

{kind=link}
At present, MSK Serverless solely instantly helps IAM for authentication utilizing Java. This instance exhibits how you can use this mechanism. Moreover, it offers a sample making a proxy that may simply be built-in into options in-built languages aside from Java.
The rising development in right now’s tech panorama is using streaming knowledge and event-oriented buildings. They’re being utilized in quite a few methods, together with monitoring web site site visitors, monitoring industrial Web of Issues (IoT) units, analyzing online game participant habits, and managing knowledge for cutting-edge analytics methods.
Apache Kafka, a top-tier open-source instrument, is making waves on this area. It’s extensively adopted by quite a few customers for constructing quick and environment friendly knowledge pipelines, analyzing streaming knowledge, merging knowledge from totally different sources, and supporting important functions.
Amazon’s serverless Apache Kafka providing, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless, is attracting quite a lot of curiosity. It’s appreciated for its user-friendly method, capacity to scale robotically, and cost-saving advantages over different Kafka options. Nevertheless, a hurdle encountered by many customers is the requirement of MSK Serverless to make use of AWS Id and Entry Administration (IAM) entry management. On the time of writing, the Amazon MSK library for IAM is unique to Kafka libraries in Java, making a problem for customers of different programming languages. On this put up, we intention to deal with this problem and current how you should use Amazon API Gateway and AWS Lambda to navigate round this impediment.
SASL/SCRAM authentication vs. IAM authentication
In comparison with the normal authentication strategies like Salted Problem Response Authentication Mechanism (SCRAM), the IAM extension into Apache Kafka via MSK Serverless offers quite a lot of advantages. Earlier than we delve into these, it’s essential to know what SASL/SCRAM authentication is. Basically, it’s a standard methodology used to verify a consumer’s identification earlier than giving them entry to a system. This course of requires customers or shoppers to offer a consumer title and password, which the system then cross-checks towards saved credentials (for instance, by way of AWS Secrets and techniques Supervisor) to resolve whether or not or not entry ought to be granted.
In comparison with this method, IAM simplifies permission administration throughout AWS environments, permits the creation and strict enforcement of detailed permissions and insurance policies, and makes use of momentary credentials relatively than the standard consumer title and password authentication. One other advantage of utilizing IAM is that you should use IAM for each authentication and authorization. In the event you use SASL/SCRAM, you need to moreover handle ACLs by way of a separate mechanism. In IAM, you should use the IAM coverage hooked up to the IAM principal to outline the fine-grained entry management for that IAM principal. All of those enhancements make the IAM integration a extra environment friendly and safe answer for many use instances.
Nevertheless, for functions not in-built Java, using MSK Serverless turns into difficult. The usual SASL/SCRAM authentication isn’t obtainable, and non-Java Kafka libraries don’t have a approach to make use of IAM entry management. This requires an alternate method to connect with MSK Serverless clusters.
However there’s an alternate sample. With out having to rewrite your present utility in Java, you possibly can make use of API Gateway and Lambda as a proxy in entrance of a cluster. They will deal with API requests and relay them to Kafka matters immediately. API Gateway takes in producer requests and channels them to a Lambda perform, written in Java utilizing the Amazon MSK IAM library. It then communicates with the MSK Serverless Kafka subject utilizing IAM entry management. After the cluster receives the message, it may be additional processed throughout the MSK Serverless setup.
You can even make the most of Lambda on the buyer facet of MSK Serverless matters, bypassing the Java requirement on the buyer facet. You are able to do this by setting Amazon MSK as an occasion supply for a Lambda perform. When the Lambda perform is triggered, the info despatched to the perform consists of an array of information from the Kafka subject—no want for direct contact with Amazon MSK.
Answer overview
This instance walks you thru how you can construct a serverless real-time stream producer utility utilizing API Gateway and Lambda.
For testing, this put up features a pattern AWS Cloud Improvement Equipment (AWS CDK) utility. This creates a demo surroundings, together with an MSK Serverless cluster, three Lambda capabilities, and an API Gateway that consumes the messages from the Kafka subject.
The next diagram exhibits the structure of the ensuing utility together with its knowledge flows.
