
{kind=link}
Introduction
502 and 504 errors generally is a nuisance for Rockset and our customers. For a lot of customers working customer-facing purposes on Rockset, availability and uptime are crucial, so even a single 5xx error is trigger for concern. As a cloud service, Rockset deploys code to our manufacturing clusters a number of instances every week, which implies that any part of our distributed system has to cease and restart with new code in an error-free means.
Lately, we launched into a product high quality push to diagnose and treatment lots of the causes of 502 and 504 errors that customers could encounter. It was not instantly apparent what these points had been since our logging appeared to point these error-producing queries didn’t attain our HTTP endpoints. Nonetheless, as product high quality and person expertise are at all times high of thoughts for us, we determined to research this difficulty completely to eradicate these errors.
Cluster setup

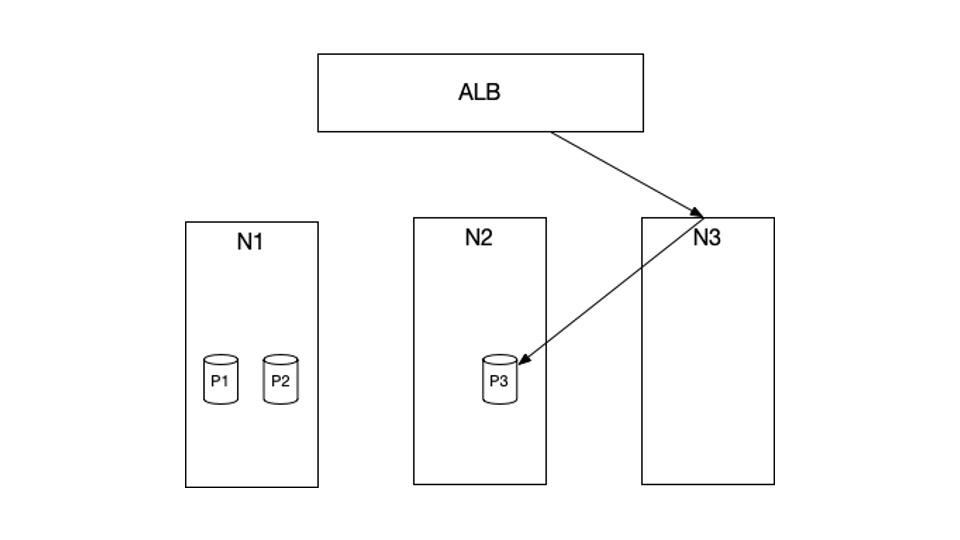
To diagnose the issue, we first want to grasp the setup of our cluster. Within the instance above, N1, N2, and N3 are the EC2 cases at the moment in our cluster. P1, P2 and P3 are Kubernetes pods which might be scheduled in these cases. Particularly, P1 and P2 are scheduled in N1, and P3 is scheduled in N2. There aren’t any pods which might be scheduled in N3.
HTTP requests from the net will first hit our AWS Utility Load Balancer (ALB), which can then ahead these requests to our cluster. The providers that obtain these HTTP requests from the ALB are arrange with NodePort sort. What meaning is, when a request hits the ALB, it’ll get routed to a random node, for instance, N3. N3 will then route this request to a pod P3, which might reside in a very totally different node.
We run kube-proxy in iptables mode. This implies the routing described above is finished by a part known as iptables, which is fairly environment friendly. Our HTTP servers are written in Java utilizing jetty.
With this setup, there are a number of points we uncovered as we investigated the random 502/504 errors.
Connection idle timeout misconfiguration
Connection idle timeout, or keep-alive timeout, is outlined because the period of time after which the connection shall be terminated if there is no such thing as a information. This act of termination could be initiated from each ends of the connection. Within the diagram above, each ALB and P3 can terminate the connection relying on the idle timeout setting. Which means if one finish has a smaller timeout, will probably be the one who terminates the connection.
The difficulty lay with the very fact our HTTP server (P3) had smaller connection idle timeout than the ALB. That meant it was doable that whereas there was an inflight request from ALB to P3, P3 terminates the connection. This may end in a 502 error as a result of the TCP connection has been closed.
The answer is that the facet that sends the request have to be the facet with smaller idle timeout. On this case, it is the ALB. We elevated the idle timeout in Jetty with ServerConnector::setIdleTimeout to repair this difficulty.
