_API_KEY,
)
# Create a RetrievalQA occasion of the mannequin
qa = RetrievalQA.from_chain_type(
llm=mannequin,
chain_type="stuff",
retriever=self.text_retriever,
return_source_documents=False,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
reminiscence=self.reminiscence,
)
# Question the mannequin with the person's query
response = qa({"question": question})
# Return response from llm
return response["result"]
4: Utility perform to question our pipeline and extract the outcome
Paste the beneath code in your utils.py file :
def save(question, qa):
# Use the get_openai_callback perform
with get_openai_callback() as cb:
# Question the qa object with the person's query
response = qa({"question": question}, return_only_outputs=True)
# Return the reply from the llm's response
return response["result"]5: A config file for storing your keys….nothing fancy!
Paste the beneath code in your config.py file :
import os
OPENAI_API_KEY = os.getenv(OPENAI_API_KEY)
TEXT_VECTORSTORE_PATH = "datadeeplake_text_vectorstore"
CHARACTER_SPLITTER_CHUNK_SIZE = 75
OPENAI_EMBEDDINGS_CHUNK_SIZE = 16Lastly, we are able to code our Gradio app for the demo!!
6: The Gradio app!
Paste the next code in your app.py file :
# Import needed libraries
import os
from controller import Controller
import gradio as gr
# Disable tokenizers parallelism for higher efficiency
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Initialize the Controller class
controller = Controller()
# Outline a perform to course of the uploaded PDF file
def process_pdf(file):
if file will not be None:
controller.embed_document(file)
return (
gr.replace(seen=True),
gr.replace(seen=True),
gr.replace(seen=True),
gr.replace(seen=True),
)
# Outline a perform to reply to person messages
def reply(message, historical past):
botmessage = controller.retrieve(message)
historical past.append((message, botmessage))
return "", historical past
# Outline a perform to clear the dialog historical past
def clear_everything():
return (None, None, None)
# Create a Gradio interface
with gr.Blocks(css=CSS, title="") as demo:
# Show headings and descriptions
gr.Markdown("# AskPDF ", elem_id="app-title")
gr.Markdown("## Add a PDF and Ask Questions!", elem_id="select-a-file")
gr.Markdown(
"Drop an fascinating PDF and ask questions on it!",
elem_id="select-a-file",
)
# Create the add part
with gr.Row():
with gr.Column(scale=3):
add = gr.File(label="Add PDF", kind="file")
with gr.Row():
clear_button = gr.Button("Clear", variant="secondary")
# Create the chatbot interface
with gr.Column(scale=6):
chatbot = gr.Chatbot()
with gr.Row().fashion(equal_height=True):
with gr.Column(scale=8):
query = gr.Textbox(
show_label=False,
placeholder="e.g. What's the doc about?",
strains=1,
max_lines=1,
).fashion(container=False)
with gr.Column(scale=1, min_width=60):
submit_button = gr.Button(
"Ask me 🤖", variant="major", elem_id="submit-button"
)
# Outline buttons
add.change(
fn=process_pdf,
inputs=[upload],
outputs=[
question,
clear_button,
submit_button,
chatbot,
],
api_name="add",
)
query.submit(reply, [question, chatbot], [question, chatbot])
submit_button.click on(reply, [question, chatbot], [question, chatbot])
clear_button.click on(
fn=clear_everything,
inputs=[],
outputs=[upload, question, chatbot],
api_name="clear",
)
# Launch the Gradio interface
if __name__ == "__main__":
demo.launch(enable_queue=False, share=False)
Seize your🧋, trigger now it’s time to see how our pipeline works!
To launch the Gradio app, open a brand new terminal occasion and enter the next command:
python app.pyBe aware: Make sure the digital atmosphere is activated, and you’re within the present undertaking listing.
Gradio will begin a brand new occasion of your utility within the localhost server as follows:

All it is advisable do is CTRL + click on on the localhost URL (final line), and your app will open in your browser.
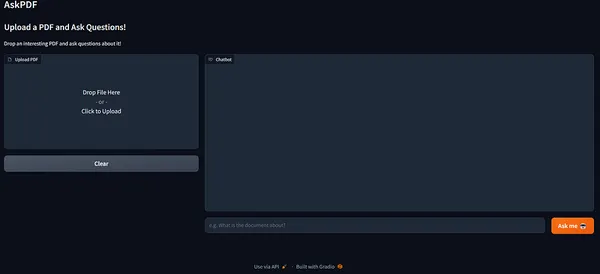
YAY!
Our Gradio App is right here!
Let’s drop an fascinating PDF! I’ll use Harry Potter’s Chapter 1 pdf from this Kaggle repository containing Harry Potter books in .pdf format for chapters 1 to 7.
Lumos! Might the sunshine be with you🪄
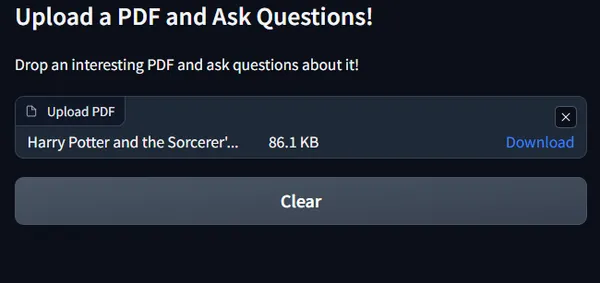
Now, as quickly as you add, the textual content field to ask a question can be activated as follows:

Let’s get to probably the most awaited half now — Quizzing!
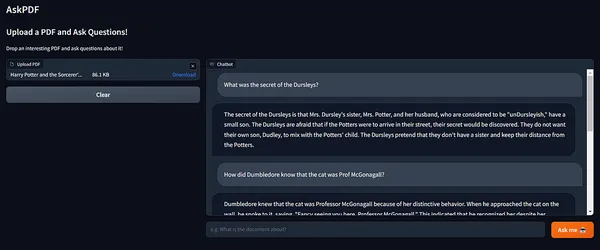
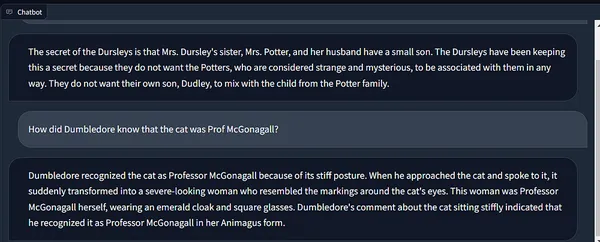
Wow! 😲
I really like how correct the solutions are!
Additionally, have a look at how Langchain’s reminiscence maintains the chain state, incorporating context from previous runs.
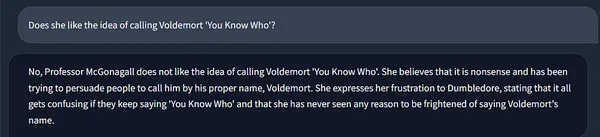
It remembers that she right here is our beloved Professor McGonagall! ❤️🔥
A Brief Demo of How the App Works!
RAG’s sensible and accountable strategy could be extraordinarily helpful to information scientists throughout numerous analysis areas to construct correct and accountable AI merchandise.
1. In healthcare analysis, Implement RAG to help docs and scientists in diagnosing complicated medical situations by integrating affected person data, medical literature, analysis papers, and journals into the data base, which can assist retrieve up-to-date info when making important selections and analysis in healthcare.
2. In buyer assist, corporations can readily use RAG-powered conversational AI chatbots to assist resolve buyer inquiries, complaints, and details about merchandise and manuals, FAQs from a non-public product, and buy order info database by offering correct responses, bettering the shopper expertise!
3. In fintech, analysts can incorporate real-time monetary information, market information, and historic inventory costs into their data base, and an RAG framework will shortly reply effectively to queries about market developments, firm financials, funding, and revenues, aiding sturdy and accountable decision-making.
4. Within the ed-tech market, E-learning platforms can have RAG-made chatbots deployed to assist college students resolve their queries by offering recommendations, complete solutions, and options based mostly on an unlimited repository of textbooks, analysis articles, and academic sources. This permits college students to deepen their understanding of topics with out requiring intensive handbook analysis.
The scope is limitless!
Conclusion
On this article, we explored the mechanics of RAG with Langchain and Deep Lake, the place semantic similarity performs a pivotal function in pinpointing related info. With vector databases, question vector era, and vector-based retrieval, these fashions entry exterior information exactly when wanted.
The outcome? Extra exact, contextually acceptable responses enriched with proprietary information. Hope you preferred it and realized one thing in your means! Be happy to obtain the entire code from my GitHub repo, to strive it out.
Key Takeaways
- Introduction to RAG: Retrieval Augmented Era (RAG) is a promising method in Massive Language Fashions (LLMs) that enhances their data by including additional info from their very own information sources, making them smarter and lowering errors after they lack info.
- Challenges in Doc QnA: Massive Language Fashions have made important progress in Doc Query and Answering (QnA) however can typically battle to discern after they lack info, resulting in errors.
- RAG Pipeline: The RAG pipeline employs semantic similarity to establish related question info. It entails a Vector Database, Question Vector Era, Vector-Based mostly Retrieval, and Response Era, in the end offering extra exact and contextually acceptable responses.
- Advantages of RAG: RAG permits fashions to supply proof for the data they retrieve, lowering the necessity for frequent retraining in quickly altering info situations.
- Sensible Implementation: The article gives a sensible information to implementing the RAG pipeline, together with establishing the undertaking construction, making a retrieval and embedding class, coding the retrieval pipeline, and constructing a Gradio app for real-time interactions.
Incessantly Requested Questions
A1: Retrieval Augmented Era (RAG) is a cutting-edge method utilized in Massive Language Fashions (LLMs) that enhances their data and reduces errors in doc question-answering. It entails retrieving related info from information sources to supply context for producing correct responses.
A2: RAG is necessary for LLMs as a result of it helps them enhance their efficiency by including additional info from their information sources. This extra context makes LLMs smarter and reduces their errors after they lack enough info.
A3: The RAG pipeline entails a number of steps:
Vector Database: Retailer paperwork in a specialised Vector Database, and every doc is listed based mostly on a semantic vector generated by an embedding mannequin.
Question Vector Era: If you submit a question, the identical embedding mannequin generates a semantic vector representing the question.
Vector-Based mostly Retrieval: The mannequin makes use of vector search to establish paperwork within the database with vectors carefully aligned with the question’s vector, pinpointing probably the most related paperwork.
Response Era: After retrieving pertinent paperwork, the mannequin combines them with the question to generate a response, accessing exterior information as wanted. This course of enhances the mannequin’s inner data.
A4: The RAG strategy affords a number of advantages, together with:
Extra Exact Responses: RAG permits LLMs to ship extra exact and contextually acceptable responses by incorporating proprietary information from vector-search-enabled databases.
Lowered Errors: By offering proof for retrieved info, RAG reduces errors and eliminates the necessity for frequent retraining in quickly altering info situations.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.