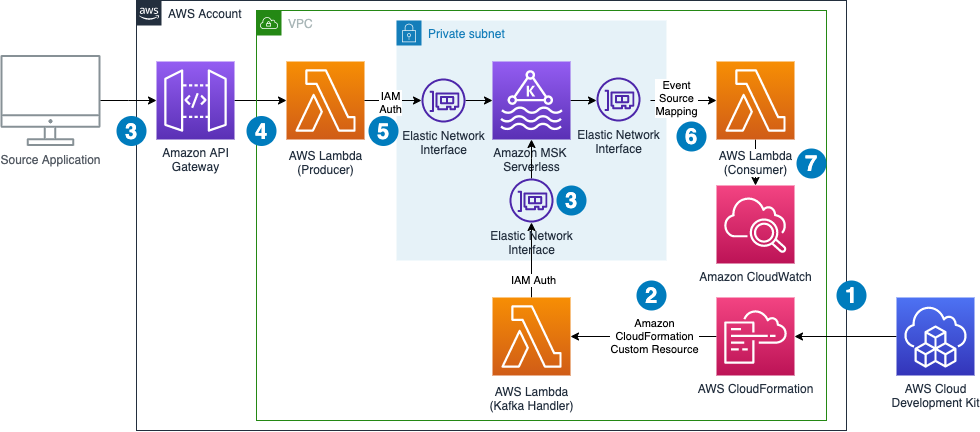
The info circulate incorporates the next steps:
- The infrastructure is outlined in an AWS CDK utility. By operating this utility, a set of AWS CloudFormation templates is created.
- AWS CloudFormation creates all infrastructure elements, together with a Lambda perform that runs through the deployment course of to create a subject within the MSK Serverless cluster and to retrieve the authentication endpoint wanted for the producer Lambda perform. On destruction of the CloudFormation stack, the identical Lambda perform will get triggered once more to delete the subject from the cluster.
- An exterior utility calls an API Gateway endpoint.
- API Gateway forwards the request to a Lambda perform.
- The Lambda perform acts as a Kafka producer and pushes the message to a Kafka subject utilizing IAM authentication.
- The Lambda occasion supply mapping mechanism triggers the Lambda shopper perform and forwards the message to it.
- The Lambda shopper perform logs the info to Amazon CloudWatch.
Observe that we don’t want to fret about Availability Zones. MSK Serverless robotically replicates the info throughout a number of Availability Zones to make sure excessive availability of the info.
The demo moreover exhibits how you can use Lambda Powertools for Java to streamline logging and tracing and the IAM authenticator for the easy authentication course of outlined within the introduction.
The next sections take you thru the steps to deploy, check, and observe the instance utility.
Stipulations
The instance has the next stipulations:
- An AWS account. In the event you haven’t signed up, full the next steps:
- The next software program put in in your improvement machine, or use an AWS Cloud9 surroundings, which comes with all necessities preinstalled:
- Acceptable AWS credentials for interacting with assets in your AWS account.
Deploy the answer
Full the next steps to deploy the answer:
- Clone the challenge GitHub repository and alter the listing to subfolder
serverless-kafka-iac:
- Configure surroundings variables:
- Put together the digital Python surroundings:
- Bootstrap your account for AWS CDK utilization:
- Run cdk synth to construct the code and check the necessities (guarantee docker daemon is operating in your machine):
- Run cdk deploy to deploy the code to your AWS account:
Take a look at the answer
To check the answer, we generate messages for the Kafka matters by sending calls via the API Gateway from our improvement machine or AWS Cloud9 surroundings. We then go to the CloudWatch console to watch incoming messages within the log recordsdata of the Lambda shopper perform.
- Open a terminal in your improvement machine to check the API with the Python script offered beneath
/serverless_kafka_iac/test_api.py:
- On the Lambda console, open the Lambda perform named
ServerlessKafkaConsumer.
- On the Monitor tab, select View CloudWatch logs to entry the logs of the Lambda perform.
- Select the newest log stream to entry the log recordsdata of the final run.
