

{kind=link}
This can be a visitor submit by Khandu Shinde, Workers Software program Engineer and Edward Paget, Senior Software program Engineering at Chime Monetary.
Chime is a monetary expertise firm based on the premise that primary banking companies ought to be useful, straightforward, and free. Chime companions with nationwide banks to design member first monetary merchandise. This creates a extra aggressive market with higher, lower-cost choices for on a regular basis Individuals who aren’t being served properly by conventional banks. We assist drive innovation, inclusion, and entry throughout the trade.
Chime has a accountability to guard our members in opposition to unauthorized transactions on their accounts. Chime’s Danger Evaluation staff continually screens developments in our information to seek out patterns that point out fraudulent transactions.
This submit discusses how Chime makes use of AWS Glue, Amazon Kinesis, Amazon DynamoDB, and Amazon SageMaker to construct an internet, serverless fraud detection answer — the Chime Streaming 2.0 system.
Drawback assertion
To be able to sustain with the fast motion of fraudsters, our determination platform should repeatedly monitor consumer occasions and reply in real-time. Nonetheless, our legacy information warehouse-based answer was not outfitted for this problem. It was designed to handle complicated queries and enterprise intelligence (BI) use instances on a big scale. Nonetheless, with a minimal information freshness of 10 minutes, this structure inherently didn’t align with the close to real-time fraud detection use case.
To make high-quality choices, we have to accumulate consumer occasion information from varied sources and replace danger profiles in actual time. We additionally want to have the ability to add new fields and metrics to the danger profiles as our staff identifies new assaults, while not having engineering intervention or complicated deployments.
We determined to discover streaming analytics options the place we are able to seize, remodel, and retailer occasion streams at scale, and serve rule-based fraud detection fashions and machine studying (ML) fashions with milliseconds latency.
Resolution overview
The next diagram illustrates the design of the Chime Streaming 2.0 system.
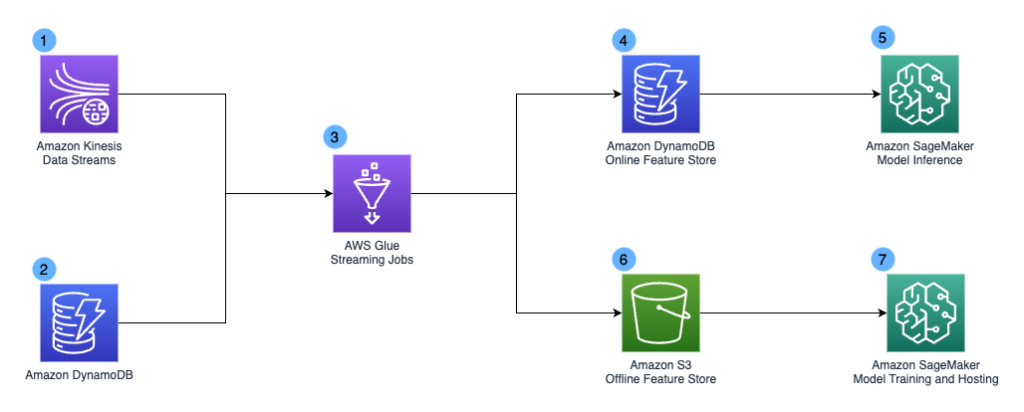
The design included the next key elements:
- We’ve got Amazon Kinesis Knowledge Streams as our streaming information service to seize and retailer occasion streams at scale. Our stream pipelines seize varied occasion varieties, together with consumer enrollment occasions, consumer login occasions, card swipe occasions, peer-to-peer funds, and software display screen actions.
- Amazon DynamoDB is one other information supply for our Streaming 2.0 system. It acts as the applying backend and shops information reminiscent of blocked gadgets checklist and device-user mapping. We primarily use it as lookup tables in our pipeline.
- AWS Glue jobs type the spine of our Streaming 2.0 system. The easy AWS Glue icon within the diagram represents 1000’s of AWS Glue jobs performing totally different transformations. To attain the 5-15 seconds end-to-end information freshness service stage settlement (SLA) for the Steaming 2.0 pipeline, we use streaming ETL jobs in AWS Glue to eat information from Kinesis Knowledge Streams and apply near-real-time transformation. We select AWS Glue primarily because of its serverless nature, which simplifies infrastructure administration with computerized provisioning and employee administration, and the flexibility to carry out complicated information transformations at scale.
- The AWS Glue streaming jobs generate derived fields and danger profiles that get saved in Amazon DynamoDB. We use Amazon DynamoDB as our on-line function retailer because of its millisecond efficiency and scalability.
