

{kind=link}
Google introduced a outstanding rating framework known as Time period Weighting BERT (TW-BERT) that improves search outcomes and is simple to deploy in present rating programs.
Though Google has not confirmed that it’s utilizing TW-BERT, this new framework is a breakthrough that improves rating processes throughout the board, together with in question growth. It’s additionally straightforward to deploy, which for my part, makes it likelier to be in use.
TW-BERT has many co-authors, amongst them is Marc Najork, a Distinguished Analysis Scientist at Google DeepMind and a former Senior Director of Analysis Engineering at Google Analysis.
He has co-authored many analysis papers on matters of associated to rating processes, and plenty of different fields.
Among the many papers Marc Najork is listed as a co-author:
- On Optimizing Prime-Ok Metrics for Neural Rating Fashions – 2022
- Dynamic Language Fashions for Repeatedly Evolving Content material – 2021
- Rethinking Search: Making Area Consultants out of Dilettantes – 2021
- Characteristic Transformation for Neural Rating Fashions – – 2020
- Studying-to-Rank with BERT in TF-Rating – 2020
- Semantic Textual content Matching for Lengthy-Type Paperwork – 2019
- TF-Rating: Scalable TensorFlow Library for Studying-to-Rank – 2018
- The LambdaLoss Framework for Rating Metric Optimization – 2018
- Studying to Rank with Choice Bias in Private Search – 2016
What’s TW-BERT?
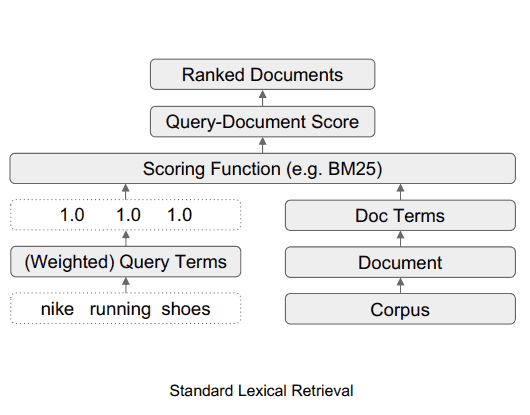
TW-BERT is a rating framework that assigns scores (known as weights) to phrases inside a search question in an effort to extra precisely decide what paperwork are related for that search question.
TW-BERT can also be helpful in Question Enlargement.
Question Enlargement is a course of that restates a search question or provides extra phrases to it (like including the phrase “recipe” to the question “hen soup”) to raised match the search question to paperwork.
Including scores to the question helps it higher decide what the question is about.
TW-BERT Bridges Two Data Retrieval Paradigms
The analysis paper discusses two completely different strategies of search. One that’s statistics based mostly and the opposite being deep studying fashions.
There follows a dialogue about the advantages and the shortcomings of those completely different strategies and recommend that TW-BERT is a approach to bridge the 2 approaches with none of the shortcomings.
They write:
“These statistics based mostly retrieval strategies present environment friendly search that scales up with the corpus dimension and generalizes to new domains.
Nevertheless, the phrases are weighted independently and don’t contemplate the context of your entire question.”
The researchers then be aware that deep studying fashions can determine the context of the search queries.
It’s defined:
“For this downside, deep studying fashions can carry out this contextualization over the question to offer higher representations for particular person phrases.”
What the researchers are proposing is the usage of TW-Bert to bridge the 2 strategies.
The breakthrough is described:
“We bridge these two paradigms to find out that are probably the most related or non-relevant search phrases within the question…
Then these phrases may be up-weighted or down-weighted to permit our retrieval system to provide extra related outcomes.”
Instance of TW-BERT Search Time period Weighting
The analysis paper gives the instance of the search question, “Nike trainers.”
In easy phrases, the phrases “Nike trainers” are three phrases {that a} rating algorithm should perceive in the way in which that the searcher intends it to be understood.
They clarify that emphasizing the “operating” a part of the question will floor irrelevant search outcomes that comprise manufacturers aside from Nike.
In that instance, the model identify Nike is vital and due to that the rating course of ought to require that the candidate webpages comprise the phrase Nike in them.
Candidate webpages are pages which are being thought-about for the search outcomes.
What TW-BERT does is present a rating (known as weighting) for every a part of the search question in order that it is smart in the identical approach that it does the one that entered the search question.
On this instance, the phrase Nike is taken into account vital, so it must be given a better rating (weighting).
The researchers write:
“Due to this fact the problem is that we should be certain that Nike” is weighted excessive sufficient whereas nonetheless offering trainers within the closing returned outcomes.”
The opposite problem is to then perceive the context of the phrases “operating” and “sneakers” and that implies that the weighting ought to lean greater for becoming a member of the 2 phrases as a phrase, “trainers,” as a substitute of weighting the 2 phrases independently.
This downside and the answer is defined:
“The second facet is the best way to leverage extra significant n-gram phrases throughout scoring.
In our question, the phrases “operating” and “sneakers” are dealt with independently, which might equally match “operating socks” or “skate sneakers”.
On this case, we wish our retriever to work on an n-gram time period stage to point that “trainers” must be up-weighted when scoring.”
Fixing Limitations in Present Frameworks
The analysis paper summarizes conventional weighting as being restricted within the variations of queries and mentions that these statistics based mostly weighting strategies carry out much less effectively for zero-shot situations.
Zero-shot Studying is a reference to the power of a mannequin to resolve an issue that it has not been skilled for.
There’s additionally a abstract of the constraints inherent in present strategies of time period growth.
Time period growth is when synonyms are used to seek out extra solutions to go looking queries or when one other phrase is inferred.
For instance, when somebody searches for “hen soup,” it’s inferred to imply “hen soup recipe.”
They write in regards to the shortcomings of present strategies:
“…these auxiliary scoring features don’t account for extra weighting steps carried out by scoring features utilized in present retrievers, reminiscent of question statistics, doc statistics, and hyperparameter values.
This will alter the unique distribution of assigned time period weights throughout closing scoring and retrieval.”
Subsequent, the researchers state that deep studying has its personal baggage within the type of complexity of deploying them and unpredictable habits once they encounter new areas for which they weren’t pretrained on.
This then, is the place TW-BERT enters the image.
TW-BERT Bridges Two Approaches
The answer proposed is sort of a hybrid strategy.
Within the following quote, the time period IR means Data Retrieval.
They write:
“To bridge the hole, we leverage the robustness of present lexical retrievers with the contextual textual content representations supplied by deep fashions.
Lexical retrievers already present the aptitude to assign weights to question n-gram phrases when performing retrieval.
We leverage a language mannequin at this stage of the pipeline to offer acceptable weights to the question n-gram phrases.
This Time period Weighting BERT (TW-BERT) is optimized end-to-end utilizing the identical scoring features used throughout the retrieval pipeline to make sure consistency between coaching and retrieval.
This results in retrieval enhancements when utilizing the TW-BERT produced time period weights whereas retaining the IR infrastructure much like its present manufacturing counterpart.”
The TW-BERT algorithm assigns weights to queries to offer a extra correct relevance rating that the remainder of the rating course of can then work with.
Commonplace Lexical Retrieval
Time period Weighted Retrieval (TW-BERT)
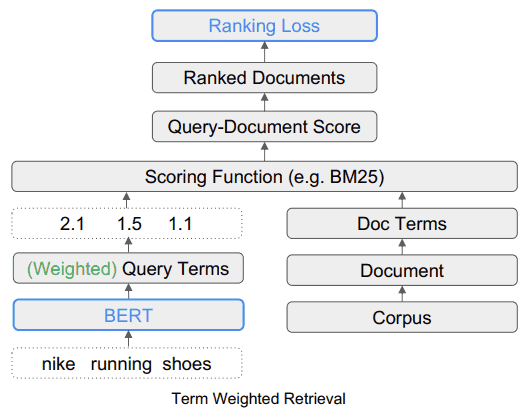
TW-BERT is Straightforward to Deploy
One of many benefits of TW-BERT is that it may be inserted straight into the present data retrieval rating course of, like a drop-in element.
“This allows us to straight deploy our time period weights inside an IR system throughout retrieval.
This differs from prior weighting strategies which must additional tune a retriever’s parameters to acquire optimum retrieval efficiency since they optimize time period weights obtained by heuristics as a substitute of optimizing end-to-end.”
What’s vital about this ease of deployment is that it doesn’t require specialised software program or updates to the {hardware} so as to add TW-BERT to a rating algorithm course of.
Is Google Utilizing TW-BERT Of their Rating Algorithm?
As talked about earlier, deploying TW-BERT is comparatively straightforward.
For my part, it’s cheap to imagine that the benefit of deployment will increase the chances that this framework might be added to Google’s algorithm.
Which means Google might add TW-BERT into the rating a part of the algorithm with out having to do a full scale core algorithm replace.
Except for ease of deployment, one other high quality to search for in guessing whether or not an algorithm might be in use is how profitable the algorithm is in enhancing the present state-of-the-art.
There are a lot of analysis papers that solely have restricted success or no enchancment. These algorithms are attention-grabbing however it’s cheap to imagine that they gained’t make it into Google’s algorithm.
Those which are of curiosity are these which are very profitable and that’s the case with TW-BERT.
TW-BERT may be very profitable. They stated that it’s straightforward to drop it into an present rating algorithm and that it performs in addition to “dense neural rankers”
The researchers defined the way it improves present rating programs:
“Utilizing these retriever frameworks, we present that our time period weighting technique outperforms baseline time period weighting methods for in-domain duties.
In out-of-domain duties, TW-BERT improves over baseline weighting methods in addition to dense neural rankers.
We additional present the utility of our mannequin by integrating it with present question growth fashions, which improves efficiency over normal search and dense retrieval within the zero-shot instances.
This motivates that our work can present enhancements to present retrieval programs with minimal onboarding friction.”
In order that’s two good explanation why TW-BERT would possibly already be part of Google’s rating algorithm.
- It’s an throughout the board enchancment to present rating frameworks
- It’s straightforward to deploy
If Google has deployed TW-BERT, then which will clarify the rating fluctuations that search engine marketing monitoring instruments and members of the search advertising and marketing group have been reporting for the previous month.
Generally, Google solely broadcasts some rating adjustments, notably once they trigger a noticeable impact, like when Google introduced the BERT algorithm.
Within the absence of official affirmation, we will solely speculate in regards to the chance that TW-BERT is part of Google’s search rating algorithm.
Nonetheless, TW-BERT is a outstanding framework that seems to enhance the accuracy of data retrieval programs and might be in use by Google.
Learn the unique analysis paper:
Finish-to-Finish Question Time period Weighting (PDF)
Google Analysis Webpage:
Finish-to-Finish Question Time period Weighting
Featured picture by Shutterstock/TPYXA Illustration