

{kind=link}
Whereas conversational AI has garnered a variety of media consideration in latest months, the capabilities of huge language fashions (LLMs) prolong properly past conversational interactions. It is in these much less outstanding capabilities resembling question response, summarization, classification and search that many organizations are discovering instant alternatives to supercharge their workforce and up-level buyer experiences.
The potential of those purposes is staggering. By one estimate, LLMs (and different generative AI applied sciences) may, within the close to future, handle duties that at the moment occupy 60-70% of staff’ time. By way of augmentation, quite a few research have proven that the time to finish varied duties carried out by data employees resembling background analysis, information evaluation and doc writing may be minimize in half. And nonetheless different research have proven that the usage of these applied sciences can dramatically cut back the time for brand new employees to realize full productiveness.
However earlier than these advantages may be totally realized, organizations should first rethink the administration of the unstructured info property on which these fashions rely and discover methods to mitigate the problems of bias and accuracy that have an effect on their output. For this reason so many organizations are at the moment focusing their efforts on targeted, inner purposes the place a restricted scope supplies alternatives for higher info entry and human oversight can function a test to errant outcomes. These purposes, aligned with core capabilities already residing throughout the group, have the potential to ship actual and instant worth, whereas LLMs and their supporting applied sciences proceed to evolve and mature.
Product Overview Summarization Might Use a Increase
As an example the potential of a extra targeted method to LLM adoption, we contemplate a reasonably easy and customary activity carried out inside many on-line retail organizations: product overview summarization. In the present day, most organizations make use of a modestly-sized group of workers to learn and digest person suggestions for insights that will assist enhance a product’s efficiency or in any other case establish points associated to buyer satisfaction.
The work is essential however something however horny. A employee reads a overview, takes notes, and strikes on to the subsequent. Particular person evaluations that require a response are flagged and a abstract of the suggestions from throughout a number of evaluations are compiled for overview by product or class managers.
It is a sort of labor that is ripe for automation. The quantity of evaluations that pour right into a web site imply the extra detailed parts of this work are sometimes carried out on a restricted subset of merchandise throughout variable home windows relying on a merchandise significance. In additional refined organizations, guidelines detecting course or inappropriate language and fashions estimating person sentiment or in any other case classifying evaluations for optimistic, unfavourable or impartial experiences could also be utilized to assist establish problematic content material and draw a reviewer’s consideration to it. However both method, lots is missed just because we won’t throw sufficient our bodies on the downside to maintain up and people our bodies are likely to turn into bored or fatigued with the monotony of the work.
Massive Language Fashions Can Automate Product Overview Evaluation
However utilizing an LLM, problems with scale and consistency may be simply addressed. All we have to do is deliver the product evaluations to the mannequin and ask:
- What are the highest three factors of unfavourable suggestions discovered throughout these evaluations?
- What options do our clients like finest about this product?
- Do clients really feel they’re receiving adequate worth from the product relative to what they’re being requested to pay?
- Are there any evaluations which are particularly unfavourable or are utilizing inappropriate language?
Inside seconds we are able to have a tidy response, permitting our product managers to give attention to responding to points as an alternative of merely detecting them.
However what about the issue of accuracy and bias? Requirements for figuring out inaccuracies and bias in LLM output are evolving as are strategies for higher making certain that outputs align with a company’s expectations, and the fine-tuning of fashions utilizing authorised content material can go a great distance to make sure fashions have a choice to generate content material that is not less than aligned with how a company prefers to speak.
It is a long-winded method of claiming there isn’t a excellent resolution to the issue as of but. However when in comparison with the place we’re with human-driven processes and extra simplistic fashions or rules-based approaches, the outcomes are anticipated to be higher or at a minimal no worse than what we at the moment expertise. And on condition that these overview summaries are for inner consumption, the impression of an errant mannequin may be simply managed.
