
.png)
.png&description=Saying+Delta+Lake+3.0+with+New+Common+Format+and+Liquid+Clustering){kind=link}
We’re excited to announce Delta Lake 3.0, the subsequent main launch of the Linux Basis open supply Delta Lake Undertaking, accessible in preview now. We prolong our honest appreciation to the Delta Lake group for his or her invaluable contributions to this launch. Delta Lake 3.0 introduces the next highly effective options:
- Delta Common Format (UniForm) allows studying Delta within the format wanted by the applying, enhancing compatibility and increasing the ecosystem. Delta will routinely generate metadata wanted for Apache Iceberg or Apache Hudi, so customers don’t have to decide on or do guide conversions between codecs. With UniForm, Delta is the common format that works throughout ecosystems.
- Delta Kernel simplifies constructing Delta connectors by offering easy, slim programmatic APIs that cover all of the complicated particulars of the Delta protocol specification.
- Liquid Clustering (coming quickly) simplifies getting the perfect question efficiency with cost-efficient clustering as the info grows.
On this weblog, we’re going to dive into the main points of the Delta Lake 3.0 capabilities, by way of the lens of buyer challenges that they clear up.
Problem #1: I like the thought of a knowledge lakehouse however which storage format ought to I select?
Firms are occupied with combining their information warehouses and information lakes into an open information lakehouse. This transfer avoids locking information into proprietary codecs, and it allows utilizing the best instrument for the best job in opposition to a single copy of information. Nevertheless, they wrestle with the choice of whether or not to standardize on a single open lakehouse format and which one to make use of. They might have a variety of current information warehouses and information lakes being utilized by completely different groups, every with its personal most well-liked information connectors. Clients are involved that selecting a single storage format will result in its personal type of lock-in, and so they fear about going by way of one-way doorways. Migration is dear and tough, in order that they need to make the best determination up entrance and solely need to do it as soon as. They in the end need the perfect efficiency on the most cost-effective value for all of their information workloads together with ETL, BI, and AI, and the flexibleness to eat that information anyplace.
Resolution: Delta UniForm routinely and immediately interprets Delta Lake to Iceberg and Hudi.
Delta Common Format (UniForm) routinely unifies desk codecs, with out creating extra copies of information or extra information silos. Groups that use question engines designed to work with Iceberg or Hudi information will be capable to learn Delta tables seamlessly, with out having to repeat information over or convert it. Clients don’t have to decide on a single format, as a result of tables written by Delta will likely be universally accessible by Iceberg and Hudi readers.
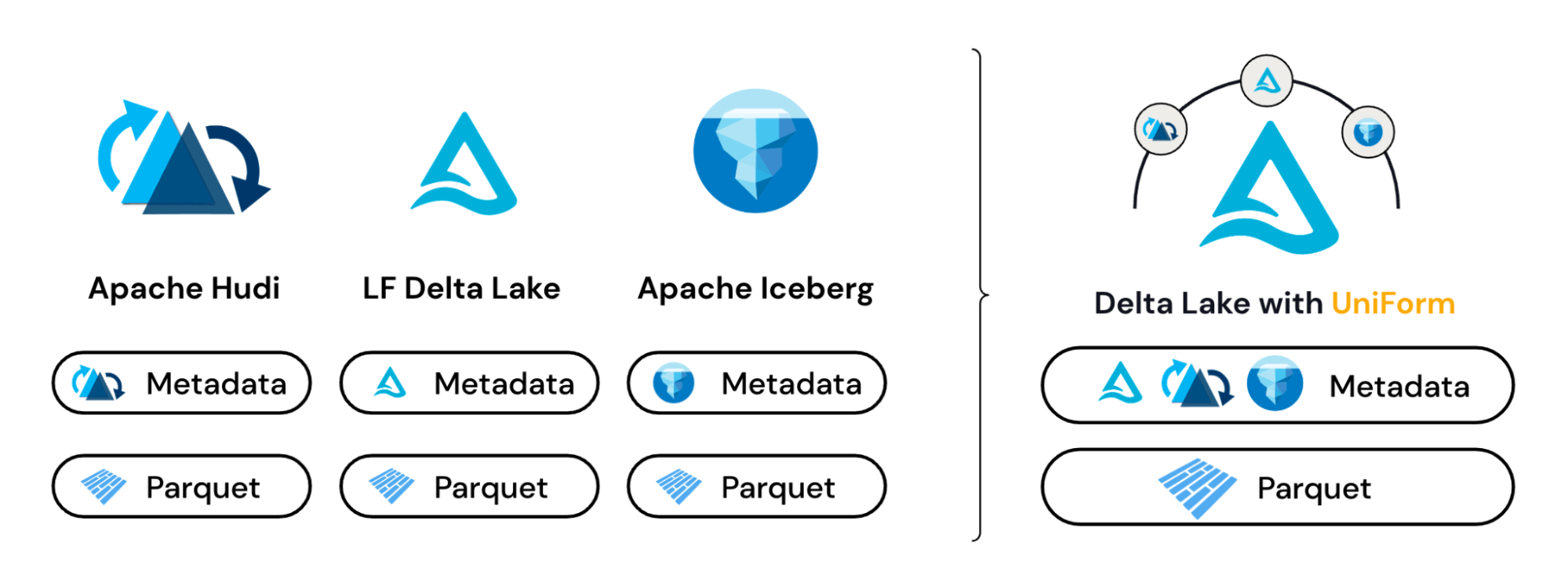
UniForm takes benefit of the truth that all three open lakehouse codecs are skinny layers of metadata atop Parquet information recordsdata. As writes are made, UniForm will incrementally generate this layer of metadata to spec for Hudi, Iceberg and Delta.
