
{kind=link}
Availability is crucial function
— Mike Fisher, former CTO of Etsy
“I get knocked down, however I stand up once more…”
— Tubthumping, Chumbawumba
Each group pays consideration to resilience. The massive query is
when.
Startups are inclined to solely handle resilience when their techniques are already
down, usually taking a really reactive strategy. For a scaleup, extreme system
downtime represents a major bottleneck to the group, each from
the hassle expended on restoring perform and in addition from the impression of buyer
dissatisfaction.
To maneuver previous this, resilience must be constructed into the enterprise
aims, which is able to affect the structure, design, product
administration, and even governance of enterprise techniques. On this article, we’ll
discover the Resilience and Observability Bottleneck: how one can acknowledge
it coming, the way you may understand it has already arrived, and what you are able to do
to outlive the bottleneck.
How did you get into the bottleneck?
One of many first targets of a startup is getting an preliminary product out
to market. Getting it in entrance of as many customers as attainable and receiving
suggestions from them is usually the best precedence. If prospects use
your product and see the distinctive worth it delivers, your startup will carve
out market share and have a reliable income stream. Nevertheless, getting
there usually comes at a price to the resilience of your product.
A startup might determine to skip automating restoration processes, as a result of at
a small scale, the group believes it will possibly present resilience by means of
the builders that know the system nicely. Incidents are dealt with in a
reactive nature, and resolutions come by hand. Potential options is perhaps
spinning up one other occasion to deal with elevated load, or restarting a
service when it’s failing. Your first prospects may even pay attention to
your lack of true resilience as they expertise system outages.
At one in every of our scaleup engagements, to get the system out to manufacturing
rapidly, the shopper deprioritized well being verify mechanisms within the
cluster. The builders managed the startup course of efficiently for the
few occasions when it was vital. For an vital demo, it was determined to
spin up a brand new cluster in order that there can be no externalities impacting
the system efficiency. Sadly, actively managing the standing of all
the companies operating within the cluster was neglected. The demo began
earlier than the system was totally operational and an vital part of the
system failed in entrance of potential prospects.
Basically, your group has made an express trade-off
prioritizing user-facing performance over automating resilience,
playing that the group can get better from downtime by means of guide
intervention. The trade-off is probably going acceptable as a startup whereas it’s
at a manageable scale. Nevertheless, as you expertise excessive development charges and
rework from a
startup to a scaleup, the shortage of resilience proves to be a scaling
bottleneck, manifesting as an rising prevalence of service
interruptions translating into extra work on the Ops facet of the DevOps
staff’s tasks, lowering the productiveness of groups. The impression
appears to seem out of the blue, as a result of the impact tends to be non-linear
relative to the expansion of the client base. What was just lately manageable
is out of the blue extraordinarily impactful. Finally, the dimensions of the system
creates guide work past the capability of your staff, which bubbles as much as
have an effect on the client experiences. The mix of lowered productiveness
and buyer dissatisfaction results in a bottleneck that’s onerous to
survive.
The query then is, how do I do know if my product is about to hit a
scaling bottleneck? And additional, if I learn about these indicators, how can I
keep away from or maintain tempo with my scale? That’s what we’ll look to reply as we
describe widespread challenges we’ve skilled with our shoppers and the
options we’ve seen to be simplest.
Indicators you might be approaching a scaling bottleneck
It is at all times tough to function in an setting by which the dimensions
of the enterprise is altering quickly. Investing in dealing with excessive site visitors
volumes too early is a waste of sources. Investing too late means your
prospects are already feeling the results of the scaling bottleneck.
To shift your working mannequin from reactive to proactive, you need to
be capable to predict future conduct with a confidence degree enough to
assist vital enterprise choices. Making information pushed choices is
at all times the objective. The bottom line is to seek out the main indicators which is able to
information you to arrange for, and hopefully keep away from the bottleneck, reasonably than
react to a bottleneck that has already occurred. Primarily based on our expertise,
we’ve discovered a set of indicators associated to the widespread preconditions as
you strategy this bottleneck.
Resilience will not be a first-class consideration
This can be the least apparent signal, however is arguably crucial.
Resilience is regarded as purely a technical downside and never a function
of the product. It’s deprioritized for brand new options and enhancements. In
some instances, it’s not even a priority to be prioritized.
Right here’s a fast take a look at. Pay attention to the totally different discussions that
happen inside your groups, and observe the context by which resilience is
mentioned. You might discover that it isn’t included as a part of a standup, however
it does make its method right into a developer assembly. When the event staff isn’t
answerable for operations, resilience is successfully siloed away.
In these instances, pay shut consideration to how resilience is mentioned.
Proof of insufficient give attention to resilience is usually oblique. At one
shopper, we’ve seen it come within the type of technical debt playing cards that not
solely aren’t prioritized, however develop into a continuing rising checklist. At one other
shopper, the operations staff had their backlog stuffed purely with
buyer incidents, the vast majority of which handled the system both
not being up or being unable to course of requests. When resilience considerations
usually are not a part of a staff’s backlog and roadmap, you’ll have proof that
it’s not core to the product.
Fixing resilience by hand (reactive guide resilience)
How your group resolve service outages generally is a key indicator
of whether or not your product can scaleup successfully or not. The traits
we describe listed below are basically attributable to a
lack of automation, leading to extreme guide effort. Are service
outages resolved through restarts by builders? Below excessive load, is there
coordination required to scale compute situations?
Basically, we discover
these approaches don’t observe sustainable operational practices and are
brittle options for the following system outage. They embody bandaid options
which alleviate a symptom, however by no means actually resolve it in a method that permits
for future resilience.
Possession of techniques usually are not nicely outlined
When your group is transferring rapidly, growing new companies and
capabilities, very often key items of the service ecosystem, and even
the infrastructure, can develop into “orphaned” – with out clear accountability
for operations. Consequently, manufacturing points might stay unnoticed till
prospects react. Once they do happen, it takes longer to troubleshoot which
causes delays in resolving outages. Decision is delayed whereas ping ponging points
between groups in an effort to seek out the accountable celebration, losing
everybody’s time as the difficulty bounces from staff to staff.
This downside will not be distinctive to microservice environments. At one
engagement, we witnessed comparable conditions with a monolith structure
missing clear possession for components of the system. On this case, readability
of possession points stemmed from a scarcity of clear system boundaries in a
“ball of mud” monolith.
Ignoring the truth of distributed techniques
A part of growing efficient techniques is having the ability to outline and use
abstractions that allow us to simplify a fancy system to the purpose
that it really matches within the developer’s head. This permits builders to
make choices concerning the future adjustments essential to ship new worth
and performance to the enterprise. Nevertheless, as in all issues, one can go
too far, not realizing that these simplifications are literally
assumptions hiding essential constraints which impression the system.
Riffing off the fallacies of distributed computing:
- The community will not be dependable.
- Your system is affected by the velocity of sunshine. Latency is rarely zero.
- Bandwidth is finite.
- The community will not be inherently safe.
- Topology at all times adjustments, by design.
- The community and your techniques are heterogeneous. Completely different techniques behave
in another way beneath load. - Your digital machine will disappear whenever you least anticipate it, at precisely the
flawed time. - As a result of folks have entry to a keyboard and mouse, errors will
occur. - Your prospects can (and can) take their subsequent motion in <
500ms.
Fairly often, testing environments present good world
circumstances, which avoids violating these assumptions. Methods which
don’t account for (and take a look at for) these real-world properties are
designed for a world by which nothing dangerous ever occurs. Consequently,
your system will exhibit unanticipated and seemingly non-deterministic
conduct because the system begins to violate the hidden assumptions. This
interprets into poor efficiency for purchasers, and extremely tough
troubleshooting processes.
Not planning for potential site visitors
Estimating future site visitors quantity is tough, and we discover that we
are flawed extra usually than we’re proper. Over-estimating site visitors means
the group is losing effort designing for a actuality that doesn’t
exist. Below-estimating site visitors may very well be much more catastrophic. Sudden
excessive site visitors hundreds may occur for quite a lot of causes, and a social media advertising
marketing campaign which unexpectedly goes viral is an efficient instance. Immediately your
system can’t handle the incoming site visitors, elements begin to fall over,
and every thing grinds to a halt.
As a startup, you’re at all times seeking to appeal to new prospects and achieve
further market share. How and when that manifests may be extremely
tough to foretell. On the scale of the web, something may occur,
and you must assume that it’ll.
Alerted through buyer notifications
When prospects are invested in your product and imagine the difficulty is
resolvable, they could attempt to contact your assist employees for
assist. Which may be by means of electronic mail, calling in, or opening a assist
ticket. Service failures trigger spikes in name quantity or electronic mail site visitors.
Your gross sales folks might even be relaying these messages as a result of
(potential) prospects are telling them as nicely. And if service outages
have an effect on strategic prospects, your CEO may let you know immediately (this can be
okay early on, nevertheless it’s actually not a state you wish to be in long run).
Buyer communications is not going to at all times be clear and simple, however
reasonably shall be based mostly on a buyer’s distinctive expertise. If buyer success employees
don’t understand that these are indications of resilience issues,
they may proceed with enterprise as common and your engineering employees will
not obtain the suggestions. Once they aren’t recognized and managed
appropriately, notifications might then flip non-verbal. For instance, you could
out of the blue discover the speed at which prospects are canceling subscriptions
will increase.
When working with a small buyer base, understanding about an issue
by means of your prospects is “largely” manageable, as they’re pretty
forgiving (they’re on this journey with you in any case). Nevertheless, as
your buyer base grows, notifications will start to pile up in the direction of
an unmanageable state.
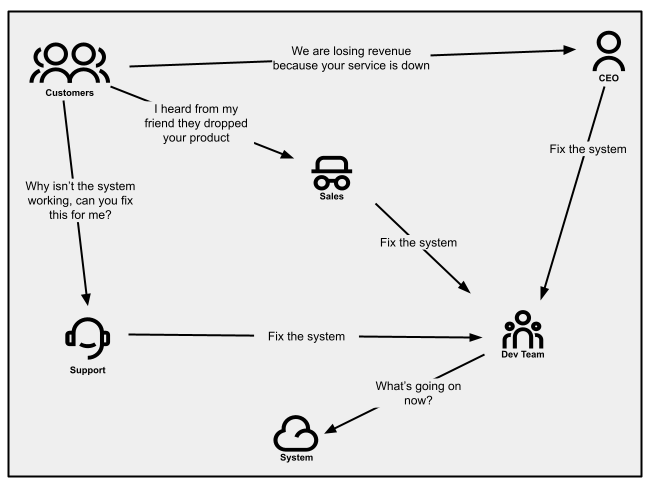
Determine 1:
Communication patterns as seen in a company the place buyer notifications
usually are not managed nicely.
How do you get out of the bottleneck?
After getting an outage, you wish to get better as rapidly as attainable and
perceive intimately why it occurred, so you’ll be able to enhance your system and
guarantee it by no means occurs once more.
Tackling the resilience of your services and products whereas within the bottleneck
may be tough. Tactical options usually imply you find yourself caught in hearth after hearth.
Nevertheless if it’s managed strategically, even whereas within the bottleneck, not
solely are you able to relieve the strain in your groups, however you’ll be able to study from previous restoration
efforts to assist handle by means of the hypergrowth stage and past.
The next 5 sections are successfully methods your group can implement.
We imagine they movement so as and must be taken as an entire. Nevertheless, relying
in your group’s maturity, you could determine to leverage a subset of
methods. Inside every, we lay out a number of options that work in the direction of it is
respective technique.
Guarantee you may have carried out fundamental resilience methods
There are some fundamental methods, starting from structure to
group, that may enhance your resiliency. They maintain your product
in the fitting place, enabling your group to scale successfully.
Use a number of zones inside a area
For extremely essential companies (and their information), configure and allow
them to run throughout a number of zones. This could give a bump to your
system availability, and enhance your resiliency within the case of
disruption (inside a zone).
Specify applicable computing occasion varieties and specs
Enterprise essential companies ought to have computing capability
appropriately assigned to them. If companies are required to run 24/7,
your infrastructure ought to mirror these necessities.
Match funding to essential service tiers
Many organizations handle funding by figuring out essential
service tiers, with the understanding that not all enterprise techniques
share the identical significance by way of delivering buyer expertise
and supporting income. Figuring out service tiers and related
resilience outcomes knowledgeable by service degree agreements (SLAs), paired with structure and
design patterns that assist the outcomes, supplies useful guardrails
and governance to your product growth groups.
Clearly outline homeowners throughout your whole system
Every service that exists inside your system ought to have
well-defined homeowners. This info can be utilized to assist direct points
to the fitting place, and to individuals who can successfully resolve them.
Implementing a developer portal which supplies a software program companies
catalog with clearly outlined staff possession helps with inner
communication patterns.
Automate guide resilience processes (inside a timebox)
Sure resilience issues which have been solved by hand may be
automated: actions like restarting a service, including new situations or
restoring database backups. Many actions are simply automated or just
require a configuration change inside your cloud service supplier.
Whereas within the bottleneck, implementing these capabilities can provide the
staff the aid it wants, offering a lot wanted respiration room and
time to resolve the foundation trigger(s).
Be certain to maintain these implementations at their easiest and
timeboxed (couple of days at max). Keep in mind these began out as
bandaids, and automating them is simply one other (albeit higher) sort of
bandaid. Combine these into your monitoring answer, permitting you
to stay conscious of how ceaselessly your system is robotically recovering and the way lengthy it
takes. On the similar time, these metrics let you prioritize
transferring away from reliance on these bandaid options and make your
complete system extra strong.
Enhance imply time to revive with observability and monitoring
To work your method out of a bottleneck, you want to perceive your
present state so you can also make efficient choices about the place to speculate.
If you wish to be 5 nines, however don’t have any sense of what number of nines are
really at the moment supplied, then it’s onerous to even know what path you
must be taking.
To know the place you might be, you want to put money into observability.
Observability lets you be extra proactive in timing funding in
resilience earlier than it turns into unmanageable.
Centralize your logs to be viewable by means of a single interface
Combination logs from core companies and techniques to be out there
by means of a central interface. This may maintain them accessible to
a number of eyes simply and cut back troubleshooting efforts (probably
enhancing imply time to restoration).
Outline a transparent structured format for log messages
Anybody who’s needed to parse by means of aggregated log messages can inform
you that when a number of companies observe differing log buildings it’s
an unimaginable mess to seek out something. Each service simply finally ends up
talking its personal language, and solely the unique authors perceive
the logs. Ideally, as soon as these logs are aggregated, anybody from
builders to assist groups ought to be capable to perceive the logs, no
matter their origin.
