
{kind=link}
Database efficiency is a vital side of guaranteeing an internet software or service stays quick and steady. Because the service scales up, there are sometimes challenges with scaling the first database together with it. Whereas MongoDB is usually used as a major on-line database and may meet the calls for of very massive scale net functions, it does usually change into the bottleneck as effectively.
I had the chance to function MongoDB at scale as a major database at Foursquare, and encountered many of those bottlenecks. It will possibly usually be the case when utilizing MongoDB as a major on-line database for a closely trafficked net software that entry patterns akin to joins, aggregations, and analytical queries that scan massive or total parts of a set can’t be run as a result of adversarial impacts they’ve on efficiency. Nevertheless, these entry patterns are nonetheless required to construct many software options.
We devised many methods to take care of these conditions at Foursquare. The principle technique to alleviate a few of the strain on the first database is to dump a few of the work to a secondary knowledge retailer, and I’ll share a few of the widespread patterns of this technique on this weblog sequence. On this weblog we are going to simply proceed to solely use MongoDB, however break up up the work from a single cluster to a number of clusters. In future articles I’ll talk about offloading to different varieties of methods.
Use A number of MongoDB Clusters
One strategy to get extra predictable efficiency and isolate the impacts of querying one assortment from one other is to separate them into separate MongoDB clusters. If you’re already utilizing service oriented structure, it might make sense to additionally create separate MongoDB clusters for every main service or group of companies. This manner you’ll be able to decrease the impression of an incident to a MongoDB cluster to only the companies that have to entry it. If your whole microservices share the identical MongoDB backend, then they aren’t actually unbiased of one another.
Clearly if there’s new growth you’ll be able to select to start out any new collections on a model new cluster. Nevertheless you can even determine to maneuver work presently completed by current clusters to new clusters by both simply migrating a set wholesale to a different cluster, or creating new denormalized collections in a brand new cluster.
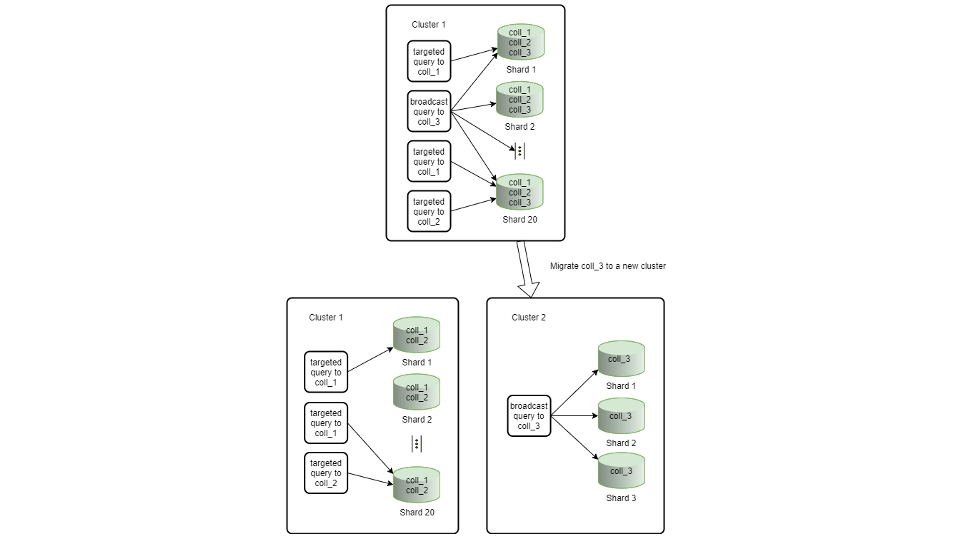
Migrating a Assortment
The extra comparable the question patterns are for a selected cluster, the simpler it’s to optimize and predict its efficiency. In case you have collections with very totally different workload traits, it might make sense to separate them into totally different clusters as a way to higher optimize cluster efficiency for every sort of workload.
For instance, you’ve a extensively sharded cluster the place many of the queries specify the shard key so they’re focused to a single shard. Nevertheless, there’s one assortment the place many of the queries don’t specify the shard key, and thus lead to being broadcast to all shards. Since this cluster is extensively sharded, the work amplification of those broadcast queries turns into bigger with each extra shard. It could make sense to maneuver this assortment to its personal cluster with many fewer shards as a way to isolate the load of the printed queries from the opposite collections on the unique cluster. It is usually very possible that the efficiency of the printed question may also enhance by doing this as effectively. Lastly, by separating the disparate question patterns, it’s simpler to motive concerning the efficiency of the cluster since it’s usually not clear when taking a look at a number of gradual question patterns which one causes the efficiency degradation on the cluster and which of them are gradual as a result of they’re affected by efficiency degradations on the cluster.