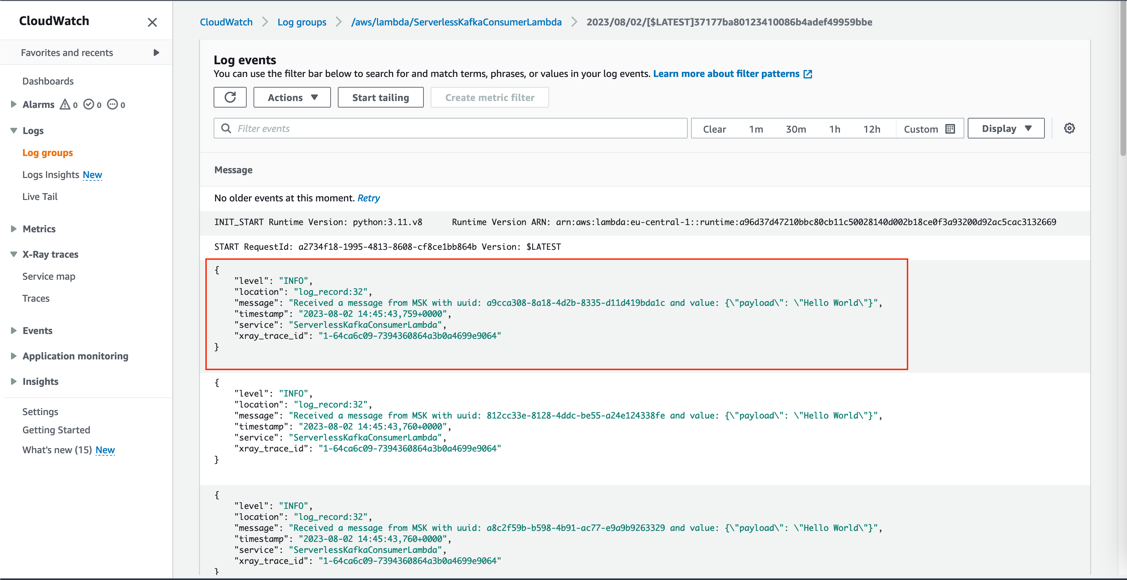
You’ll be able to evaluation the log entry of the obtained Kafka messages within the log of the Lambda perform.
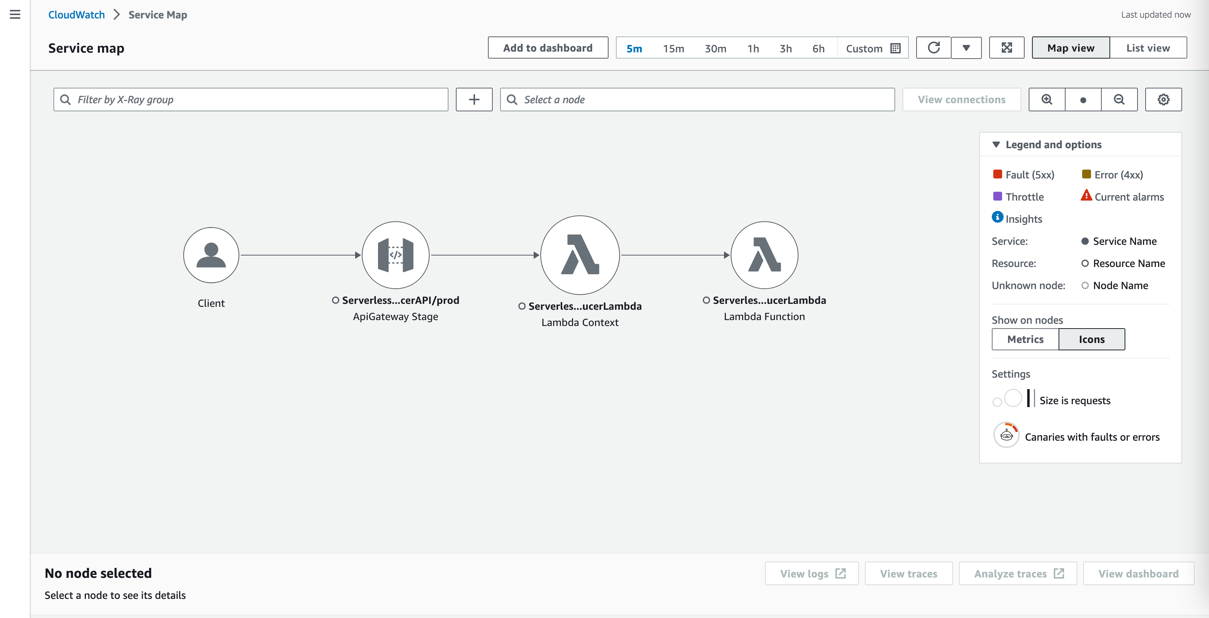
Hint a request
All elements combine with AWS X-Ray. With AWS X-Ray, you possibly can hint the whole utility, which is helpful to determine bottlenecks when load testing. You can even hint methodology runs on the Java methodology stage.