Construction the log messages utilizing an organization-wide standardized
format. Most logging instruments assist a JSON format as an ordinary, which
allows the log message construction to comprise metadata like timestamp,
severity, service and/or correlation-id. And with log administration
companies (by means of an observability platform), one can filter and search throughout these
properties to assist debug bottleneck points. To assist make search extra
environment friendly, choose fewer log messages with extra fields containing
pertinent info over many messages with a small variety of
fields. The precise messages themselves should be distinctive to a
particular service, however the attributes related to the log message
are useful to everybody.
Deal with your log messages as a key piece of knowledge that’s
seen to extra than simply the builders that wrote them. Your assist staff can
develop into more practical when debugging preliminary buyer queries, as a result of
they’ll perceive the construction they’re viewing. If each service
can communicate the identical language, the barrier to offer assist and
debugging help is eliminated.
Add observability that’s near your buyer expertise
What will get measured will get managed.
— Peter Drucker
Although infrastructure metrics and repair message logs are
helpful, they’re pretty low degree and don’t present any context of
the precise buyer expertise. Then again, buyer
notifications are a direct indication of a difficulty, however they’re
normally anecdotal and don’t present a lot by way of sample (except
you place within the work to seek out one).
Monitoring core enterprise metrics allows groups to watch a
buyer’s expertise. Usually outlined by means of the product’s
necessities and options, they supply excessive degree context round
many buyer experiences. These are metrics like accomplished
transactions, begin and cease charge of a video, API utilization or response
time metrics. Implicit metrics are additionally helpful in measuring a
buyer’s experiences, like frontend load time or search response
time. It is essential to match what’s being noticed immediately
to how a buyer is experiencing your product. Additionally
vital to notice, metrics aligned to the client expertise develop into
much more vital in a B2B setting, the place you won’t have
the amount of knowledge factors vital to concentrate on buyer points
when solely measuring particular person elements of a system.
At one shopper, companies began to publish area occasions that
had been associated to the product expertise: occasions like added to cart,
failed so as to add to cart, transaction accomplished, cost accepted, and many others.
These occasions may then be picked up by an observability platform (like
Splunk, ELK or Datadog) and displayed on a dashboard, categorized and
analyzed even additional. Errors may very well be captured and categorized, permitting
higher downside fixing on errors associated to sudden buyer
expertise.
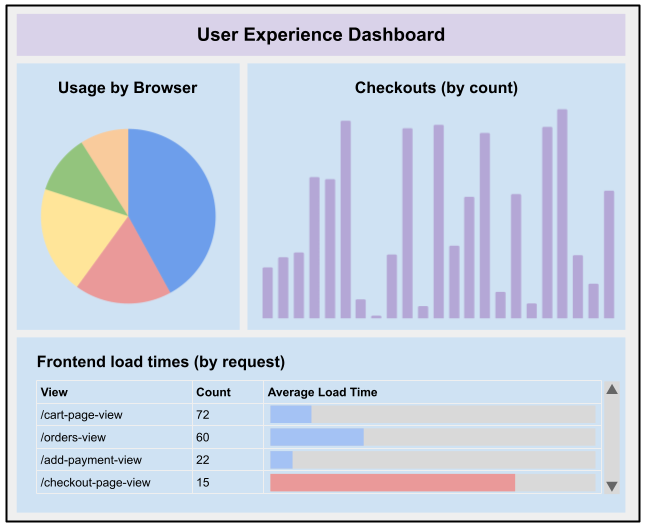
Determine 2:
Instance of what a dashboard specializing in the consumer expertise may seem like
Information gathered by means of core enterprise metrics can assist you perceive
not solely what is perhaps failing, however the place your system thresholds are and
the way it manages when it’s outdoors of that. This offers additional perception into
the way you may get by means of the bottleneck.
Present product standing perception to prospects utilizing standing indicators
It may be tough to handle incoming buyer inquiries of
totally different points they’re going through, with assist companies rapidly discovering
they’re combating hearth after hearth. Managing problem quantity may be essential
to a startup’s success, however throughout the bottleneck, you want to search for
systemic methods of lowering that site visitors. The flexibility to divert name
site visitors away from assist will give some respiration room and a greater probability to
resolve the fitting downside.
Service standing indicators can present prospects the data they’re
searching for with out having to achieve out to assist. This might are available
the type of public dashboards, electronic mail messages, and even tweets. These can
leverage backend service well being and readiness checks, or a mix
of metrics to find out service availability, degradation, and outages.
Throughout occasions of incidents, standing indicators can present a method of updating
many purchasers without delay about your product’s standing.
Constructing belief together with your prospects is simply as vital as making a
dependable and resilient service. Offering strategies for purchasers to grasp
the companies’ standing and anticipated decision timeframe helps construct
confidence by means of transparency, whereas additionally giving the assist employees
the house to problem-solve.
