

{kind=link}

(Cory Thoman/Shutterstock)
The potential for machines to be taught and get higher over time is among the large promoting factors for contemporary synthetic intelligence. However new analysis launched final week signifies that ChatGPT could in reality be getting worse at sure duties as time goes on.
In keeping with the first draft of a paper by Stanford College and UC Berkeley researchers, a substantial quantity of drift was detected within the outcomes of GPT-3.5 and GPT-4, the OpenAI giant language fashions (LLMs) that again the favored ChatGPT interface.
The three researchers–which incorporates Matei Zaharia, who’s an assistant professor at Stanford along with being a Databricks co-founder and the creator of Apache Spark, and UC Berkely’s Lingjiao Chen and James Zou–examined two totally different variations of the 2 LLMs, together with GPT-3.5 and GPT-4 as they existed in March 2023 and June 2023.
The researchers ran the 4 fashions towards a testbed of AI duties, together with math issues, answering delicate/harmful questions, answering opinion surveys, answering multi-hop knowledge-intensive questions, producing code, US Medical License exams, and visible reasoning.
The outcomes present fairly a little bit of variability within the solutions given by the LLMs. Specifically, the efficiency of GPT-4 in answering math issues was worse within the June model than within the March model, the researchers discovered. The accuracy price in appropriately figuring out prime numbers utilizing chain-of-thought (COT) prompting confirmed GPT-4’s accuracy dropping from 84.0% in March to 51.1% in June. On the identical time, GPT-3.5’s accuracy on the identical take a look at went from 49.6% in March to 76.2% in June.
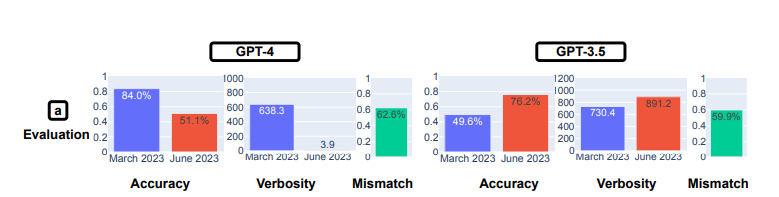
GPT-4’s math efficiency declined from March to June, whereas GPT-3.5’s went up, researchers from Stanford and UC Berkeley famous
The authors contemplated why GPT-4’s accuracy had dropped a lot, observing that the COT habits was totally different. The March model decomposed the duty into steps, because the researchers requested with the COT immediate. Nevertheless, the June model of GPT-4 didn’t give any intermediate steps or rationalization, and easily generated the reply (incorrectly) as “No.” (Even when GPT-4 had given the proper reply, it didn’t present its work, and would due to this fact have gotten the query unsuitable, the researchers identified.)
The same degree of drift was noticed with a second math query: recognizing “completely satisfied” numbers (“An integer known as completely satisfied if changing it by the sum of the sq. of its digits repeatedly ultimately produces 1, the researchers wrote). The researchers wrote that they “noticed vital efficiency drifts on this job,” the GPT-4’s accuracy dropping from 83.6% in March to 35.2% in June. GPT-3.5’s accuracy went up, from 30.6% to 48.2%. Once more, GPT-4 was noticed to not be following the COT instructions issued by the researchers.
Adjustments had been additionally noticed when researchers requested the LLMs delicate or harmful questions. GPT-4’s willingness to reply questions dropped over time, going from a 21.0% response price in March to a 5.0% price in June. GPT-3.5, conversely, acquired extra chatty, going from 2.0% to five.0%. The researchers concluded that “a stronger security layer” was adopted by OpenAI in GPT-4, whereas GPT-3.5 grew “much less conservative.”

(Ebru-Omer/Shutterstock)
The opinion survey take a look at revealed that GPT-4 grew considerably much less more likely to submit an opinion, dropping from a 97.6% response price in March to a 22.1% response price in March, whereas verbosity (or the variety of phrases) elevated by practically 30 proportion factors. GPT-3.5’s response price and verbosity remained practically unchanged.
On the subject of answering complicated questions that require “multi-hop reasoning,” vital variations in efficiency had been uncovered. The researchers mixed LangChain for its immediate engineering functionality with the HotpotQA Agent (for answering multi-hop questions) and famous that GPT-4’s accuracy elevated from 1.2% to 37.8% by way of producing a solution that’s an actual match. GPT-3.5’s “exact-match” success price declined from 22.8% to 14.0%, nonetheless.
On the code technology entrance, the researchers noticed that the output from each LLMs decreased by way of executability. Greater than 50% of GPT-4’s output was straight executable in March, whereas solely 10% was in June, and GPT-3.5 had an analogous decline. The researchers noticed that GPT started including non-code textual content, resembling additional apostrophes, to the Python output. They theorized that the additional non-code textual content was designed to make the code less difficult to render in a browser, nevertheless it made it non-executable.
A small lower in efficiency was famous for GPT-4 on the US Medical License Examination, from 86.6% to 82.4%, whereas GPT-3.5 went down lower than 1 proportion level, to 54.7%. Nevertheless, the solutions that GPT-4 acquired unsuitable modified over time, indicating that as some unsuitable solutions from March had been corrected, the LLM went from appropriate solutions to unsuitable solutions in June.
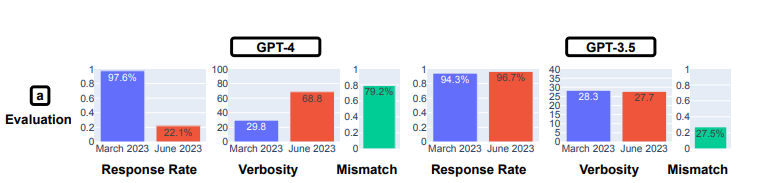
GPT-4’s willingness to have interaction in opinion surveys declined from March to June, Stanford and UC Berkeley researchers say
The visible reasoning assessments noticed small enhancements in each fashions. Nevertheless, the general price of accuracy (27.4% for GPT-4 and 12.2% for GPT-3.5) isn’t nice. And as soon as once more, the researchers noticed the fashions generated unsuitable solutions on questions which they’d appropriately answered beforehand.
The assessments present that the efficiency and habits of GPT-3.5 and GPT-4 have modified considerably over a brief time period, the researchers wrote.
“This highlights the necessity to constantly consider and assess the habits of LLM drifts in functions, particularly as it isn’t clear how LLMs resembling ChatGPT are up to date over time,” the wrote. “Our examine additionally underscores the problem of uniformly enhancing LLMs’ multifaceted talents. Bettering the mannequin’s efficiency on some duties, for instance with fine-tuning on further information, can have sudden uncomfortable side effects on its habits in different duties. According to this, each GPT-3.5 and GPT-4 acquired worse on some duties however noticed enhancements in different dimensions. Furthermore, the developments for GPT-3.5 and GPT-4 are sometimes divergent.”
You possibly can obtain a draft of the analysis paper, titled “How Is ChatGPT’s Conduct Altering over Time?,” at this hyperlink.
Associated Gadgets:
Hallucinations, Plagiarism, and ChatGPT
The Drawbacks of ChatGPT for Manufacturing Conversational AI Techniques
OpenAI’s New GPT-3.5 Chatbot Can Rhyme like Snoop Dogg