
{kind=link}
Introduction
NLP (Pure Language Processing) may also help us to grasp big quantities of textual content information. As an alternative of going by means of an enormous quantity of paperwork by hand and studying them manually, we will make use of those methods to hurry up our understanding and get to the primary messages rapidly. On this blogpost, we dive into the potential for utilizing panda information frames and NLP instruments in Python to get an concept of what folks wrote about when doing analysis on gender equality in Afghanistan utilizing Elicit. These insights may assist us to grasp what labored and what didn’t work to advance gender equality over the past a long time in a rustic that’s thought of to be one of the vital tough locations to be a girl or lady (World Financial Discussion board, 2023).
Studying Goal
- Acquire proficiency in textual content evaluation for textual content in CSV information.
- Purchase data on easy methods to do pure language processing in Python.
- Develop expertise in efficient information visualization for communication.
- Acquire insights on how analysis on gender equality in Afghanistan advanced over time.
This text was printed as part of the Information Science Blogathon.
Utilizing Elicit for Literature Critiques
To generate the underlying information, I take advantage of Elicit, a AI-powered instruments for Literature Critiques (Elicit). I ask the software to generate a listing of papers associated to the query: Why did gender equality fail in Afghanistan? I then obtain a ensuing listing of papers (I think about a random variety of greater than 150 papers) in CSV format. How does this information seem like? Let’s take a look!
Analyzing CSV Information from Elicit in Python
We’ll first learn within the CSV file as a pandas dataframe:
import pandas as pd
#Establish path and csv file
file_path="./elicit.csv"
#Learn in CSV file
df = pd.read_csv(file_path)
#Form of CSV
df.form
#Output: (168, 15)
#Present first rows of dataframe
df.head()The df.head() command reveals us the primary rows of the ensuing pandas dataframe. The dataframe consists of 15 columns and 168 rows. We generate this info with the df.form command. Let’s first discover through which yr most of those research have been printed. To discover this, we will reap the benefits of the column reporting the every paper’s yr of publication. There are a number of instruments to generate figures in Python, however let’s depend on the seaborn and matplotlib library right here. To investigate through which yr papers have been principally printed, we will reap the benefits of a so-called countplot, and in addition costumize the axis labels and axis ticks to make it look properly:
Analyzing the Well timed Distribution of Revealed Papers
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#Set determine measurement
plt.determine(figsize=(10,5))
#Producte a countplot
chart = sns.countplot(x=df["Year"], colour="blue")
#Set labels
chart.set_xlabel('Yr')
chart.set_ylabel('Variety of printed papers')
#Change measurement of xticks
# get label textual content
_, xlabels = plt.xticks()
# set the x-labels with
chart.set_xticklabels(xlabels, measurement=5)
plt.present()The info reveals that the variety of papers elevated over time, in all probability additionally on account of higher information availability and higher prospects to do analysis in Afghanistan after the Taliban ceased energy in 2001.
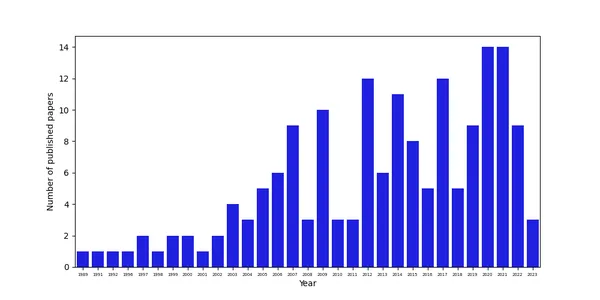
Analyzing the Content material of Papers
Variety of Phrases Written
Whereas this provides us a primary perception on analysis carried out on gender equality in Afghanistan, we’re principally keen on what researchers truly wrote about. To get an concept of the content material of those papers, we will reap the benefits of the summary, which Elicit kindly included for us within the CSV file the software generated for us. To do that, we will comply with customary procedures for textual content evaluation, such because the one outlined by Jan Kirenz in certainly one of his blogposts. We begin by merely counting the variety of phrases in every summary through the use of a lambda technique:
#Break up textual content of abstracts into a listing of phrases and calculate the size of the listing
df["Number of Words"] = df["Abstract"].apply(lambda n: len(n.cut up()))
#Print first rows
print(df[["Abstract", "Number of Words"]].head())
#Output:
Summary Variety of Phrases
0 As a standard society, Afghanistan has alwa... 122
1 The Afghanistan gender inequality index reveals ... 203
2 Cultural and non secular practices are essential ... 142
3 ABSTRACT Gender fairness could be a uncared for issu... 193
4 The collapse of the Taliban regime within the latt... 357
#Describe the column with the variety of phrases
df["Number of Words"].describe()
depend 168.000000
imply 213.654762
std 178.254746
min 15.000000
25% 126.000000
50% 168.000000
75% 230.000000
max 1541.000000Nice. A lot of the abstracts appear to be wealthy in phrases. They’ve on common 213.7 phrases. The minimal summary solely consists of 15 phrases, nevertheless, whereas the utmost summary has 1,541 phrases.
What do Researchers Write About?
Now that we all know that the majority abstracts are wealthy of data, let’s ask what they principally write about. We will accomplish that by making a frequency distribution for every phrase written. Nevertheless, we aren’t keen on sure phrases, corresponding to stopwords. Consequently, we have to do some textual content processing:
# First, rework all to decrease case
df['Abstract_lower'] = df['Abstract'].astype(str).str.decrease()
df.head(3)#import csv
# Let's tokenize the column
from nltk.tokenize import RegexpTokenizer
regexp = RegexpTokenizer('w+')
df['text_token']=df['Abstract_lower'].apply(regexp.tokenize)
#Present the primary rows of the brand new dataset
df.head(3)
# Take away stopwords
import nltk
nltk.obtain('stopwords')
from nltk.corpus import stopwords
# Make a listing of english stopwords
stopwords = nltk.corpus.stopwords.phrases("english")
# Lengthen the listing with your individual customized stopwords
my_stopwords = ['https']
stopwords.prolong(my_stopwords)
# Take away stopwords with lampda perform
df['text_token'] = df['text_token'].apply(lambda x: [item for item in x if item not in stopwords])
#Present the primary rows of the dataframe
df.head(3)
# Take away rare phrases (phrases shorter than or equal to 2 letters)
df['text_string'] = df['text_token'].apply(lambda x: ' '.be part of([item for item in x if len(item)>2]))
#Present the primary rows of the dataframe
df[['Abstract_lower', 'text_token', 'text_string']].head()What we do right here is to first rework all phrases into decrease case, and to tokenize them later by way of pure language processing instruments. Phrase tokenization is an important step in pure language processing and means splitting down textual content into particular person phrases (tokens). We use the RegexpTokenizer and tokenize the textual content of our abstracts based mostly on alphanumeric traits (denoted by way of ‘w+’). Retailer the ensuing tokens within the column text_token. We then take away stopwords from this listing of tokens through the use of the dictionary of the pure language processing toolbox of nltk, the Python NLTK (Pure Language Toolkit) library. Delete phrases which can be shorter than two letters. This kind of textual content processing helps us to focus our evaluation on extra significant phrases.
Generate Phrase Cloud
To visually analyze the ensuing listing of phrases, we generate a listing of strings from the textual content we processed and tokenize this listing after which generate a phrase cloud:
from wordcloud import WordCloud
# Create a listing of phrases
all_words=" ".be part of([word for word in df['text_string']])
# Phrase Cloud
wordcloud = WordCloud(width=600,
peak=400,
random_state=2,
max_font_size=100).generate(all_words)
plt.determine(figsize=(10, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off');
The phrase cloud reveals that these phrases talked about principally are these additionally forming a part of our search question: afghanistan, gender, gender equality. Nevertheless, another phrases which can be substitutes additionally kind a part of the listing of most talked about phrases: men and women. These phrases per se should not very informative, however some others are: inside the analysis on gender equality in Afghanistan, researchers appear to be very involved about training, human rights, society, and the state. Surprisingly, Pakistan additionally types a part of the listing. This might imply that outcomes generated to the search question are imprecise and in addition included analysis on gender equality on Afghanistan, though we didn’t ask for it. Alternatively, they might imply that gender equality of Afghan girls can also be an essential analysis matter in Pakistan, perhaps on account of many Afghans settling in in Pakistan on account of the tough state of affairs of their house nation.
Analyze the Sentiment of Authors
Ideally, analysis can be impartial and freed from feelings or opinions. Nevertheless, it’s inside our human nature to have opinions and sentiments. To analyze to which extent researchers mirror their very own sentiments in what they write about, we will do a sentiment evaluation. Sentiment analyses are strategies to research if a set of textual content is constructive, impartial, or detrimental. In our instance, we’ll use the VADER Sentiment Evaluation Instrument. VADER stands for Valence Conscious Dictionary and Sentiment Reasoner, and is a lexicon and rule-based sentiment evaluation software.
How the VADER sentiment evaluation software works, is that it makes use of a pre-built sentiment lexicon that consists of an unlimited variety of phrases with related sentiments. It additionally considers grammatical guidelines to detect the sentiment polarity (constructive, impartial, and detrimental) of quick texts. The software leads to a sentiment rating (additionally known as the compound rating) based mostly on the sentiment of every phrase and the grammatical guidelines within the textual content. This rating ranges from -1 to 1. Values above zero are constructive and values beneath zero are detrimental. Because the software depends on a prebuilt sentiment lexicon, it doesn’t require complicated machine studying fashions or intensive fashions.
# Entry to the required lexicon containing sentiment scores for phrases
nltk.obtain('vader_lexicon')
# Initializes the sentiment analyzer object
from nltk.sentiment import SentimentIntensityAnalyzer
#Calculate the sentiment polarity scores with analyzer
analyzer = SentimentIntensityAnalyzer()
# Polarity Rating Methodology - Assign outcomes to Polarity Column
df['polarity'] = df['text_string'].apply(lambda x: analyzer.polarity_scores(x))
df.tail(3)
# Change information construction - Concat authentic dataset with new columns
df = pd.concat(
[df,
df['polarity'].apply(pd.Sequence)], axis=1)
#Present construction of recent column
df.head(3)
#Calculate imply worth of compound rating
df.compound.imply()
#Output: 0.20964702380952382The code above generates a polarity rating that ranges from -1 to 1 for every summary, right here denoted because the compound rating. The imply worth is above zero, so a lot of the analysis has a constructive connotation. How did this transformation over time? We will merely plot the feelings by yr:
# Lineplot
g = sns.lineplot(x='Yr', y='compound', information=df)
#Alter labels and title
g.set(title="Sentiment of Summary")
g.set(xlabel="Yr")
g.set(ylabel="Sentiment")
#Add a gray line to point zero (the impartial rating) to divide constructive and detrimental scores
g.axhline(0, ls="--", c="gray")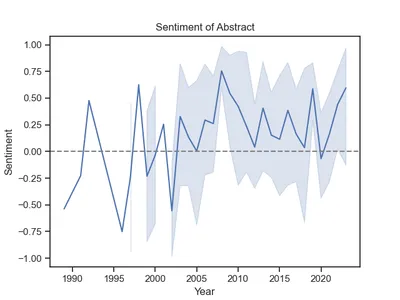
Attention-grabbing. A lot of the analysis was constructive ranging from 2003 onwards. Earlier than that, sentiments fluctuates extra considerably and have been extra detrimental, on common, in all probability because of the tough state of affairs of ladies in Afghanistan.
Conclusion
Pure Language Processing may also help us to generate useful insights into giant quantities of textual content. What we realized right here from almost 170 papers is that training and human rights have been a very powerful matters within the analysis papers gathered by Elicit, and that researchers began to put in writing extra positively about gender equality in Afghanistan from 2003 onwards, shortly after the Taliban ceased energy in 2001.
Key Takeaways
- We will use Pure Language Processing Instruments to achieve fast insights into the primary matters studied in a sure analysis area.
- Phrase Clouds are nice visualization instruments to get an understanding of essentially the most generally used phrases in a textual content.
- Sentiment Evaluation reveals that analysis may not be as impartial as anticipated.
I hope you discovered this text informative. Be at liberty to succeed in out to me on LinkedIn. Let’s join and work in direction of leveraging information for good!
Regularly Requested Questions
A. Elicit is a web-based platform designed to assist researchers in finding AI papers and analysis information. By merely posing a analysis query, Elicit leverages its huge database of 175 million articles to uncover related solutions. Furthermore, it gives the performance to make the most of Elicit for analyzing your individual papers. Moreover, Elicit boasts a user-friendly interface, making certain easy navigation and accessibility.
A. Pure Language Processing (NLP) is a specialised department inside the area of synthetic intelligence (AI). Its main goal is to allow machines to grasp and analyze human language, permitting them to automate varied repetitive duties. Some frequent functions of NLP embrace machine translation, summarization, ticket classification, and spellchecking.
A. There are a number of approaches to calculating a sentiment rating, however the extensively used technique includes using a dictionary of phrases categorised as detrimental, impartial, or constructive. The textual content is subsequently examined to find out the presence of detrimental and constructive phrases, permitting for an estimation of the general sentiment conveyed by the textual content.
A. The compound rating is derived by including up the valence scores of particular person phrases within the lexicon, bearing in mind relevant guidelines, and subsequently normalizing the rating to vary between -1 (indicating extremely detrimental sentiment) and +1 (indicating extremely constructive sentiment). This metric is especially useful when searching for a singular, one-dimensional measure of sentiment.
References
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.