

{kind=link}
The Databricks Container Infra workforce builds cloud-agnostic infrastructure and tooling for constructing, storing and distributing container photos. Lately, the workforce labored on scaling Harbor, an open-source container registry. Request masses on Harbor are read-heavy and bursty and it’s a crucial part of Databricks’ serverless product – anytime new serverless VMs are provisioned, Harbor will get a big spike in learn requests. With the fast progress of the product, our utilization of Harbor would want to scale to deal with 20x extra load than it might at peak.
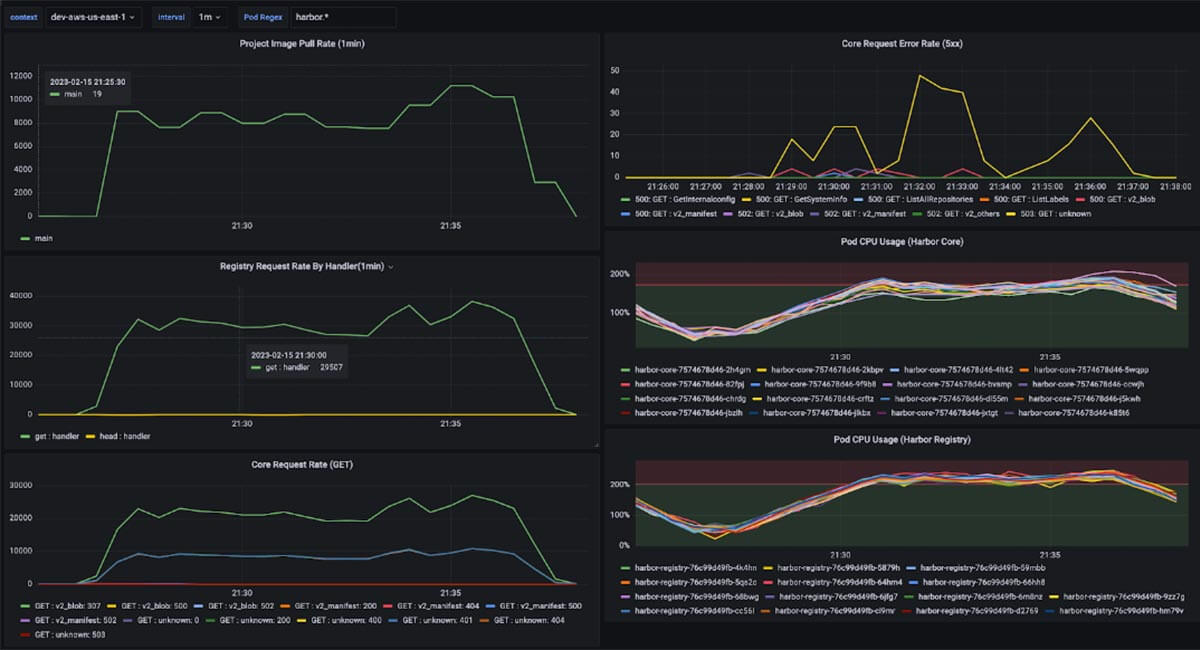
Over the course of Q1 2023, we tuned Harbor’s efficiency to make sure it was in a position to horizontally scale out. Later we prolonged it with a brand new service referred to as harbor-frontend to drastically enhance scaling effectivity for Databricks workloads (learn heavy, low cardinality of photos).
Why Scale the Container Registry?
Databricks shops container photos in Harbor. Each time a buyer begins up a Serverless DBSQL cluster, they reserve some quantity of compute sources from a heat pool. If that heat pool turns into exhausted, our infrastructure will request further compute sources from the upstream cloud supplier (AWS, for instance), which can subsequently be configured, began up, and added to the nice and cozy pool. That startup course of contains pulling numerous container photos from Harbor.
As our serverless product grows in scope and recognition, the nice and cozy pool will 1.) be exhausted extra incessantly and a couple of.) must be refilled extra shortly. The duty was to organize Harbor to have the ability to serve these scalability necessities.
