

{kind=link}
This submit is the primary of a two-part sequence relating to checkpointing mechanisms and in-flight information buffering. On this first half, we clarify among the elementary Apache Flink internals and canopy the buffer debloating function. Within the second half, we deal with unaligned checkpoints.
Apache Flink is an open-source distributed engine for stateful processing over unbounded datasets (streams) and bounded datasets (batches). Amazon Managed Service for Apache Flink, previously generally known as Amazon Kinesis Information Analytics, is the AWS service providing absolutely managed Apache Flink.
Apache Flink is designed for stateful processing at scale, for top throughput and low latency. It scales horizontally, distributing processing and state throughout a number of nodes, and is designed to resist failures with out compromising the exactly-once consistency it gives.
Internally, Apache Flink makes use of intelligent mechanisms to take care of exactly-once state consistency, whereas additionally optimizing for throughput and diminished latency. The default conduct works properly for many use instances. Current variations launched two functionalities that may be optionally enabled to enhance software efficiency beneath specific situations: buffer debloating and unaligned checkpoints.
Buffer debloating and unaligned checkpoints could be enabled on Amazon Managed Service for Apache Flink model 1.15.
To grasp how these functionalities may also help and when to make use of them, we have to dive deep into among the elementary inside mechanisms of Apache Flink: checkpointing, in-flight information buffering, and backpressure.
Sustaining state consistency by way of failures with checkpointing
Apache Flink checkpointing periodically saves the interior software state for recovering in case of failure. Every of the distributed parts of an software asynchronously snapshots its state to an exterior persistent datastore. The problem is taking snapshots guaranteeing exactly-once consistency. A naïve “stop-the-world, take a snapshot” implementation would by no means meet the excessive throughput and low latency objectives Apache Flink has been designed for.
Let’s stroll by way of the method of checkpointing in a easy streaming software.
As proven within the following determine, Apache Flink distributes the work horizontally. Every operator (a node within the logical circulate of your software, together with sources and sinks) is cut up into a number of sub-tasks, primarily based on its parallelism. The appliance is coordinated by a job supervisor. Checkpoints are periodically initiated by the job supervisor, sending a sign to all supply operators’ sub-tasks.

On receiving the sign, every supply sub-task independently snapshots its state (for instance, the offsets of the Kafka subject it’s consuming) to a persistent storage, after which broadcasts a particular file referred to as checkpoint barrier (“CB” within the following diagrams) to all outgoing streams. Checkpoint obstacles work equally to watermarks in Apache Flink, flowing in-bands, together with regular data. A barrier doesn’t overtake regular data and isn’t overtaken.
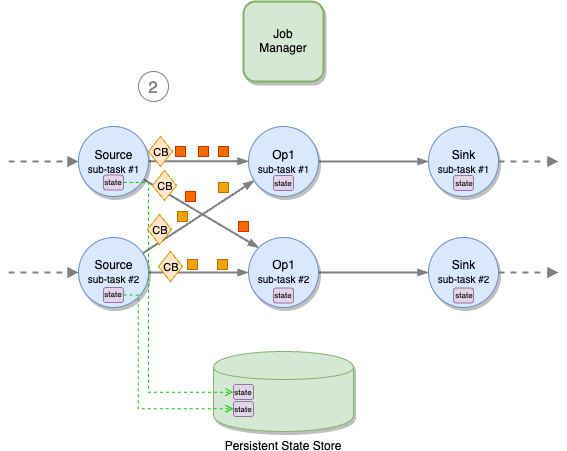
When a downstream operator’s sub-task receives all checkpoint obstacles from all enter channels, it begins snapshotting its state.
A sub-task doesn’t pause processing whereas saving its state to the distant, persistent state backend. It is a two-phase operation. First, the sub-task takes a snapshot of the state, on the native file system or in reminiscence, relying on software configuration. This operation is obstructing however very quick. When the snapshot is full, it restarts processing data, whereas the state is asynchronously saved to the exterior, persistent state retailer. When the state is efficiently saved to the state retailer, the sub-task acknowledges to the job supervisor that its checkpointing is full.
The time a sub-task spends on the synchronous and asynchronous elements of the checkpoint is measured by Sync Period and Async Period metrics, proven by the Apache Flink UI. It’s then asynchronously despatched to the backend. After the quick snapshot, the sub-task restarts processing messages. The backend notifies the sub-task when the state has been efficiently saved. The sub-task, in flip, sends an acknowledgment to the job supervisor that checkpointing is full.

Checkpoint obstacles propagate by way of all operators, right down to the sinks. When all sink sub-tasks have acknowledged the checkpoint to the job supervisor, the checkpoint is said full and can be utilized to get better the applying, for instance in case of failure.
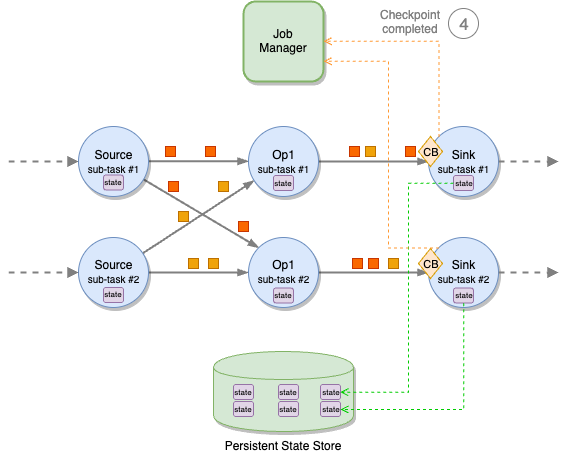
Checkpoint barrier alignment
A sub-task might obtain completely different partitions of the identical stream from completely different upstream sub-tasks, for instance when a stream is repartitioned with a keyBy or a rebalance. Every upstream sub-task will emit a checkpoint barrier independently. To take care of exactly-once consistency, the sub-task should watch for the obstacles to reach on all enter partitions earlier than taking a snapshot of its state.
This part known as checkpoint alignment. In the course of the alignment, the sub-task stops processing data from the partitions it already acquired the barrier from and continues processing the partitions which are behind the barrier.
After the obstacles from all upstream partitions have arrived, the sub-task takes the snapshot of its state after which broadcasts the barrier downstream.
The time spent by a sub-task whereas aligning obstacles is measured by the Checkpoint Alignment Period metric, proven by the Apache Flink UI.

In-flight information buffering
To optimize for throughput, Apache Flink tries to maintain every sub-task all the time busy. That is achieved by transmitting data over the community in blocks and by buffering in-flight information. Be aware that that is information transmission optimization; Flink operators all the time course of data one on the time.
Information is handed over between sub-tasks in items referred to as community buffers. A community buffer has a set measurement, in bytes.
Sub-tasks additionally buffer in-flight enter and output information. These buffers are referred to as community buffer queues. Every queue consists of a number of community buffers. Every sub-task has an enter community buffer queue for every upstream sub-task and an output community buffer queue for every downstream sub-task.
Every file emitted by the sub-task is serialized, put into community buffers, and printed to the output community buffer queue. To make use of all of the obtainable area, a number of messages could be packed right into a single community buffer or cut up throughout subsequent community buffers.
A separate thread sends full community buffers over the community, the place they’re saved within the vacation spot sub-task’s enter community buffer queue.
When the vacation spot sub-task thread is free, it deserializes the community buffers, rebuilds the data, and processes them one by one.

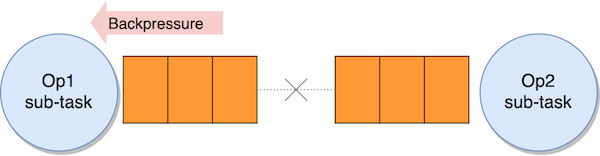
Backpressure
If a sub-task can’t sustain with processing data on the similar tempo they’re acquired, the enter queue fills up. When the enter queue is full, the upstream sub-task stops sending information.
Information accumulates within the sender’s output queue. When that is additionally full, the sender sub-task stops processing data, accumulating acquired information in its personal enter queue, and the consequences propagates upstream.
That is the backpressure that Apache Flink makes use of to regulate the interior circulate, stopping sluggish operators from being overwhelmed by slowing down the upstream circulate. Backpressure is a security mechanism to maximise the applying throughput. It may be momentary, in case of an sudden peak of ingested information, for instance. If not momentary, it’s normally the symptom—not the trigger—that the applying will not be designed appropriately or it has inadequate assets to course of the workload.
In-flight buffering and checkpoint obstacles
As checkpoint obstacles circulate with regular data, in addition they circulate within the community buffers, by way of the enter and output queues. In regular situations, obstacles don’t overtake data, and they’re by no means overtaken. If data are queueing up because of backpressure, checkpoint obstacles are additionally caught within the queue, taking longer time to propagate from the sources to the sinks, delaying the completion of the checkpoint.
Within the second half of this sequence, we’ll see how unaligned checkpoints can let obstacles overtake data beneath particular situations. For now, let’s see how we will optimize the scale of enter and output queues with buffer debloating.
Buffer debloating to optimize in-flight information
The default community buffer queue measurement is an efficient compromise for many purposes. You’ll be able to modify this measurement, however it applies to all sub-tasks, and it might be tough to optimize this one-size-fits-all throughout completely different operators.
Longer queues help greater all through, however they could decelerate checkpoint obstacles that should undergo longer queues, inflicting longer Finish to Finish Checkpoint Period. Ideally, the quantity of in-flight information ought to be adjusted primarily based on the precise throughput.
In model 1.14, Apache Flink launched buffer debloating, which could be enabled to regulate in-flight information of every sub-task, primarily based on the present throughput the sub-task is processing, and periodically reassess and readjust it.
How buffer debloating helps your software
Take into account a streaming software, ingesting data from a streaming supply and publishing the outcomes to a streaming vacation spot after some transformations. Below regular situations, the applying is sized to course of the incoming throughput easily. Our vacation spot has restricted capability, for instance a Kafka subject throttled by way of quotas, enough to deal with the conventional throughput, with some margin.

Think about that the ingestion throughput has occasional peaks. These peaks exceed the boundaries of the streaming vacation spot (throughput quota of the Kafka subject), which begins throttling.

As a result of the sink can’t course of the total throughput, in-flight information accumulates upstream of the sink, inflicting backpressure on the upstream operator. The impact ultimately propagates as much as the supply, and the supply begins lagging behind the newest file within the supply stream.

As lengthy this can be a momentary situation, backpressure and lagging should not an issue per se, so long as the applying is ready to catch up when the height has completed.
Sadly, accumulating in-flight information additionally slows down the propagation of the checkpoint obstacles. Checkpoint Finish to Finish Period goes up, and checkpoints might ultimately day out.

The scenario is even worse if the sink makes use of two-phase commit for exactly-once ensures. For instance, KafkaSink makes use of Kafka transactions dedicated on checkpoints. If checkpoints grow to be too sluggish, transactions are dedicated later, considerably growing the latency of any downstream client utilizing a read-committed isolation stage.
Sluggish checkpoints beneath backpressure might also trigger a vicious cycle. A slowed-down software ultimately crashes, and recovers from the final checkpoint that’s fairly previous. This causes a protracted reprocessing that, in flip, induces extra backpressure and even slower checkpoints.
On this case, buffer debloating may also help by adjusting the quantity of in-flight information primarily based on the throughput every sub-task is definitely processing. When a sub-task is throttled by backpressure, the quantity of in-flight information is diminished, additionally decreasing the time checkpoint obstacles take to undergo all operators. Checkpoint Finish to Finish Period goes down, and checkpoints don’t day out.
Buffer debloating internals
Buffer debloating estimates the throughput a sub-task is able to processing, assuming no idling, and limits the upstream in-flight information buffers to comprise simply sufficient information to be processed in 1 second (by default).
For effectivity, community buffers within the queues are mounted. Buffer debloating caps the usable measurement of every community buffer, making it smaller when the sub-task is processing slowly.

The advantages of much less in-flight information depends upon whether or not Apache Flink is utilizing normal checkpoint alignment, the default conduct described to this point, or unaligned checkpoints. We’ll study unaligned checkpoints within the second half of this sequence, however let’s see the impact of buffer debloating, briefly.
- With aligned checkpoints (default conduct) – Much less in-flight information makes checkpoint barrier propagation quicker, in the end decreasing the end-to-end checkpoint period but additionally making it extra predictable
- With unaligned checkpoints (non-obligatory) – Much less in-flight information reduces the quantity of in-flight data saved with the checkpoint, in the end decreasing the checkpoint measurement
What buffer debloating doesn’t do
Be aware that the issue we are attempting to resolve is sluggish checkpointing (or extreme checkpointing measurement, with unaligned checkpoints). Buffer debloating helps making checkpointing quicker.
Buffer debloating doesn’t take away backpressure. Backpressure is the interior protecting mechanism that Apache Flink makes use of when some a part of the applying will not be in a position to deal with the incoming throughput. To cut back backpressure, it’s important to work on different features of the applying. When backpressure is simply momentary, for instance beneath peak situations, the one manner of eradicating it will be sizing the end-to-end system for the height, somewhat than regular workload. However this may very well be unattainable or too costly.
Buffer debloating helps cut back and maintain checkpoint period secure beneath distinctive and momentary situations. If an software experiences backpressure beneath its regular workload, or checkpoints are too sluggish beneath regular situations, it is best to examine the implementation of your software to grasp the foundation trigger.
When the automated throughput prediction fails
Buffer debloating doesn’t have any specific downside, however in nook instances, the mechanism might incorrectly estimate the throughput, and the ensuing quantity of in-flight information is probably not optimum.
Estimating the throughput is complicated when an operator receives information from a number of upstream operators, linked streams or unions, with very completely different throughput. It could additionally take time to regulate to a sudden spike, inflicting a short lived suboptimal buffering.
- Too small in-flight information might cut back the throughput the sub-task can course of (will probably be idling), inflicting extra backpressure upstream
- Too massive buffers might decelerate checkpointing and enhance the checkpoint measurement (with unaligned checkpoints)
Conclusion
The checkpointing mechanism makes Apache Flink fault tolerant, offering exactly-once state consistency. In-flight information buffering and backpressure management the info circulate throughout the distributed streaming software maximize the throughput. Apache Flink default behaviors and configurations are good for many workloads.
The effectiveness of buffer debloating depends upon the traits of the workload and the applying. The final suggestion is to check the performance in a non-production setting with a sensible workload to confirm it really helps together with your use case.
You’ll be able to request to allow buffer debloating in your Amazon Managed Service for Apache Flink software.
Below specific situations, the mixed impact of backpressure and in-flight information buffering might decelerate checkpointing, enhance checkpointing measurement (with unaligned checkpoints), and even trigger checkpoints to fail. In these instances, enabling unaligned checkpointing might assist cut back checkpoint period or measurement.
Within the second half of this sequence, we’ll perceive higher unaligned checkpoints and the way they may also help your software checkpointing effectively in presence of backpressure, particularly together with buffer debloating.
In regards to the Authors
 Lorenzo Nicora works as Senior Streaming Answer Architect at AWS, serving to prospects throughout EMEA. He has been constructing cloud-native, data-intensive techniques for over 25 years, working within the finance trade each by way of consultancies and for FinTech product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of initiatives, together with Apache Flink.
Lorenzo Nicora works as Senior Streaming Answer Architect at AWS, serving to prospects throughout EMEA. He has been constructing cloud-native, data-intensive techniques for over 25 years, working within the finance trade each by way of consultancies and for FinTech product corporations. He has leveraged open-source applied sciences extensively and contributed to a number of initiatives, together with Apache Flink.
 Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS prospects serving to them design real-time analytics architectures utilizing AWS providers, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.
Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS prospects serving to them design real-time analytics architectures utilizing AWS providers, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.