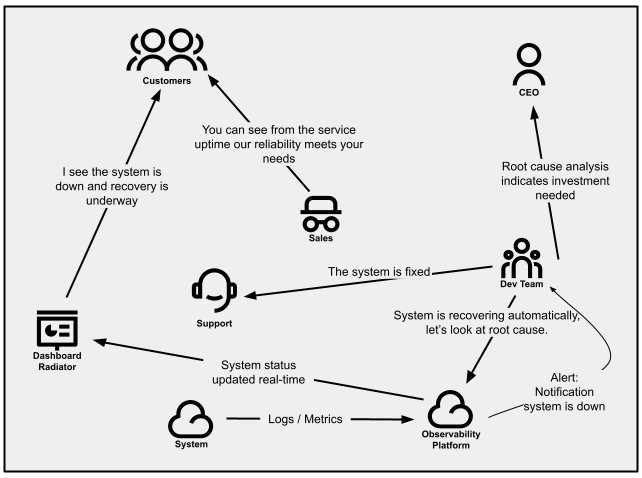
Determine 3:
Communication patterns inside a company that proactively manages how prospects are notified.
Shift to express resilience enterprise necessities
As a startup, new options are sometimes thought-about extra invaluable
than technical debt, together with any work associated to resilience. And as acknowledged
earlier than, this actually made sense initially. New options and
enhancements assist maintain prospects and herald new ones. The work to
present new capabilities ought to, in idea, result in a rise in
income.
This doesn’t essentially maintain true as your group
grows and discovers new challenges to rising income. Failures of
resilience are one supply of such challenges. To maneuver past this, there
must be a shift in the way you worth the resilience of your product.
Perceive the prices of service failure
For a startup, the results of not hitting a income goal
this ‘quarter’ is perhaps totally different than for a scaleup or a mature
product. However as usually occurs, the preliminary “new options are extra
invaluable than technical debt” choice turns into a everlasting fixture within the
organizational tradition – whether or not the precise income impression is provable
or not; and even calculated. A facet of the maturity wanted when
transferring from startup to scaleup is within the data-driven ingredient of
decision-making. Is the group monitoring the worth of each new
function shipped? And is the group analyzing the operational
investments as contributing to new income reasonably than only a
cost-center? And are the prices of an outage or recurring outages recognized
each by way of wasted inner labor hours in addition to misplaced income?
As a startup, in most of those regards, you’ve got bought nothing to lose.
However this isn’t true as you develop.
Subsequently, it’s vital to begin analyzing the prices of service
failures as a part of your total product administration and income
recognition worth stream. Understanding your income “velocity” will
present a straightforward strategy to quantify the direct cost-per-minute of
downtime. Monitoring the prices to the staff for everybody concerned in an
outage incident, from buyer assist calls to builders to administration
to public relations/advertising and even to gross sales, may be an eye-opening expertise.
Add on the chance prices of coping with an outage reasonably than
increasing buyer outreach or delivering new options and the true
scope and impression of failures in resilience develop into obvious.
Handle resilience as a function
Begin treating resilience as greater than only a technical
expectation. It’s a core function that prospects will come to anticipate.
And since they anticipate it, it ought to develop into a first-class
consideration amongst different options. A part of this evolution is about shifting the place the
accountability lies. As a substitute of it being purely a accountability for
tech, it’s one for product and the enterprise. A number of layers inside
the group might want to think about resilience a precedence. This
demonstrates that resilience will get the identical quantity of consideration that
another function would get.
Shut collaboration between
the product and expertise is significant to be sure to’re in a position to
set the proper expectations throughout story definition, implementation
and communication to different components of the group. Resilience,
although a core function, remains to be invisible to the client (in contrast to new
options like additions to a UI or API). These two teams must
collaborate to make sure resilience is prioritized appropriately and
carried out successfully.
The target right here is shifting resilience from being a reactionary
concern to a proactive one. And in case your groups are in a position to be
proactive, it’s also possible to react extra appropriately when one thing
vital is going on to your small business.
Necessities ought to mirror real looking expectations
Understanding real looking expectations for resilience relative to
necessities and buyer expectations is vital to preserving your
engineering efforts value efficient. Completely different ranges of resilience, as
measured by uptime and availability, have vastly totally different prices. The
value distinction between “three nines” and “4 nines” of availability
(99.9% vs 99.99%) could also be an element of 10x.
It’s vital to grasp your buyer necessities for every
enterprise functionality. Do you and your prospects anticipate a 24x7x365
expertise? The place are your prospects
based mostly? Are they native to a particular area or are they world?
Are they primarily consuming your service through cellular units, or are
your prospects built-in through your public API? For instance, it’s an
ineffective use of capital to offer 99.999% uptime on a service delivered through
cellular units which solely get pleasure from 99.9% uptime as a result of mobile phone
reliability limits.
These are vital inquiries to ask
when fascinated about resilience, since you don’t wish to pay for the
implementation of a degree of resiliency that has no perceived buyer
worth. In addition they assist to set and handle
expectations for the product being constructed, the staff constructing and
sustaining it, the oldsters in your group promoting it and the
prospects utilizing it.
Really feel out your issues first and keep away from overengineering
In the event you’re fixing resiliency issues by hand, your first intuition
is perhaps to simply automate it. Why not, proper? Although it will possibly assist, it is most
efficient when the implementation is time-boxed to a really brief interval
(a few days at max). Spending extra time will possible result in
overengineering in an space that was really only a symptom.
A considerable amount of time, vitality and cash shall be invested into one thing that’s
simply one other bandaid and almost certainly will not be sustainable, and even worse,
causes its personal set of second-order challenges.
As a substitute of going straight to a tactical answer, that is an
alternative to essentially really feel out your downside: The place do the fault traces
exist, what’s your observability attempting to let you know, and what design
decisions correlate to those failures. You could possibly uncover these
fault traces by means of stress, chaos or exploratory testing. Use this
alternative to your benefit to find different system stress factors
and decide the place you may get the biggest worth to your funding.
As your small business grows and scales, it’s essential to re-evaluate
previous choices. What made sense through the startup section might not get
you thru the hypergrowth phases.
Leverage a number of methods when gathering necessities
Gathering necessities for technically oriented options
may be tough. Product managers or enterprise analysts who usually are not
versed within the nomenclature of resilience can discover it onerous to
perceive. This usually interprets into imprecise necessities like “Make x service
extra resilient” or “100% uptime is our objective”. The necessities you outline are as
vital because the ensuing implementations. There are lots of methods
that may assist us collect these necessities.
Strive operating a pre-mortem earlier than writing necessities. On this
light-weight exercise, people in several roles give their
views about what they assume may fail, or what’s failing. A
pre-mortem supplies invaluable insights into how of us understand
potential causes of failure, and the associated prices. The following
dialogue helps prioritize issues that must be made resilient,
earlier than any failure happens. At a minimal, you’ll be able to create new take a look at
situations to additional validate system resilience.
Another choice is to put in writing necessities alongside tech leads and
structure SMEs. The accountability to create an efficient resilient system
is now shared amongst leaders on the staff, and every can communicate to
totally different features of the design.
These two methods present that necessities gathering for
resilience options isn’t a single accountability. It must be shared
throughout totally different roles inside a staff. All through each method you
attempt, have in mind who must be concerned and the views they bring about.
Evolve your structure and infrastructure to satisfy resiliency wants
For a startup, the design of the structure is dictated by the
velocity at which you may get to market. That always means the design that
labored at first can develop into a bottleneck in your transition to scaleup.
Your product’s resilience will finally come all the way down to the expertise
decisions you make. It might imply analyzing your total design and
structure of the system and evolving it to satisfy the product
resilience wants. A lot of what we spoke to earlier can assist provide you with
information factors and slack throughout the bottleneck. Inside that house, you’ll be able to
evolve the structure and incorporate patterns that allow a really
resilient product.
Broadly take a look at your structure and decide applicable trade-offs
Both implicitly or explicitly, when the preliminary structure was
created, trade-offs had been made. Throughout the experimentation and gaining
traction phases of a startup, there’s a excessive diploma of give attention to
getting one thing to market rapidly, preserving growth prices low,
and having the ability to simply modify or pivot product route. The
trade-off is sacrificing the advantages of resilience
that might come out of your ideally suited structure.
Take an API backed by Features as a Service (FaaS). This strategy is an effective way to
create one thing with little to no administration of the infrastructure it
runs on, probably ticking all three bins of our focus space. On the
different hand, it is restricted based mostly on the infrastructure it’s allowed to
run on, timing constraints of the service and the potential
communication complexity between many alternative features. Although not
unachievable, the constraints of the structure might make it
tough or advanced to attain the resilience your product wants.
Because the product and group grows and matures, its constraints
additionally evolve. It’s vital to acknowledge that early design choices
might now not be applicable to the present working setting, and
consequently new architectures and applied sciences must be launched.
If not addressed, the trade-offs made early on will solely amplify the
bottleneck throughout the hypergrowth section.
Improve resilience with efficient error restoration methods
Information gathered from displays can present the place excessive failure
charges are coming from, be it third-party integrations, backed-up queues,
backoffs or others. This information can drive choices on what are
applicable restoration methods to implement.
Use caching the place applicable
When retrieving info, caching methods can assist in two
methods. Primarily, they can be utilized to cut back the load on the service by
offering cached outcomes for a similar queries. Caching can be
used because the fallback response when a backend service fails to return
efficiently.
The trade-off is probably serving stale information to prospects, so
be sure that your use case will not be delicate to stale information. For instance,
you wouldn’t wish to use cached outcomes for real-time inventory value
queries.