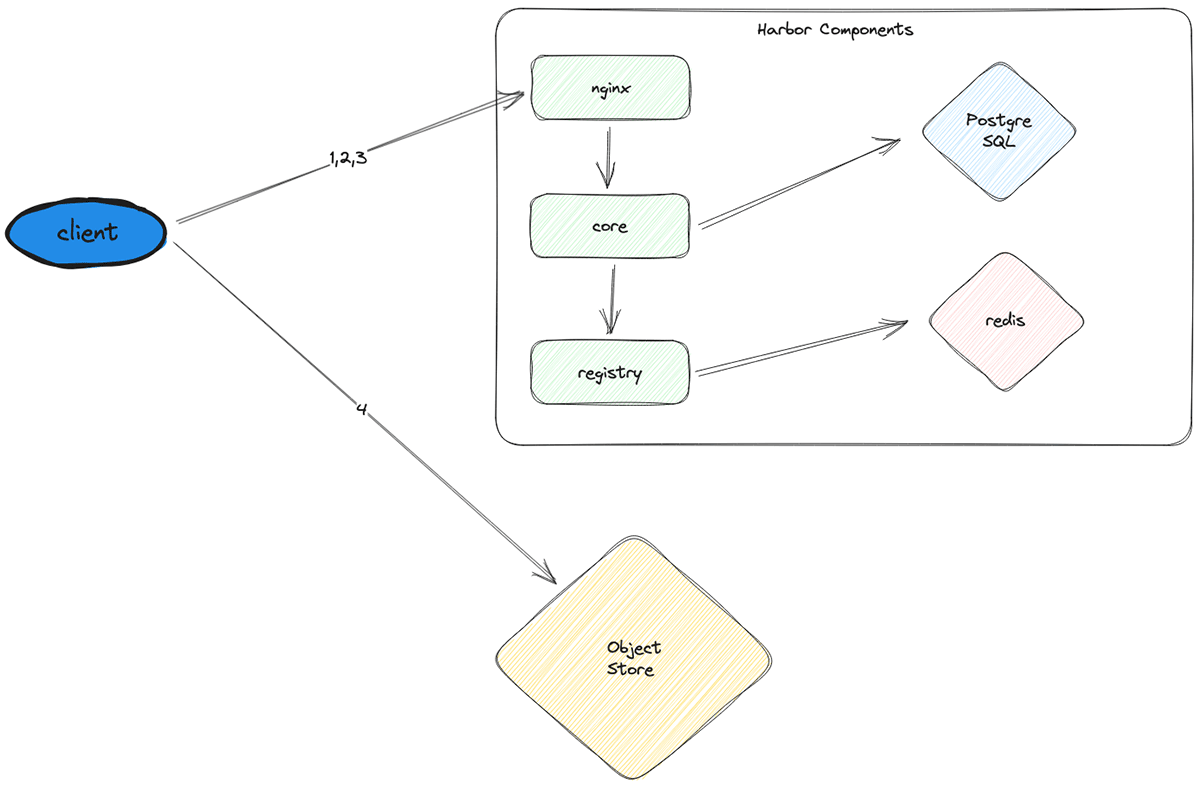
At a excessive degree, picture pulls for a node startup undergo the next course of:
- Authenticate the shopper node to Harbor
- Fetch the required picture manifests from Harbor
- Based mostly on the manifests, fetch signed URLs pointing to the corresponding picture layers in object storage
- Use the signed URLs to tug all of the picture layers from exterior object storage (e.g., S3) and mix them to get the ultimate photos
Iterating Rapidly
Earlier than we began to enhance Harbor’s efficiency, there have been two issues to grasp first:
- What is supposed by “efficiency”?
- How can we measure efficiency?
Within the context of scaling Harbor for serverless workloads, efficiency is the variety of node startups that may be served efficiently per time unit. Every node startup should pull some variety of photos (roughly 30) from Harbor, and every picture has some variety of layers (roughly 10). So transitively, we will measure Harbor efficiency with the metric “layers requested per minute (LPM).” If Harbor can serve requests at 300 LPM, we will permit one node startup per minute.
Given our load forecast, the goal was to allow Harbor to serve 1000 node startups per minute or 300,000 LPM. Once I began, Harbor noticed extreme failure charge and latency degradation at 15-30,000 LPM. That meant we wanted a 20x enchancment in efficiency!
We spent the primary month increase the tooling we would use for the next three months: load-generation/load-testing. To measure Harbor’s efficiency, we would want dependable testing to push Harbor to its limits. We discovered an present load tester within the code base that would generate load on Harbor. We added docker packaging assist to permit us to deploy it on Kubernetes and to ratchet up the load despatched to Harbor by scaling it horizontally.