Denormalization
Denormalization can be utilized inside a single cluster to cut back the variety of reads your software must make to the database by embedding further data right into a doc that’s often requested with it, thus avoiding the necessity for joins. It will also be used to separate work into a very separate cluster by making a model new assortment with aggregated knowledge that often must be computed.
For instance, if we now have an software the place customers could make posts about sure subjects, we’d have three collections:
customers:
{
_id: ObjectId('AAAA'),
identify: 'Alice'
},
{
_id: ObjectId('BBBB'),
identify: 'Bob'
}
subjects:
{
_id: ObjectId('CCCC'),
identify: 'cats'
},
{
_id: ObjectId('DDDD'),
identify: 'canines'
}
posts:
{
_id: ObjectId('PPPP'),
identify: 'My first submit - cats',
consumer: ObjectId('AAAA'),
matter: ObjectId('CCCC')
},
{
_id: ObjectId('QQQQ'),
identify: 'My second submit - canines',
consumer: ObjectId('AAAA'),
matter: ObjectId('DDDD')
},
{
_id: ObjectId('RRRR'),
identify: 'My first submit about canines',
consumer: ObjectId('BBBB'),
matter: ObjectId('DDDD')
},
{
_id: ObjectId('SSSS'),
identify: 'My second submit about canines',
consumer: ObjectId('BBBB'),
matter: ObjectId('DDDD')
}
Your software could need to know what number of posts a consumer has ever made a couple of sure matter. If these are the one collections accessible, you would need to run a rely on the posts assortment filtering by consumer and matter. This might require you to have an index like {'matter': 1, 'consumer': 1} as a way to carry out effectively. Even with the existence of this index, MongoDB would nonetheless have to do an index scan of all of the posts made by a consumer for a subject. To be able to mitigate this, we are able to create a brand new assortment user_topic_aggregation:
user_topic_aggregation:
{
_id: ObjectId('TTTT'),
consumer: ObjectId('AAAA'),
matter: ObjectId('CCCC')
post_count: 1,
last_post: ObjectId('PPPP')
},
{
_id: ObjectId('UUUU'),
consumer: ObjectId('AAAA'),
matter: ObjectId('DDDD')
post_count: 1,
last_post: ObjectId('QQQQ')
},
{
_id: ObjectId('VVVV'),
consumer: ObjectId('BBBB'),
matter: ObjectId('DDDD')
post_count: 2,
last_post: ObjectId('SSSS')
}
This assortment would have an index {'matter': 1, 'consumer': 1}. Then we might have the ability to get the variety of posts made by a consumer for a given matter with scanning only one key in an index. This new assortment can then additionally reside in a very separate MongoDB cluster, which isolates this workload out of your unique cluster.
What if we additionally wished to know the final time a consumer made a submit for a sure matter? This can be a question that MongoDB struggles to reply. You can also make use of the brand new aggregation assortment and retailer the ObjectId of the final submit for a given consumer/matter edge, which then helps you to simply discover the reply by working the ObjectId.getTimestamp() operate on the ObjectId of the final submit.
The tradeoff to doing that is that when making a brand new submit, that you must replace two collections as an alternative of 1, and it can’t be completed in a single atomic operation. This additionally means the denormalized knowledge within the aggregation assortment can change into inconsistent with the information within the unique two collections. There would then have to be a mechanism to detect and proper these inconsistencies.
It solely is smart to denormalize knowledge like this if the ratio of reads to updates is excessive, and it’s acceptable to your software to typically learn inconsistent knowledge. If you may be studying the denormalized knowledge often, however updating it a lot much less often, then it is smart to incur the price of dearer and sophisticated updates.
Abstract
As your utilization of your major MongoDB cluster grows, rigorously splitting the workload amongst a number of MongoDB clusters may also help you overcome scaling bottlenecks. It will possibly assist isolate your microservices from database failures, and in addition enhance efficiency of queries of disparate patterns. In subsequent blogs, I’ll discuss utilizing methods apart from MongoDB as secondary knowledge shops to allow question patterns that aren’t potential to run in your major MongoDB cluster(s).

Different MongoDB sources: