
{kind=link}
Introduction
Figuring out the next phrase is the duty of next-word prediction, often known as language modeling. One of many NLP‘s benchmark duties is language modeling. In its most elementary type, it entails choosing the phrase that follows a string of phrases based mostly on them that’s most probably to happen. In many various fields, language modeling has all kinds of functions.

Studying Goal
- Acknowledge the underlying concepts and rules behind the quite a few fashions utilized in statistical evaluation, machine studying, and information science.
- Learn to create predictive fashions, together with regression, classification, clustering, and many others., to generate exact predictions and kinds based mostly on information.
- Perceive the rules of overfitting and underfitting, and learn to consider mannequin efficiency utilizing measures like accuracy, precision, recall, and many others.
- Learn to preprocess information and establish pertinent traits for modeling.
- Learn to tweak hyperparameters and optimize fashions utilizing grid search and cross-validation.
This text was printed as part of the Information Science Blogathon.
Functions of Language Modeling
Listed below are some notable functions of language modeling:
Cellular Keyboard Textual content Advice
A operate on smartphone keyboards referred to as cell keyboard textual content advice, or predictive textual content or auto-suggestions, suggests phrases or phrases as you write. It seeks to make typing quicker and fewer error-prone and to supply extra exact and contextually acceptable suggestions.
Additionally Learn: Constructing a Content material-Primarily based Advice System

Google Search Auto-Completion
Each time we use a search engine like Google to search for something, we obtain many concepts, and as we preserve including phrases, the suggestions develop higher and extra related to our present search. How will it occur, then?

Pure language processing (NLP) know-how makes it possible. Right here, we’ll make use of pure language processing (NLP) to create a prediction mannequin using a bidirectional LSTM (Lengthy short-term reminiscence) mannequin to predict the sentence’s remaining phrases.
Be taught Extra: What’s LSTM? Introduction to Lengthy Quick-Time period Reminiscence
Import Essential Libraries and Packages
Importing the required libraries and packages to assemble a next-word prediction mannequin utilizing a bidirectional LSTM can be finest. A pattern of the libraries you’ll usually require is proven beneath:
import pandas as pd
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.textual content import Tokenizer
from tensorflow.keras.fashions import Sequential
from tensorflow.keras.optimizers import AdamDataset Info
Understanding the options and attributes of the dataset you’re coping with requires information. The next seven publications’ medium articles, chosen at random and printed in 2019, are included on this dataset:
- In direction of Information Science
- UX Collective
- The Startup
- The Writing Cooperative
- Information Pushed Investor
- Higher People
- Higher Advertising
Dataset Hyperlink: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/enter
medium_data = pd.read_csv('../enter/medium-articles-dataset/medium_data.csv')
medium_data.head()
Right here, we now have ten totally different fields and 6508 data however we are going to solely use the title subject for predicting the following phrase.
print("Variety of data: ", medium_data.form[0])
print("Variety of fields: ", medium_data.form[1])
By wanting via and comprehending the dataset data, it’s possible you’ll select the preprocessing procedures, mannequin, and analysis metrics to your subsequent phrase prediction problem.
Show Titles of Varied Articles and Preprocess Them
Let’s take a look at a couple of pattern titles as an instance the preparation of article titles:
medium_data['title']
Eradicating Undesirable Characters and Phrases in Titles
Preprocessing textual content information for prediction duties typically contains eradicating undesirable letters and phrases from titles. Undesirable letters and phrases would possibly contaminate the information with noise and add pointless complexity, thereby reducing the mannequin’s efficiency and accuracy.
- Undesirable Characters:
- Punctuation: It’s best to take away exclamation factors, query marks, commas, and different punctuation. Sometimes, you may safely discard them as a result of they often don’t assist with the prediction project
- Particular Characters: Take away non-alphanumeric symbols, equivalent to greenback indicators, @ symbols, hashtags, and different particular characters, which are pointless for the prediction job.
- HTML Tags: If the titles have HTML markups or tags, take away them utilizing the right instruments or libraries to extract the textual content.
- Undesirable Phrases:
- Cease Phrases: Take away widespread cease phrases equivalent to “a,” “an,” “the,” “is,” “in,” and different steadily occurring phrases that don’t carry vital that means or predictive energy.
- Irrelevant Phrases: Establish and take away particular phrases that aren’t related to the prediction activity or area. For instance, if you’re predicting film genres, phrases like “film” or “movie” could not present useful data.
medium_data['title'] = medium_data['title'].apply(lambda x: x.change(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.change('u200a',' '))
Tokenization
Tokenization divides the textual content into tokens, phrases, subwords, or characters after which assigns a singular ID or index to every token, making a phrase index or Vocabulary.
The tokenization course of entails the next steps:
Textual content preprocessing: Preprocess the textual content by eliminating punctuation, altering it to lowercase, and caring for any explicit task- or domain-specific wants.
Tokenization: Dividing the preprocessed textual content into separate tokens by predetermined guidelines or strategies. Common expressions, separating by whitespace, and using specialised tokenizers are all widespread tokenization strategies.
Rising Vocabulary You can also make a dictionary, additionally referred to as a phrase index, by assigning every token a singular ID or index. On this course of, every ticket is mapped to the related index worth.
tokenizer = Tokenizer(oov_token='<oov>') # For these phrases which aren't present in word_index
tokenizer.fit_on_texts(medium_data['title'])
total_words = len(tokenizer.word_index) + 1
print("Complete variety of phrases: ", total_words)
print("Phrase: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Sturdy: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])By reworking textual content right into a vocabulary or phrase index, you may create a lookup desk representing the textual content as a set of numerical indexes. Every distinctive phrase within the textual content receives a corresponding index worth, permitting for additional processing or modeling operations that require numerical enter.