As we dove deep to grasp the underlying strategy of Docker picture pulls, the workforce crafted a brand new load tester which, as a substitute of being bottlenecked by downloading from exterior object storage (Step 4 above), would solely carry out the steps that put the load on Harbor (Steps 1-3 above).
As soon as the most recent load tester was constructed out, it was lastly time to start out bettering our Harbor infrastructure. For distributed programs equivalent to Harbor, that is what that course of seems like:
- Apply load till the error charge and/or latency spikes
- Examine to uncover the bottleneck:
- Error logs
- CPU utilization
- Community connections
- CPU throttling
- 4xx/5xx errors, the latency on totally different parts, and so on.
- Resolve the bottleneck
- Return to Step 1
By way of this course of, we have been in a position to establish and resolve the next bottlenecks shortly.
Exterior Redis Cache Limits Picture Pull Price
The registry part had many situations, all calling into the identical exterior Redis occasion – to resolve this bottleneck we eliminated the exterior occasion and made it an in-memory cache inside the registry part. It seems we did not want the exterior cache in any respect.
Database CPU spikes to 100%
To resolve this, we vertically scaled the DB occasion sort and restricted the variety of open connections every harbor-core occasion made to the DB to maintain connection creation overhead low.
CPU throttling
Now that the DB was operating easily, the following bottleneck was the CPU throttling occurring on the stateless parts (nginx, core, and registry). To resolve this difficulty, we horizontally scaled every of them by including replicas.
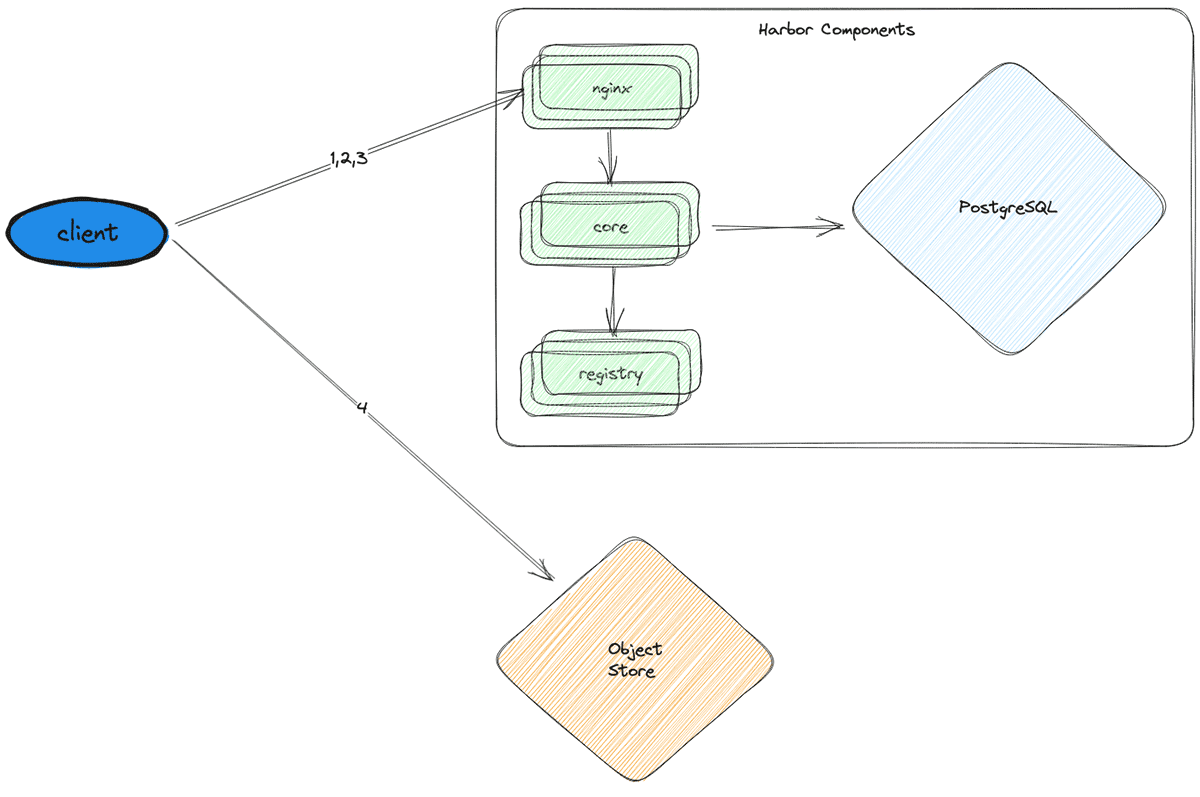
Lastly, we hit the goal of 300,000 LPM. Nonetheless, at this level, we have been utilizing 30x extra CPUs and a DB occasion that was 16x extra highly effective and 32x extra pricey.
Whereas these modifications allowed us to hit our scalability goal, they price us thousands and thousands of {dollars} extra per 12 months in cloud providers. So we regarded for a method to scale back prices.
Can We Sidestep the Drawback?
To optimize, I wanted to concentrate on the precise necessities of this use case. Node startups on the serverless product require solely a small set of photos to be pulled by a big set of nodes – this implies we’re fetching the identical set of keys again and again. A use case good for optimization by way of cache!
There have been two choices for caching: use one thing off-the-shelf (nginx on this case) or construct one thing completely new.
Nginx caching is proscribed as a result of it would not assist authentication. Nginx doesn’t have a built-in authentication course of that matches our use case. We experimented with totally different nginx configurations to work across the difficulty, however the cache hit charge merely was not excessive sufficient.
So the following choice was to construct one thing completely new – Harbor Frontend (Harbor FE).
Harbor FE acts as a write-through cache layer sitting between nginx and the opposite harbor parts. Harbor FE is solely an HTTP server carried out in golang that authenticates shoppers, forwards requests to harbor-core, and caches the responses. Since all nodes request the identical set of photos, as soon as the cache is heat, the hit charge stays close to 100%.
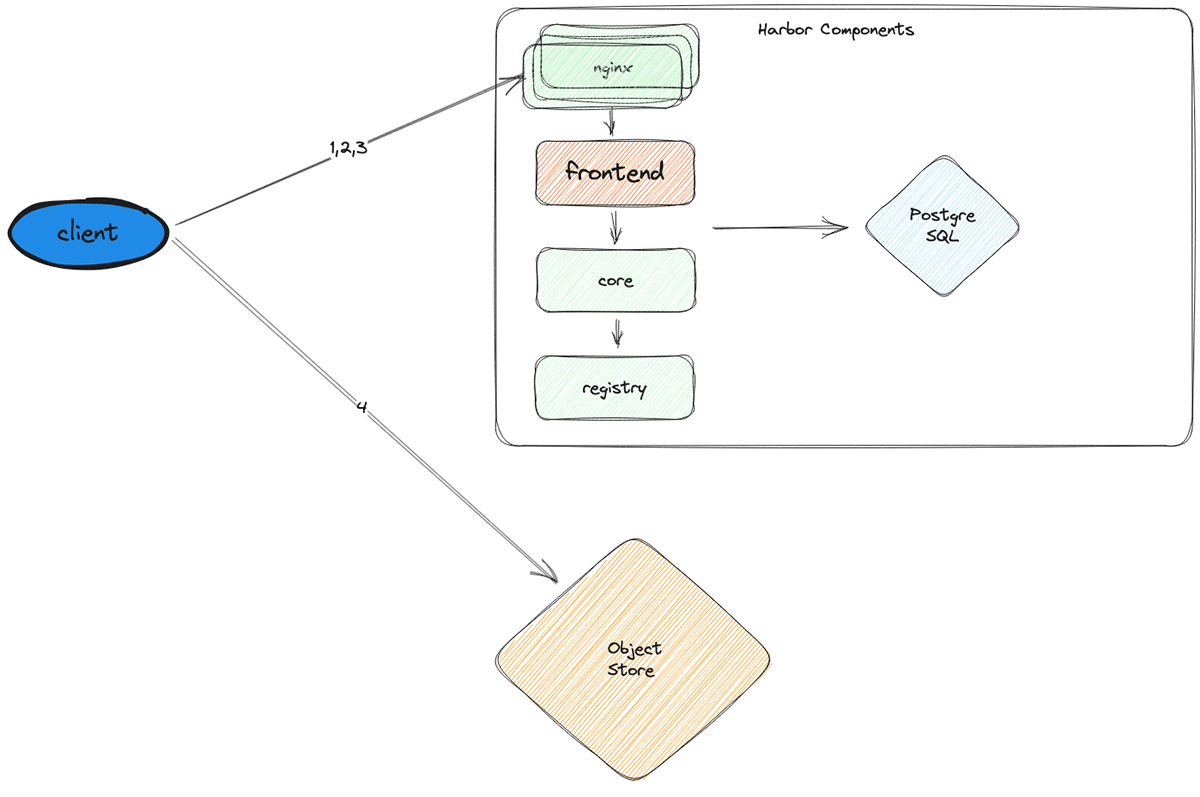
Utilizing the brand new structure, we’re in a position to considerably scale back load to different harbor providers and the database (which is very vital since vertically scaling it’s the most possible choice and is prohibitively costly). Most requests terminate at Harbor FE and by no means hit harbor-core, harbor-registry, or the DB. Additional, Harbor FE can serve virtually all requests from its in-memory cache, making it a extremely environment friendly use of cluster sources.
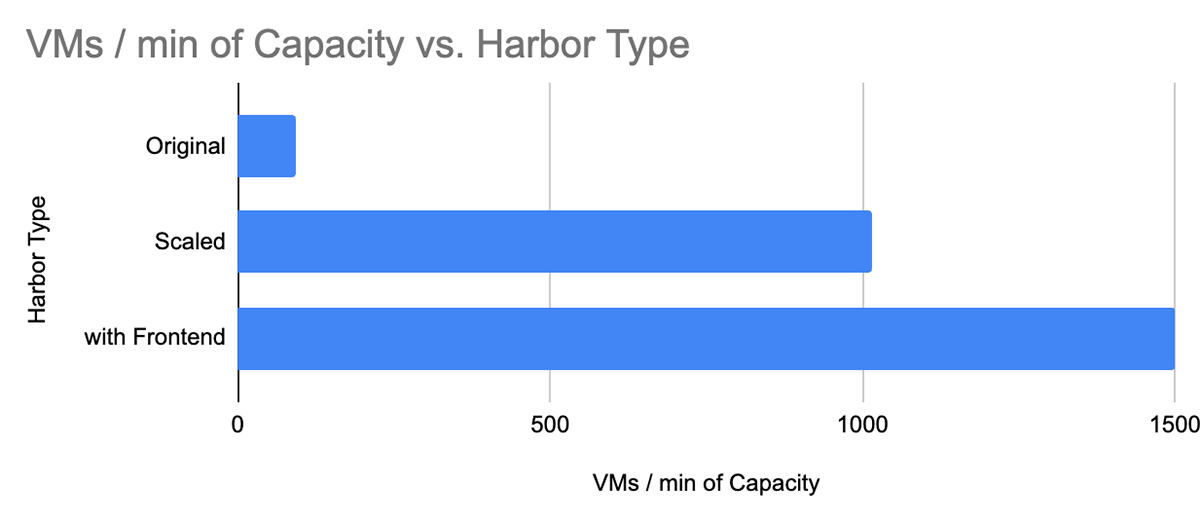
With Harbor FE, we have been in a position to serve a capability of 450,000 LPM (or 1500 node startups per minute), all whereas utilizing 30x fewer CPUs at peak load than the historically scaled model.
Conclusion
In conclusion, the journey to enhance Harbor’s efficiency at Databricks has been each difficult and rewarding. By utilizing our present data of Docker, Kubernetes, Harbor, and golang, we have been in a position to be taught shortly and make vital contributions to the Serverless product. By iterating swiftly and specializing in the appropriate metrics, we developed the `harbor-frontend` service, which allowed an efficient caching technique to attain 450,000 LPM, surpassing our preliminary goal of 300,000 LPM. The harbor-frontend service not solely diminished the load on different Harbor parts and the database but additionally offered further advantages equivalent to higher visibility into Harbor operations, a platform so as to add options to container infrastructure, and future extensibility. Potential future enhancements embody safety enhancements, altering the picture pull protocol, and implementing customized throttling logic.
On a private observe, earlier than becoming a member of Databricks, I used to be instructed that the corporate takes delight in fostering a tradition of high-quality engineering and selling a supportive work surroundings crammed with humble, curious, and open-minded colleagues. I did not know the way true it will be till I joined the workforce in January, missing data of the instruments essential to work together with Harbor, not to mention Harbor itself. From day one, I discovered myself surrounded by folks genuinely invested in my success, empowering my workforce and me to sort out challenges with a smile on our faces.
I wish to lengthen my gratitude to my mentor, Shuai Chang, my supervisor, Anders Liu, and mission collaborators, Masud Khan and Simha Venkataramaiah. Moreover, I wish to thank the complete OS and container platform workforce for offering me with a very fantastic internship expertise.
Try Careers at Databricks should you’re desirous about becoming a member of our mission to assist information groups remedy the world’s hardest issues.