Lambda Powertools for Java permits you to shortcut this course of by including the @Hint annotation to a way to see traces on the strategy stage in X-Ray.
To hint a request finish to finish, full the next steps:
- On the CloudWatch console, select Service map within the navigation pane.
- Choose a part to analyze (for instance, the Lambda perform the place you deployed the Kafka producer).
- Select View traces.
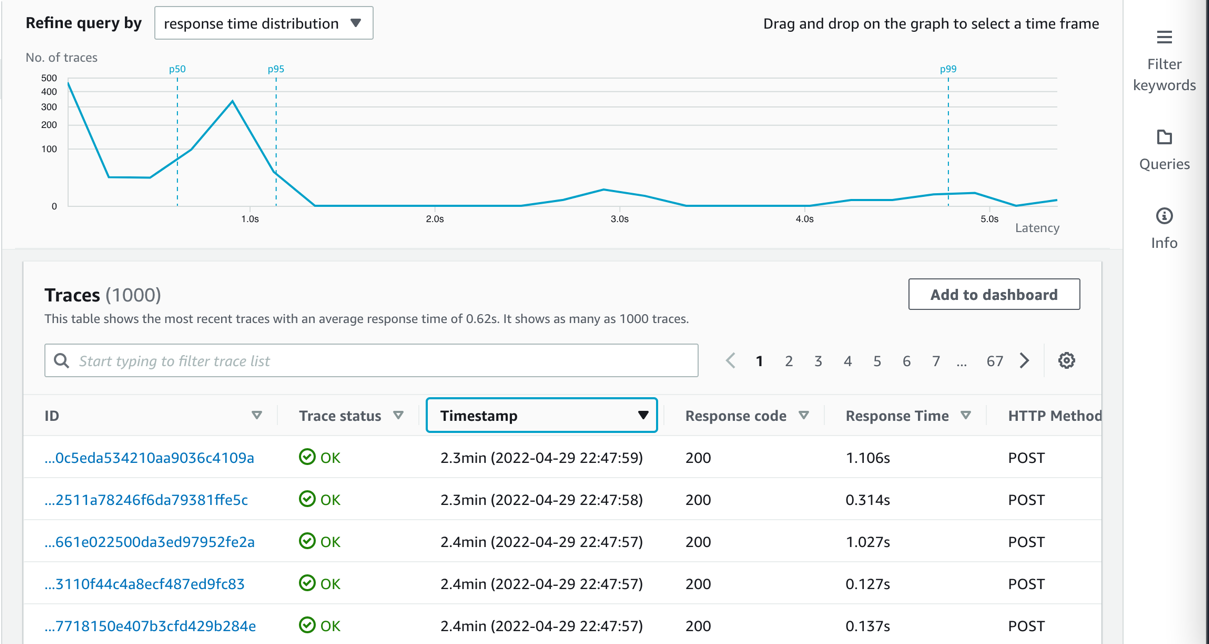
- Select a single Lambda methodology invocation and examine additional on the Java methodology stage.
Implement a Kafka producer in Lambda
Kafka natively helps Java. To remain open, cloud native, and with out third-party dependencies, the producer is written in that language. At present, the IAM authenticator is simply obtainable to Java. On this instance, the Lambda handler receives a message from an API Gateway supply and pushes this message to an MSK subject known as messages.
Usually, Kafka producers are long-living and pushing a message to a Kafka subject is an asynchronous course of. As a result of Lambda is ephemeral, it’s essential to implement a full flush of a submitted message till the Lambda perform ends by calling producer.flush():
Hook up with Amazon MSK utilizing IAM authentication
This put up makes use of IAM authentication to connect with the respective Kafka cluster. For details about how you can configure the producer for connectivity, check with IAM entry management.
Since you configure the cluster by way of IAM, grant Join and WriteData permissions to the producer in order that it could push messages to Kafka:
This exhibits the Kafka excerpt of the IAM coverage, which should be utilized to the Kafka producer. When utilizing IAM authentication, bear in mind of the present limits of IAM Kafka authentication, which have an effect on the variety of concurrent connections and IAM requests for a producer. Check with Amazon MSK quota and comply with the advice for authentication backoff within the producer consumer:
Further issues
Every MSK Serverless cluster can deal with 100 requests per second. To cut back IAM authentication requests from the Kafka producer, place it outdoors of the handler. For frequent calls, there’s a likelihood that Lambda reuses the beforehand created class occasion and solely reruns the handler.
For bursting workloads with a excessive variety of concurrent API Gateway requests, this will result in dropped messages. Though this is likely to be tolerable for some workloads, for others this won’t be the case.
In these instances, you possibly can lengthen the structure with a buffering expertise like Amazon Easy Queue Service (Amazon SQS) or Amazon Kinesis Information Streams between API Gateway and Lambda.
To cut back latency, cut back chilly begin occasions for Java by altering the tiered compilation stage to 1, as described in Optimizing AWS Lambda perform efficiency for Java. Provisioned concurrency ensures that polling Lambda capabilities don’t must heat up earlier than requests arrive.
Conclusion
On this put up, we confirmed how you can create a serverless integration Lambda perform between API Gateway and MSK Serverless as a approach to do IAM authentication when your producer shouldn’t be written in Java. You additionally discovered concerning the native integration of Lambda and Amazon MSK on the buyer facet. Moreover, we confirmed how you can deploy such an integration with the AWS CDK.
The final sample is appropriate for a lot of use instances the place you wish to use IAM authentication however your producers or customers will not be written in Java, however you continue to wish to reap the benefits of the advantages of MSK Serverless, like its capacity to scale up and down with unpredictable or spikey workloads or its little to no operational overhead of operating Apache Kafka.
You can even use MSK Serverless to cut back operational complexity by automating provisioning and the administration of capability wants, together with the necessity to consistently monitor brokers and storage.
For extra serverless studying assets, go to Serverless Land.
For extra data on MSK Serverless, take a look at the next:
In regards to the Authors
 Philipp Klose is a International Options Architect at AWS based mostly in Munich. He works with enterprise FSI prospects and helps them clear up enterprise issues by architecting serverless platforms. On this free time, Philipp spends time together with his household and enjoys each geek interest attainable.
Philipp Klose is a International Options Architect at AWS based mostly in Munich. He works with enterprise FSI prospects and helps them clear up enterprise issues by architecting serverless platforms. On this free time, Philipp spends time together with his household and enjoys each geek interest attainable.
 Daniel Wessendorf is a International Options Architect at AWS based mostly in Munich. He works with enterprise FSI prospects and is primarily specialised in machine studying and knowledge architectures. In his free time, he enjoys swimming, climbing, snowboarding, and spending high quality time together with his household.
Daniel Wessendorf is a International Options Architect at AWS based mostly in Munich. He works with enterprise FSI prospects and is primarily specialised in machine studying and knowledge architectures. In his free time, he enjoys swimming, climbing, snowboarding, and spending high quality time together with his household.
 Marvin Gersho is a Senior Options Architect at AWS based mostly in New York Metropolis. He works with a variety of startup prospects. He beforehand labored for a few years in engineering management and hands-on utility improvement, and now focuses on serving to prospects architect safe and scalable workloads on AWS with a minimal of operational overhead. In his free time, Marvin enjoys biking and technique board video games.
Marvin Gersho is a Senior Options Architect at AWS based mostly in New York Metropolis. He works with a variety of startup prospects. He beforehand labored for a few years in engineering management and hands-on utility improvement, and now focuses on serving to prospects architect safe and scalable workloads on AWS with a minimal of operational overhead. In his free time, Marvin enjoys biking and technique board video games.
 Nathan Lichtenstein is a Senior Options Architect at AWS based mostly in New York Metropolis. Primarily working with startups, he ensures his prospects construct good on AWS, delivering artistic options to their advanced technical challenges. Nathan has labored in cloud and community structure within the media, monetary providers, and retail areas. Outdoors of labor, he can usually be discovered at a Broadway theater.
Nathan Lichtenstein is a Senior Options Architect at AWS based mostly in New York Metropolis. Primarily working with startups, he ensures his prospects construct good on AWS, delivering artistic options to their advanced technical challenges. Nathan has labored in cloud and community structure within the media, monetary providers, and retail areas. Outdoors of labor, he can usually be discovered at a Broadway theater.