Use default responses the place applicable
As an alternative choice to caching, which supplies the final recognized
response for a question, it’s attainable to offer a static default worth
when the backend service fails to return efficiently. For instance,
offering retail pricing because the fallback response for a pricing
low cost service will do no hurt whether it is higher to threat dropping a sale
reasonably than threat dropping cash on a transaction.
Use retry methods for mutation requests
The place a shopper is looking a service to impact a change within the information,
the use case might require a profitable request earlier than continuing. In
this case, retrying the decision could also be applicable with a view to decrease
how usually error administration processes must be employed.
There are some vital trade-offs to contemplate. Retries with out
delays threat inflicting a storm of requests which deliver the entire system
down beneath the load. Utilizing an exponential backoff delay mitigates the
threat of site visitors load, however as an alternative ties up connection sockets ready
for a long-running request, which causes a unique set of
failures.
Use idempotency to simplify error restoration
Shoppers implementing any sort of retry technique will probably
generate a number of equivalent requests. Make sure the service can deal with
a number of equivalent mutation requests, and may deal with resuming a
multi-step workflow from the purpose of failure.
Design enterprise applicable failure modes
In a system, failure is a given and your objective is to guard the tip
consumer expertise as a lot as attainable. Particularly in instances which can be
supported by downstream companies, you could possibly anticipate
failures (by means of observability) and supply another movement. Your
underlying companies that leverage these integrations may be designed
with enterprise applicable failure modes.
Contemplate an ecommerce system supported by a microservice
structure. Ought to downstream companies supporting the ordering
perform develop into overwhelmed, it will be extra applicable to
briefly disable the order button and current a restricted error
message to a buyer. Whereas this supplies clear suggestions to the consumer,
Product Managers involved with gross sales conversions may as an alternative permit
for orders to be captured and alert the client to a delay so as
affirmation.
Failure modes must be embedded into upstream techniques, in order to make sure
enterprise continuity and buyer satisfaction. Relying in your
structure, this may contain your CDN or API gateway returning
cached responses if requests are overloading your subsystems. Or as
described above, your system may present for another path to
eventual consistency for particular failure modes. This can be a much more
efficient and buyer centered strategy than the presentation of a
generic error web page that conveys ‘one thing has gone flawed’.
Resolve single factors of failure
A single service can simply go from managing a single
accountability of the product to a number of. For a startup, appending to
an current service is usually the only strategy, because the
infrastructure and deployment path is already solved. Nevertheless,
companies can simply bloat and develop into a monolith, creating some extent of
failure that may deliver down many or all components of the product. In instances
like this, you may want to grasp methods to separate up the structure,
whereas additionally preserving the product as an entire purposeful.
At a fintech shopper, throughout a hyper-growth interval, load
on their monolithic system would spike wildly. Because of the monolithic
nature, the entire features had been introduced down concurrently,
leading to misplaced income and sad prospects. The long-term
answer was to begin splitting the monolith into a number of separate
companies that may very well be scaled horizontally. As well as, they
launched occasion queues, so transactions had been by no means misplaced.
Implementing a microservice strategy will not be a easy and simple
activity, and does take effort and time. Begin by defining a site that
requires a resiliency enhance, and extract it is capabilities piece by piece.
Roll out the brand new service, regulate infrastructure configuration as wanted (enhance
provisioned capability, implement auto scaling, and many others) and monitor it.
Be sure that the consumer journey hasn’t been affected, and resilience as
an entire has improved. As soon as stability is achieved, proceed to iterate over
every functionality within the area. As famous within the shopper instance, that is
additionally a chance to introduce architectural components that assist enhance
the overall resilience of your system. Occasion queues, circuit breakers, bulkheads and
anti-corruption layers are all helpful architectural elements that
enhance the general reliability of the system.
Regularly optimize your resilience
It is one factor to get by means of the bottleneck, it is one other to remain
out of it. As you develop, your system resiliency shall be regularly
examined. New options end in new pathways for elevated system load.
Architectural adjustments introduces unknown system stability. Your
group might want to keep forward of what’s going to ultimately come. Because it
matures and grows, so ought to your funding into resilience.
Usually chaos take a look at to validate system resilience
Chaos engineering is the bedrock of actually resilient merchandise. The
core worth is the power to generate failure in ways in which you may
by no means consider. And whereas that chaos is creating failures, operating
by means of consumer situations on the similar time helps to grasp the consumer
expertise. This may present confidence that your system can stand up to
sudden chaos. On the similar time, it identifies which consumer
experiences are impacted by system failures, giving context on what to
enhance subsequent.
Although you could really feel extra comfy testing in opposition to a dev or QA
setting, the worth of chaos testing comes from manufacturing or
production-like environments. The objective is to grasp how resilient
the system is within the face of chaos. Early environments are (normally)
not provisioned with the identical configurations present in manufacturing, thus
is not going to present the boldness wanted. Operating a take a look at like
this in manufacturing may be daunting, so be sure to trust in
your means to revive service. This implies the whole system may be
spun again up and information may be restored if wanted, all by means of automation.