Titles Textual content into Sequences and Make N_gram Mannequin.
These levels can be utilized to construct an n-gram mannequin for correct prediction based mostly on title sequences:
- Convert Titles to Sequences: Use a tokenizer to show every title right into a string of tokens or manually separate every slip into its constituent phrases. Assign every phrase within the lexicon a definite quantity index.
- Generate n-grams: From the sequences, make n-grams. A steady run of n-title tokens known as an n-gram.
- Rely the Frequency: Decide the frequency at which every n-gram seems within the dataset.
- Construct the n-gram Mannequin: Create the n-gram mannequin utilizing the n-gram frequencies. The mannequin retains monitor of every token chance given the earlier n-1 tokens. This may be displayed as a lookup desk or a dictionary.
- Predict the Subsequent Phrase: The anticipated subsequent token in an n-1-token sequence could also be recognized utilizing the n-gram mannequin. To do that, it’s obligatory to search out the chance within the algorithm and choose a token with the best probability.
Be taught Extra: What Are N-grams and Implement Them in Python?
You should use these levels to construct an n-gram mannequin that makes use of the titles’ sequences to foretell the following phrase or token. Primarily based on the coaching information, this methodology can produce correct predictions because it captures the statistical relationships and tendencies within the language utilization of the titles.

input_sequences = []
for line in medium_data['title']:
token_list = tokenizer.texts_to_sequences([line])[0]
#print(token_list)
for i in vary(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# print(input_sequences)
print("Complete enter sequences: ", len(input_sequences))
Make All Titles the Similar Size by Utilizing Padding
Chances are you’ll use padding to make sure that every title is similar measurement by following these steps:
- Discover the longest title in your dataset by evaluating all the opposite titles.
- Repeat this course of for every title, evaluating each’s size to the general restrict.
- When a title is simply too quick, it ought to be prolonged utilizing a particular padding token or character.
- For every title in your dataset, perform the padding process once more.
Padding will be certain that all titles are the identical size and can present consistency for post-processing or mannequin coaching.
# pad sequences
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Put together Options and Labels
Within the given situation, if we think about the final component of every enter sequence because the label, we are able to carry out one-hot encoding on the titles to signify them as vectors comparable to the overall variety of distinctive phrases.
# create options and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)
print(xs[5])
print(labels[5])
print(ys[5][14])
The Structure of Bidirectional LSTM Neural Community
Recurrent neural networks (RNNs) with Lengthy Quick-Time period Reminiscence (LSTM) can gather and maintain data throughout in depth sequences. LSTM networks use specialised reminiscence cells and gating strategies to beat the constraints of normal RNNs, which steadily battle with the vanishing gradient drawback and have hassle sustaining long-term dependence.
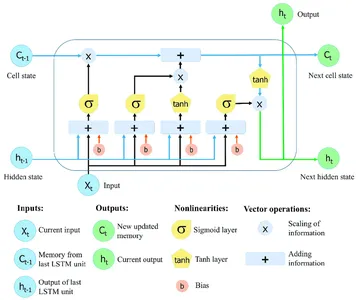
The essential characteristic of LSTM networks is the cell state, which serves as a reminiscence unit that may retailer data over time. The cell state is protected and managed by three fundamental gates: the neglect gate, the enter gate, and the output gate. These gates regulate the movement of knowledge into, out of, and inside the LSTM cell, permitting the community to recollect or neglect data at totally different time steps selectively.
Be taught Extra: Lengthy Quick Time period Reminiscence | Structure Of LSTM
Bidirectional LSTM
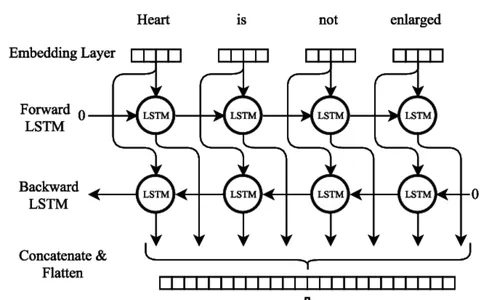
Bi-LSTM Neural Community Mannequin coaching
Quite a few essential procedures should be adopted whereas coaching a bidirectional LSTM (Bi-LSTM) neural community mannequin. Step one is compiling a coaching dataset with enter and output sequences comparable to them, indicating the following phrase. The textual content information should be preprocessed by being divided into separate traces, eradicating the punctuation, and altering the case to lowercase.
mannequin = Sequential()
mannequin.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
mannequin.add(Bidirectional(LSTM(150)))
mannequin.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
mannequin.compile(loss="categorical_crossentropy", optimizer=adam, metrics=['accuracy'])
historical past = mannequin.match(xs, ys, epochs=50, verbose=1)
#print mannequin.abstract()
print(mannequin)
By calling the match() methodology, the mannequin is educated. The coaching information consists of the enter sequences (xs) and matching output sequences (ys). The mannequin proceeds via 50 iterations, going via the entire coaching set. In the course of the coaching course of, the coaching progress is proven (verbose=1).

Plotting Mannequin Accuracy and Loss
Plotting a mannequin’s accuracy and loss all through coaching gives insightful details about how properly it performs and the way coaching goes. The error or disparity between the anticipated and precise values known as loss. Whereas the share of correct predictions generated by the mannequin is named accuracy.
import matplotlib.pyplot as plt
def plot_graphs(historical past, string):
plt.plot(historical past.historical past[string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.present()
plot_graphs(historical past, 'accuracy')
plot_graphs(historical past, 'loss')
Predicting the Subsequent Phrase of the Title
An interesting problem in pure language processing is guessing the next phrase in a title. Fashions can suggest the most probably discuss by searching for patterns and correlations in textual content information. This predictive energy makes functions like textual content suggestion programs and autocomplete potential. Refined approaches like RNNs and transformer-based architectures improve accuracy and seize contextual relationships.
seed_text = "implementation of"
next_words = 2
for _ in vary(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = mannequin.predict_classes(token_list, verbose=0)
output_word = ""
for phrase, index in tokenizer.word_index.gadgets():
if index == predicted:
output_word = phrase
break
seed_text += " " + output_word
print(seed_text)
Conclusion
In conclusion, coaching a mannequin to foretell the following phrase in a string of phrases is the thrilling pure language processing problem often called next-word prediction utilizing a Bidirectional LSTM. Right here’s the conclusion summarized in bullet factors:
- The potent deep studying structure BI-LSTM for sequential information processing could seize long-range relationships and phrase context.
- To organize uncooked textual content information for BI-LSTM coaching, information preparation is crucial. This contains tokenization, vocabulary technology, and textual content vectorization.
- Making a loss operate, constructing the mannequin utilizing an optimizer, becoming it to preprocessed information, and assessing its efficiency on validation units are the steps in coaching the BI-LSTM mannequin.
- BI-LSTM subsequent phrase prediction takes a mix of theoretical information and hands-on experimentation to grasp.
- Auto-completion, language creation, and textual content suggestion algorithms are examples of next-word prediction mannequin functions.
Functions for next-word prediction embody chatbots, machine translation, and textual content completion. You possibly can create extra exact and context-aware next-word prediction fashions with extra analysis and enchancment.
Regularly Requested Questions
A. Subsequent phrase prediction is a NLP activity the place a mannequin predicts the most probably phrase to comply with a given sequence of phrases or context. It goals to generate coherent and contextually related ideas for the following phrase based mostly on the patterns and relationships realized from coaching information.
A. Subsequent-word prediction generally makes use of Recurrent Neural Networks (RNNs) and their variants, equivalent to Lengthy Quick-Time period Reminiscence (LSTM) and Gated Recurrent Unit (GRU). Moreover, fashions like Transformer-based architectures, such because the GPT (Generative Pre-trained Transformer) fashions, have additionally proven vital developments on this activity.
A. Sometimes, when getting ready coaching information for next-word prediction, you break up textual content into sequences of phrases and create input-output pairs. The corresponding output represents the next phrase within the textual content for every enter sequence. Preprocessing the textual content entails eradicating punctuation, changing phrases to lowercase, and tokenizing the textual content into particular person phrases.
A. You possibly can consider the efficiency of a next-word prediction mannequin utilizing analysis metrics equivalent to perplexity, accuracy, or top-k accuracy. Perplexity measures how properly the mannequin predicts the following phrase given the context. Accuracy metrics evaluate the expected phrase with the bottom reality, whereas top-k accuracy considers the mannequin’s prediction inside the top-k most possible feedback.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.