Draining isn’t arrange correctly
The ALB employs HTTP persistent connection when sending HTTP requests to our servers. What meaning is the ALB will reuse the TCP connection that was established in earlier HTTP requests in an effort to keep away from the price of TCP handshake.
The difficulty comes when the server (P3 on this case) desires to empty, probably attributable to our periodic code-push, and it doesn’t need to settle for any extra requests. Nonetheless, the ALB is unaware of this reality due to the NodePort sort of service. Recall that ALB is just conscious of the node N3, not the pod P3. Which means the ALB would nonetheless ship requests to N3. Because the TCP connection is reused, these requests would get routed to the draining pod P3. As soon as the draining interval completes, 502s will happen.
One option to repair that is to have each response from P3 embody a particular header, known as Connection: shut, when P3 is draining. This header will instruct the ALB to not reuse the outdated TCP connections and create new ones as a substitute. On this scenario, the brand new connections will not be routed to the draining pods.
One difficult half is that the draining interval have to be bigger than your service’s readiness probe interval, in order that kube-proxy from different nodes (together with N3) are conscious of P3 draining and replace their iptables guidelines accordingly.
Node abruptly faraway from cluster
When a brand new assortment is created, Rockset employs a mode known as bulk-ingest in an effort to conduct an preliminary dump of the supply information into the gathering. This mode is commonly very CPU intensive, so we’d like a particular sort of EC2 machine that’s compute-optimized. Internally, we name these bulk nodes. Since these machines are costlier, we solely spin them up when essential and terminate after we now not want them. This turned out to trigger 502s as nicely.
Keep in mind from earlier sections, requests are routed to a random node within the cluster, together with, on this case, the majority nodes. So when the majority nodes be part of the cluster, they’re out there for receiving and forwarding the requests as nicely. When the bulk-ingest is accomplished, we terminate these nodes in an effort to save on prices. The issue is we terminate these nodes too abruptly, closing the connection between this node and the ALB, inflicting the inflight requests to fail and producing 502 errors. We recognized this drawback by noticing that the 502 graph aligned with the graph of the variety of bulk nodes at the moment within the system. Each time variety of bulk nodes decreased, 502s occurred.
The repair for us was to make use of AWS lifecycle hooks to gracefully terminate these nodes, by ready for the inflight requests to complete earlier than truly terminating them.
Node isn’t able to route requests
Just like the earlier issues, this difficulty includes the node simply becoming a member of the cluster and never able to ahead requests. When a node joins the cluster, a number of set-up steps must occur earlier than visitors can stream between this new node and different nodes. For instance, kube-proxy on this new node must arrange iptables guidelines. Different nodes must replace the firewall to simply accept the visitors from the brand new node. These steps are executed asynchronously.
Which means, the ALB would oftentimes timeout whereas making an attempt to ascertain the connection to this new node, as this node would fail to ahead the TCP handshake request to different pods. This is able to trigger 504 errors.
We recognized this drawback by trying on the ALB log from AWS. By inspecting the goal node (the node that ALB determined to ahead the request to), we will see {that a} 504 error occurs when the goal node simply joins the cluster.
There are 2 methods to repair this: delay the node becoming a member of the ALB goal group by a couple of minutes or simply have a static set of nodes for routing. We don’t need to introduce pointless delays, so we go together with the latter strategy. We do that by making use of the label alpha.service-controller.kubernetes.io/exclude-balancer=true to the nodes we don’t need the ALB to path to.
Kubernetes bug
Having resolved the problems above, a number of 502s would nonetheless happen. Understandably, a k8s bug is the very last thing we might consider. Fortunately, a colleague of mine identified this text on a k8s bug inflicting intermittent connection resets, which matched our drawback. It is mainly a k8s bug from earlier than model 1.15. The workaround for that is to set ip_conntrack_tcp_be_liberal to keep away from marking packets as INVALID.
echo 1 > /proc/sys/internet/ipv4/netfilter/ip_conntrack_tcp_be_liberal
Conclusion
There could be many causes 502 and 504 errors can occur. Some are unavoidable, attributable to AWS eradicating nodes abruptly or your service OOMing or crashing. On this submit, I describe the problems that may be mounted by correct configuration.
Personally, this has been an incredible studying expertise. I realized so much about k8s networking and k8s basically. At Rockset, there are a lot of comparable challenges, and we’re aggressively hiring. Should you’re , please drop me a message!