- Our functions name Amazon SageMaker Inference endpoints for fraud detections. The Amazon DynamoDB on-line function retailer helps real-time inference with single digit millisecond question latency.
- We use Amazon Easy Storage Service (Amazon S3) as our offline function retailer. It incorporates historic consumer actions and different derived ML options.
- Our information scientist staff can entry the dataset and carry out ML mannequin coaching and batch inferencing utilizing Amazon SageMaker.
AWS Glue pipeline implementation deep dive
There are a number of key design ideas for our AWS Glue Pipeline and the Streaming 2.0 mission.
- We need to democratize our information platform and make the info pipeline accessible to all Chime builders.
- We need to implement cloud monetary backend companies and obtain value effectivity.
To attain information democratization, we would have liked to allow totally different personas within the group to make use of the platform and outline transformation jobs shortly, with out worrying in regards to the precise implementation particulars of the pipelines. The information infrastructure staff constructed an abstraction layer on high of Spark and built-in companies. This layer contained API wrappers over built-in companies, job tags, scheduling configurations and debug tooling, hiding Spark and different lower-level complexities from finish customers. Because of this, finish customers have been in a position to outline jobs with declarative YAML configurations and outline transformation logic with SQL. This simplified the onboarding course of and accelerated the implementation part.
To attain value effectivity, our staff constructed a value attribution dashboard primarily based on AWS value allocation tags. We enforced tagging with the above abstraction layer and had clear value attribution for all AWS Glue jobs all the way down to the staff stage. This enabled us to trace down much less optimized jobs and work with job homeowners to implement finest practices with impact-based precedence. One widespread misconfiguration we discovered was sizing of AWS Glue jobs. With information democratization, many customers lacked the information to right-size their AWS Glue jobs. The AWS staff launched AWS Glue auto scaling to us as an answer. With AWS Glue Auto Scaling, we not wanted to plan AWS Glue Spark cluster capability prematurely. We may simply set the utmost variety of staff and run the roles. AWS Glue screens the Spark software execution, and allocates extra employee nodes to the cluster in near-real time after Spark requests extra executors primarily based on our workload necessities. We observed a 30–45% value saving throughout our AWS Glue Jobs as soon as we turned on Auto Scaling.
Conclusion
On this submit, we confirmed you ways Chime’s Streaming 2.0 system permits us to ingest occasions and make them accessible to the choice platform simply seconds after they’re emitted from different companies. This permits us to jot down higher danger insurance policies, present brisker information for our machine studying fashions, and shield our members from unauthorized transactions on their accounts.
Over 500 builders in Chime are utilizing this streaming pipeline and we ingest greater than 1 million occasions per second. We comply with the sizing and scaling course of from the AWS Glue streaming ETL jobs finest practices weblog and land on a 1:1 mapping between Kinesis Shard and vCPU core. The top-to-end latency is lower than 15 seconds, and it improves the mannequin rating calculation velocity by 1200% in comparison with legacy implementation. This method has confirmed to be dependable, performant, and cost-effective at scale.
We hope this submit will encourage your group to construct a real-time analytics platform utilizing serverless applied sciences to speed up your online business targets.
Concerning the Authors
 Khandu Shinde is a Workers Engineer centered on Large Knowledge Platforms and Options for Chime. He helps to make the platform scalable for Chime’s enterprise wants with architectural route and imaginative and prescient. He’s primarily based in San Francisco the place he performs cricket and watches motion pictures.
Khandu Shinde is a Workers Engineer centered on Large Knowledge Platforms and Options for Chime. He helps to make the platform scalable for Chime’s enterprise wants with architectural route and imaginative and prescient. He’s primarily based in San Francisco the place he performs cricket and watches motion pictures.
 Edward Paget is a Software program Engineer engaged on constructing Chime’s capabilities to mitigate danger to make sure our members’ monetary peace of thoughts. He enjoys being on the intersection of massive information and programming language concept. He’s primarily based in Chicago the place he spends his time operating alongside the lake shore.
Edward Paget is a Software program Engineer engaged on constructing Chime’s capabilities to mitigate danger to make sure our members’ monetary peace of thoughts. He enjoys being on the intersection of massive information and programming language concept. He’s primarily based in Chicago the place he spends his time operating alongside the lake shore.
 Dylan Qu is a Specialist Options Architect centered on Large Knowledge & Analytics with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS.
Dylan Qu is a Specialist Options Architect centered on Large Knowledge & Analytics with Amazon Internet Companies. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS.