

{kind=link}
An assortment of file codecs
On the earth of recent information engineering, the Databricks Lakehouse Platform simplifies the method of constructing dependable streaming and batch information pipelines. Nevertheless, dealing with obscure or much less frequent file codecs nonetheless poses challenges for ingesting information into the Lakehouse. Upstream groups answerable for offering information make selections on tips on how to retailer and transmit it, leading to variations in requirements throughout organizations. As an example, information engineers should generally work with CSVs the place schemas are open to interpretation, or recordsdata the place the filenames lack extensions, or the place proprietary codecs require customized readers. Generally, merely requesting “Can I get this information in Parquet as an alternative?” solves the issue, whereas different occasions a extra inventive method is critical to assemble a performant pipeline.
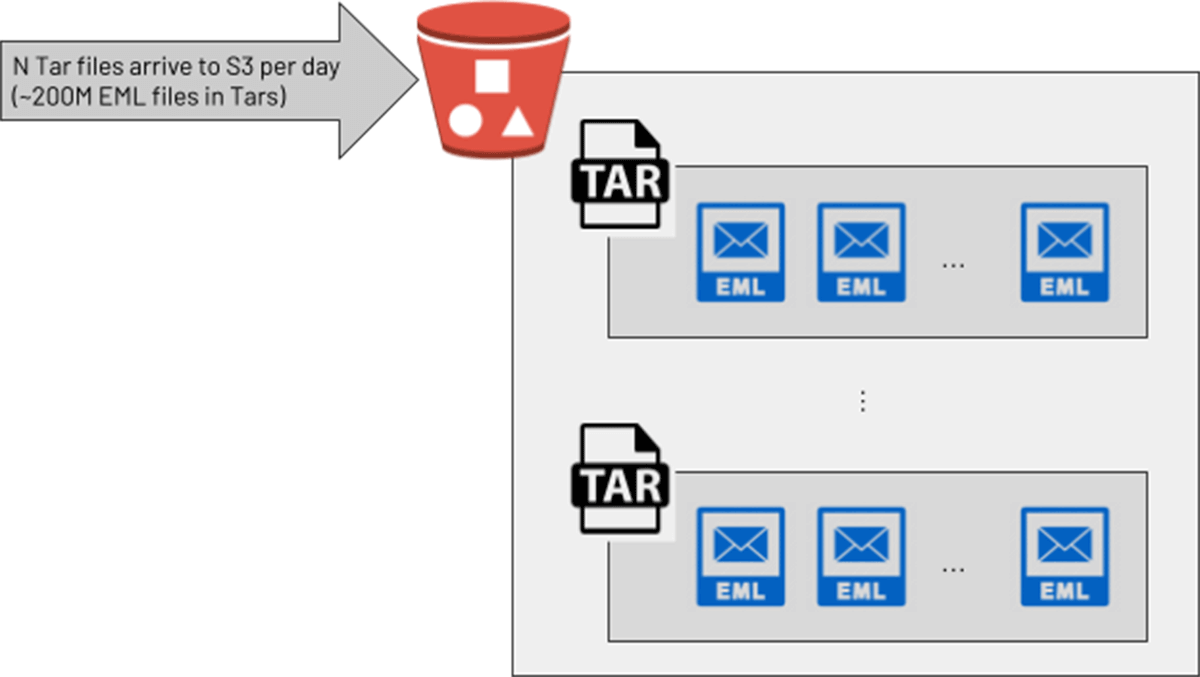
One information engineering workforce at a big buyer wished to course of the uncooked textual content of emails for cyber safety use circumstances on Databricks. An upstream workforce supplied these in zipped/compressed Tar recordsdata, the place every Tar contained many e mail (.eml) recordsdata. Within the buyer’s improvement setting, engineers devised an appropriate resolution: a PySpark UDF invoked the Python “tarfile” library to transform every Tar into an array of strings, then used the native PySpark explode() perform to return a brand new row for every e mail within the array. This appeared to be an answer in a testing setting, however once they moved to manufacturing with a lot bigger Tar recordsdata (as much as 300Mb of e mail recordsdata earlier than Tarring), the pipeline began inflicting cluster crashes on account of out-of-memory errors. With a manufacturing goal of processing 200 million emails per day, a extra scalable resolution was required.
MapInPandas() to deal with any file format
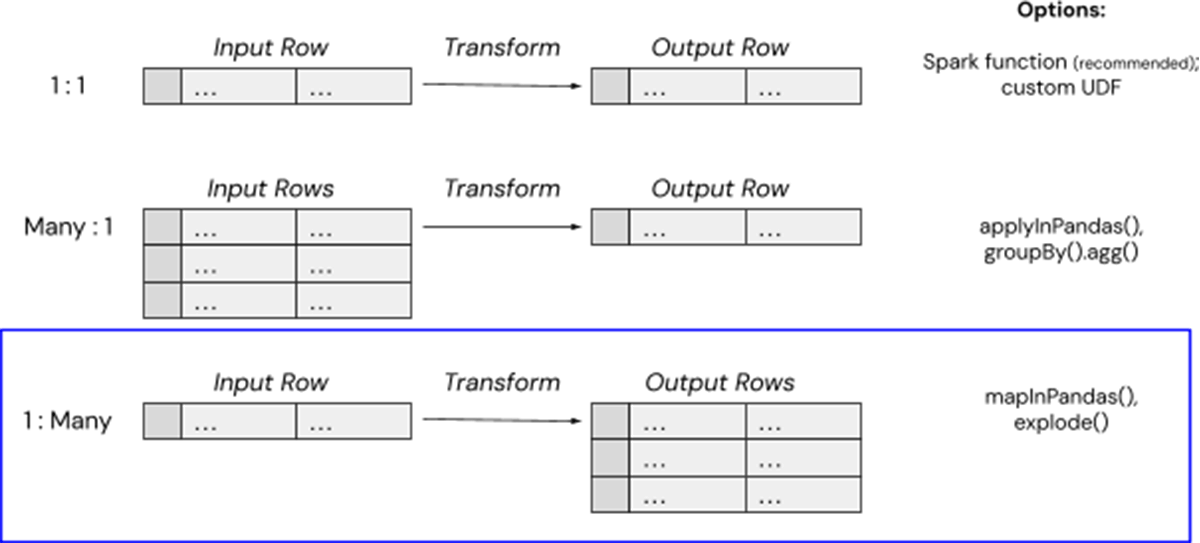
There are just a few easy strategies for dealing with advanced information transformations in Databricks, and on this case, we will use mapInPandas() to map a single enter row (e.g. a cloud storage path of a big Tar file) to a number of output rows (e.g. the contents of particular person .eml textual content recordsdata). Launched in Spark 3.0.0., mapInPandas() lets you effectively full arbitrary actions on every row of a Spark DataFrame with a Python-native perform and yield a couple of return row. That is precisely what this high-tech buyer wanted to “unpack” their compressed recordsdata into a number of usable rows containing the contents of every e mail, whereas avoiding the reminiscence overhead from Spark UDFs.
mapInPandas() for File Unpacking
Now that we’ve got the fundamentals, let’s have a look at how this buyer utilized this to their situation. The diagram under serves as a conceptual mannequin of the architectural steps concerned:
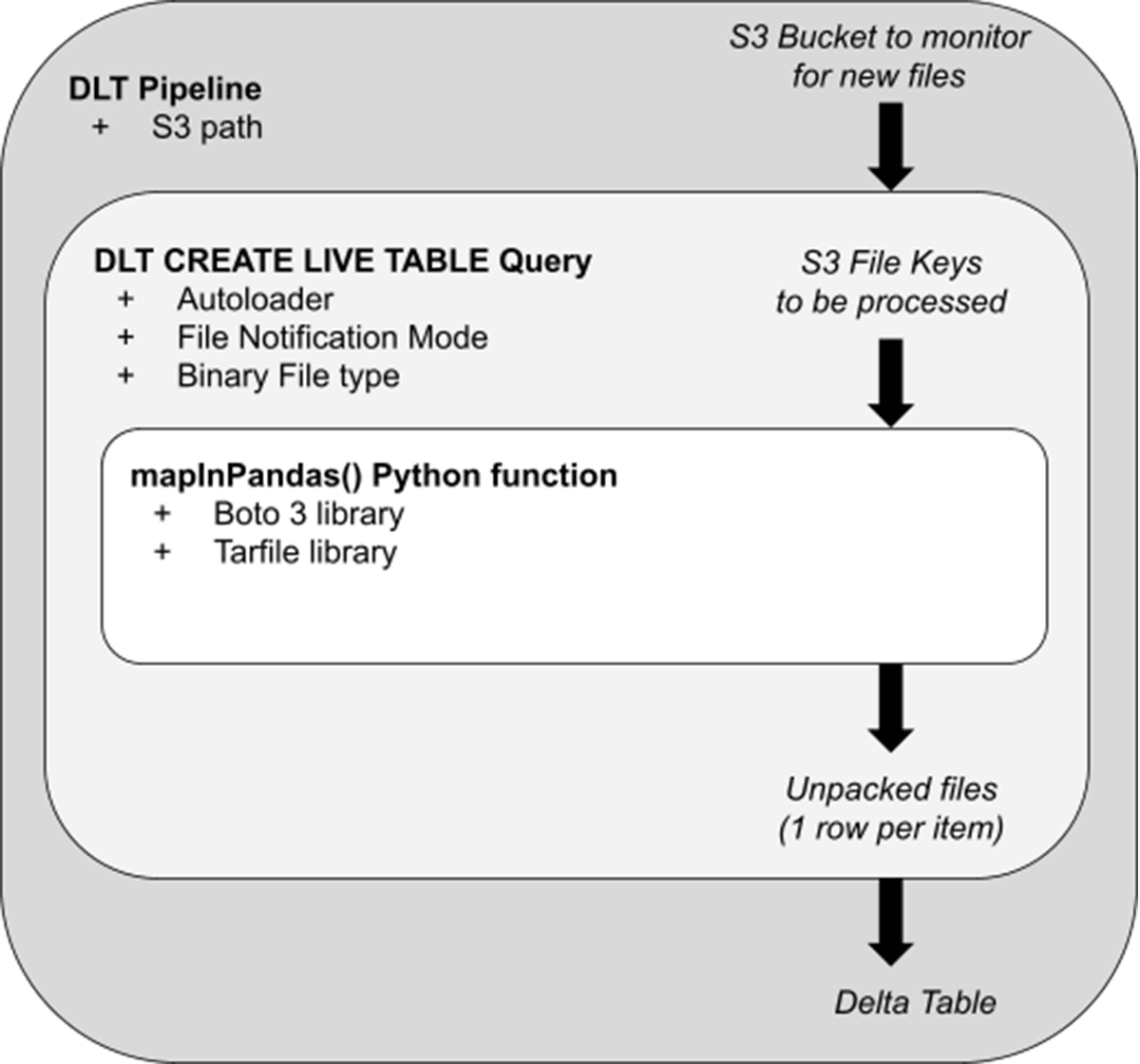
- A Delta Stay Tables (DLT) Pipeline serves because the orchestration layer for our unpacking and different logic. When in Manufacturing mode, this streaming pipeline will choose up and unpack new Tar recordsdata as they arrive on S3. In preliminary testing on a non-Photon pipeline, with default DLT cluster settings, Tar recordsdata as much as 430Mb have been shortly processed (<30 seconds per batch) with out placing reminiscence strain on the cluster. With enhanced autoscaling, the DLT cluster will scale up and right down to match the incoming file quantity, as every employee is executing the unpacking in parallel.
- Throughout the pipeline, a “CREATE STREAMING TABLE” question specifies the S3 path from which the pipeline ingests. With File Notification mode, the pipeline will effectively obtain an inventory of latest Tar recordsdata as they arrive, and cross these file “keys” to be unpacked by the innermost logic.
- Handed to the mapInPandas() perform is an inventory of recordsdata to course of within the type of an iterator of pandas DataFrames. Utilizing the usual Boto3 library and a tar-specific Python processing library (Tarfile), we’ll unpack every file and yield one return row for each uncooked e mail.
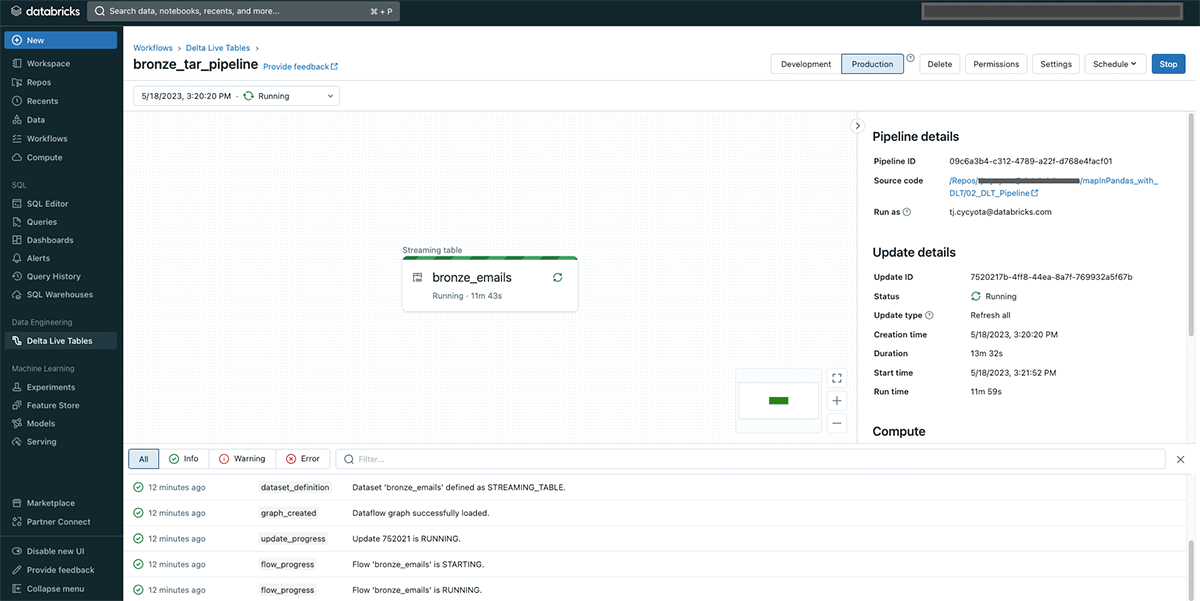
The top result’s a analysis-ready Delta desk that’s queryable from Databricks SQL or a pocket book that incorporates our e mail information, and the email_id column to uniquely determine every unpacked e mail:
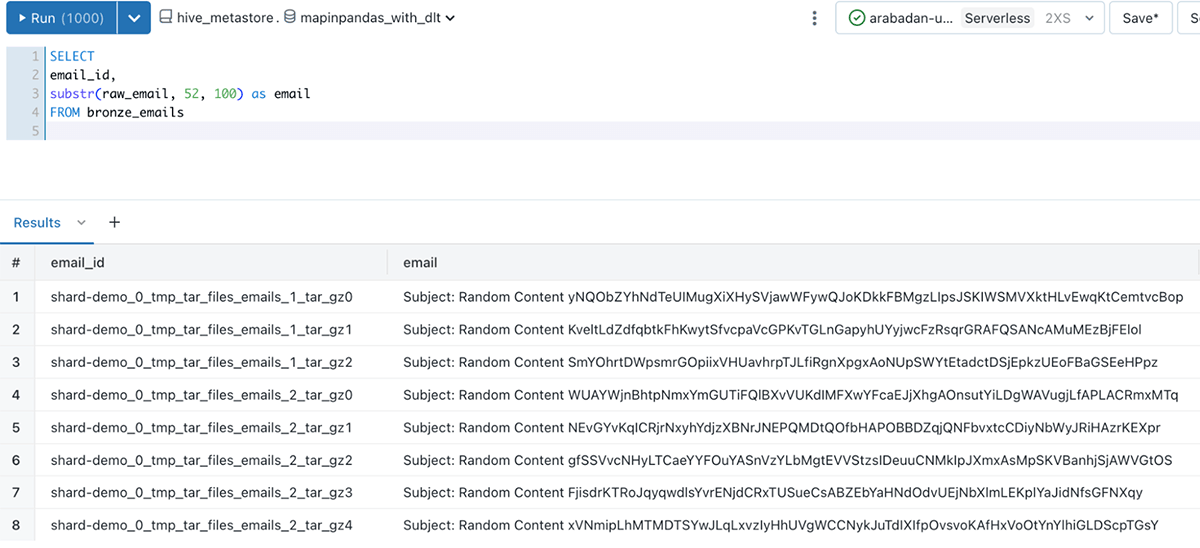
The notebooks showcasing this resolution include the total mapInPandas() logic, in addition to pipeline configuration settings. See them right here.
Additional Functions
With the method described right here, we’ve got a scalable resolution to course of Tar e mail recordsdata at low latency for necessary enterprise functions. Delta Stay Tables might be shortly adjusted to match file arrival volumes, as we will change a pipeline from steady to triggered with none modifications to the underlying code. Whereas this instance centered on the “bronze” layer of ingesting uncooked recordsdata from S3, this pipeline might be simply prolonged with cleaning, enrichment, and aggregation steps to make this useful information supply accessible to enterprise customers and machine studying functions.
Extra typically although, this mapInPandas() method works nicely for any file-processing duties which might be in any other case difficult with Spark:
- Ingesting recordsdata with out a codec/format supported in Spark
- Processing recordsdata with out a filetype within the filename: if
file123is definitely a file of kind “tar”, however was saved with out a .tar.gz file extension - Processing recordsdata with proprietary or area of interest extensions, such because the Zstandard compression algorithm: merely change the innermost loop of the MapInPandas perform with the Python library wanted to emit rows.
- Breaking down massive, monolithic, or inefficiently saved recordsdata into DataFrame rows with out working out of reminiscence.
Discover extra examples of Delta Stay Tables notebooks right here, or see how clients are utilizing DLT in manufacturing right here.