You Can Construct A Resolution For This In the present day
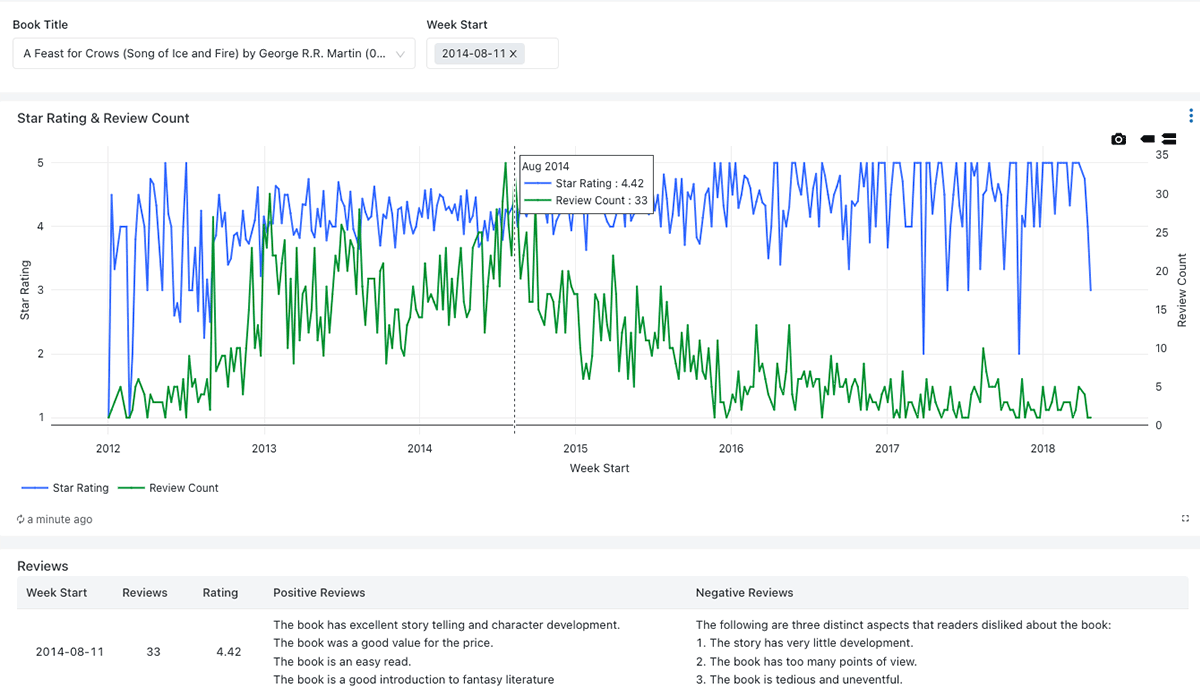
To display precisely how this work may very well be carried out, we’ve got constructed a resolution accelerator for summarizing product evaluations. That is based mostly closely on a beforehand printed weblog from Sean Owen that addressed a few of the core technical challenges of tuning an LLM on the Databricks platform. For the accelerator, we’re utilizing the Amazon Product Critiques Dataset, which comprises 51-million user-generated evaluations throughout 2-million distinct books as this supplies entry to a variety of reviewer content material and presents a scaling problem many organizations will acknowledge.
We think about a situation during which a workforce of product managers receives buyer suggestions by means of on-line evaluations. These evaluations are essential for figuring out points that will should be addressed relating to a selected merchandise and for steering future books to be provided by the positioning. With out the usage of know-how, this workforce struggles to learn all of the suggestions and summarize right into a workable set notes. Because of this, they restrict their consideration to only probably the most important objects and are in a position to solely course of the suggestions on a sporadic foundation.
However utilizing Databricks, they’re able to arrange a pipeline to gather suggestions from a wider vary of merchandise and summarize these regularly. Recognizing that positively rated merchandise are prone to spotlight the strengths of those books whereas decrease rated merchandise are prone to give attention to their weaknesses, they separate these evaluations based mostly on user-provided scores and activity an LLM to extract completely different units of knowledge from every high-level class of evaluations.
Abstract metrics are supplied to permit product managers an summary of the suggestions obtained and are backed by extra detailed summaries generated by the LLM. (Determine 1)
Databricks Brings Collectively All of the Parts of a Resolution
The situation demonstrated above depends upon the usage of an LLM. In months prior, the usage of such an LLM required entry to specialised computational infrastructures, however with advances within the open supply neighborhood and investments within the Databricks platform, we are actually in a position to run the LLM in our native Databricks setting.
On this explicit situation, the sensitivity of the information was not a motivating issue for this selection. As a substitute, we discovered that the amount of evaluations to be processed tipped the price scales in direction of the usage of Databricks, permitting us to trim about one-third of the price of implementing an identical resolution utilizing a third-party service.
As well as, we discovered that by implementing our personal infrastructure, we have been in a position to scale the setting up for sooner processing, tackling as many as 760,000 evaluations per hour in a single check with out having to be involved with constraints imposed by an exterior service. Whereas most organizations won’t have the necessity to scale fairly to that stage, it is good to know it’s there ought to it’s.
However this resolution is extra than simply an LLM. To deliver collectively the entire resolution we would have liked to develop a knowledge processing workflow to obtain incoming evaluations, put together them for submission to the mannequin and to seize mannequin output for additional evaluation. As a unified information platform, Databricks supplies us the means to deal with each information engineering and information science necessities with out information replication. And once we are completed processing the evaluations, our analysts can use their instruments of selection to question the output and make enterprise choices. By way of Databricks, we’ve got entry to the total array of capabilities for us to construct an answer aligned with our enterprise’s wants.