Begin with small comprehensible situations that can provide helpful information.
As you achieve expertise and confidence, think about using your load/efficiency
exams to simulate customers when you execute your chaos testing. Guarantee groups and
stakeholders are conscious that an experiment is about to be run, so that they
are ready to watch (in case issues go flawed). Frameworks like
Litmus or Gremlin can present construction to chaos engineering. As
confidence and maturity in your resilience grows, you can begin to run
experiments the place groups usually are not alerted beforehand.
Recruit specialists with information of resilience at scale
Hiring generalists when constructing and delivering an preliminary product
is sensible. Money and time are extremely invaluable, so having
generalists supplies the pliability to make sure you may get out to
market rapidly and never eat away on the preliminary funding. Nevertheless,
the groups have taken on greater than they’ll deal with and as your product
scales, what was as soon as adequate is now not the case. A barely
unstable system that made it to market will proceed to get extra
unstable as you scale, as a result of the abilities required to handle it have
overtaken the abilities of the present staff. In the identical vein as
technical
debt,
this generally is a slippery slope and if not addressed, the issue will
proceed to compound.
To maintain the resilience of your product, you’ll must recruit
for that experience to give attention to that functionality. Specialists herald a
recent view on the system in place, together with their means to
establish gaps and areas for enchancment. Their previous experiences can
have a two-fold impact on the staff, offering a lot wanted steerage in
areas that sorely want it, and an additional funding within the development of
your staff.
All the time preserve or enhance your reliability
In 2021, the State of Devops report expanded the fifth key metric from availability to reliability.
Below operational efficiency, it asserts a product’s means to
retain its guarantees. Resilience ties immediately into this, because it’s a
key enterprise functionality that may guarantee your reliability.
With many organizations pushing extra ceaselessly to manufacturing,
there must be assurances that reliability stays the identical or will get higher.
Along with your observability and monitoring in place, guarantee what it
tells you matches what your service degree aims (SLOs) state. With each deployment to
manufacturing, the displays shouldn’t deviate from what your SLAs
assure. Sure deployment buildings, like blue/inexperienced or canary
(to some extent), can assist to validate the adjustments earlier than being
launched to a large viewers. Operating exams successfully in manufacturing
can enhance confidence that your agreements haven’t swayed and
resilience has remained the identical or higher.
Resilience and observability as your group grows
Part 1
Experimenting
Prototype options, with hyper give attention to getting a product to market rapidly
Part 2
Getting Traction
Resilience and observability are manually carried out through developer intervention
Prioritization for fixing resilience primarily comes from technical debt
Dashboards mirror low degree companies statistics like CPU and RAM
Majority of assist points are available through calls or textual content messages from prospects
Part 3
(Hyper) Development
Resilience is a core function delivered to prospects, prioritized in the identical vein as options
Observability is ready to mirror the general buyer expertise, mirrored by means of dashboards and monitoring
Re-architect or recreate problematic companies, enhancing the resilience within the course of
Part 4
Optimizing
Platforms evolve from inner going through companies, productizing observability and compute environments
Run periodic chaos engineering workout routines, with little to no discover
Increase groups with engineers which can be versed in resilience at scale
Abstract
As a scaleup, what determines your means to successfully navigate the
hyper(development) section is partly tied to the resilience of your
product. The excessive development charge begins to place strain on a system that was
developed through the startup section, and failure to deal with the resilience of
that system usually leads to a bottleneck.
To reduce threat, resilience must be handled as a first-class citizen.
The small print might range in response to your context, however at a excessive degree the
following issues may be efficient:
- Resilience is a key function of your product. It’s now not only a
technical element, however a key part that your prospects will come to anticipate,
shifting the corporate in the direction of a proactive strategy. - Construct buyer standing indicators to assist divert some assist requests,
permitting respiration room to your staff to resolve the vital issues. - The shopper expertise must be mirrored inside your observability stack.
Monitor core enterprise metrics that mirror experiences your prospects have. - Perceive what your dashboards and displays are telling you, to get a way
of what are essentially the most essential areas to resolve. - Evolve your structure to satisfy your resiliency targets as you establish
particular challenges. Preliminary designs may fit at small scale however develop into
more and more limiting as you transition to a scaleup. - When architecting failure modes, discover methods to fail which can be pleasant to the
shopper, serving to to make sure continuity and buyer satisfaction. - Outline real looking resilience expectations to your product, and perceive the
limitations with which it’s being served. Use this data to offer your
prospects with efficient SLAs and cheap SLOs. - Optimize your resilience whenever you’re by means of the bottleneck. Make chaos
engineering a part of a daily apply or recruiting specialists.
Efficiently incorporating these practices leads to a future group
the place resilience is constructed into enterprise aims, throughout all dimensions of
folks, course of, and expertise.