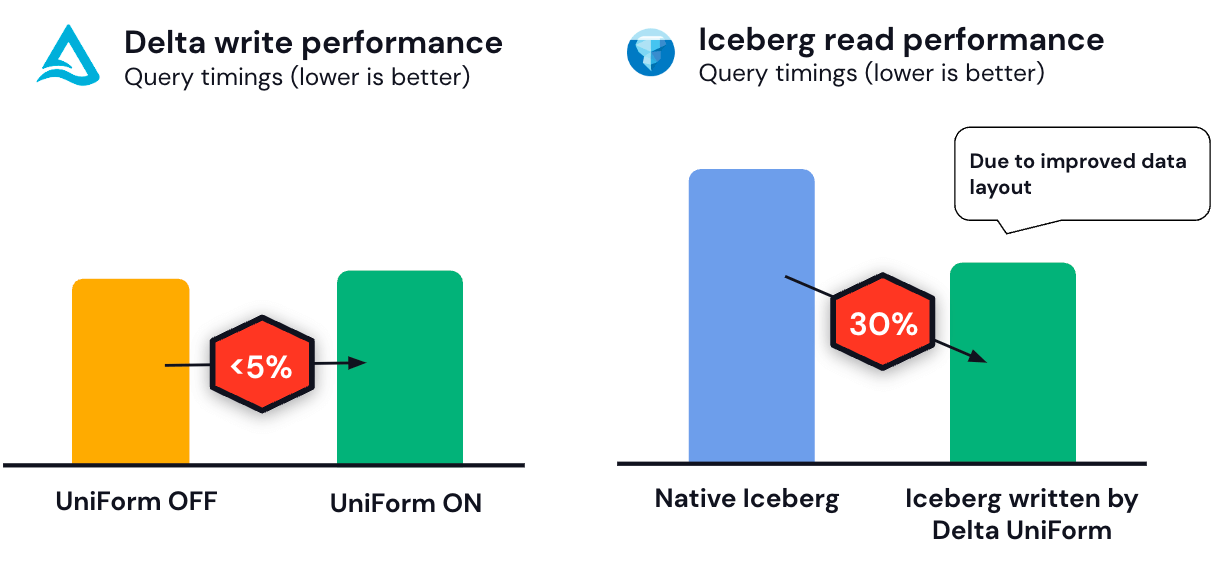
In benchmarking, we’ve seen that UniForm introduces negligible efficiency and useful resource overhead. We additionally noticed improved learn efficiency on UniForm-enabled tables relative to native Iceberg tables, because of Delta’s improved information format capabilities like Z-order.
With UniForm, prospects can select Delta with confidence, understanding that by selecting Delta, they’ll have broad assist from any instrument that helps lakehouse codecs.
“Collaboration and innovation within the monetary companies business are fueled by the open supply group and tasks like Legend, Goldman Sachs’ open supply information platform that we preserve in partnership with FINOS,” stated Neema Raphael, Chief Knowledge Officer and Head of Knowledge Engineering at Goldman Sachs. “We’ve lengthy believed within the significance of open supply to know-how’s future and are thrilled to see Databricks proceed to put money into Delta Lake. Organizations shouldn’t be restricted by their selection of an open desk format and Common Format assist in Delta Lake will proceed to maneuver your complete group ahead.”
Problem #2: Determining the best partitioning keys for optimum efficiency is a Goldilocks Drawback
When constructing a knowledge lakehouse, it’s onerous to provide you with a one-size-fits-all partitioning technique that not solely suits the present information question patterns but additionally adapts to the brand new workloads over time. Due to the mounted information format, choosing the proper partitioning technique means groups need to put plenty of cautious thought and planning upfront into the partitioning technique. And regardless of greatest efforts, with time, question patterns change, and the preliminary partitioning technique turns into inefficient and costly. Options equivalent to Partition Evolution are considerably helpful in making Hive-style partitioning extra versatile nevertheless it requires desk house owners to repeatedly monitor their tables and “evolve” the partitioning columns. All of those steps add engineering work and should not straightforward to do for a big phase of customers who simply need to get insights from their information. And regardless of greatest efforts, the distribution of information throughout partitions can grow to be uneven over time straight impacting learn/write efficiency.
Resolution: Liquid’s versatile information format approach can self-tune to suit your information now and because it grows.
Liquid Clustering is a great information administration approach for Delta tables. It’s versatile and routinely adjusts the info format primarily based on clustering keys. Liquid Clustering dynamically clusters information primarily based on information patterns, which helps to keep away from the over- or under-partitioning issues that may happen with Hive partitioning.
- Liquid is straightforward: You set Liquid clustering keys on the columns which are most frequently queried – no extra worrying about conventional concerns like column cardinality, partition ordering, or creating synthetic columns that act as good partitioning keys.
- Liquid is environment friendly: It incrementally clusters new information, so that you needn’t commerce off between enhancing efficiency with lowering price/write amplification.
- Liquid is versatile: You’ll be able to rapidly change which columns are clustered by Liquid with out rewriting current information.
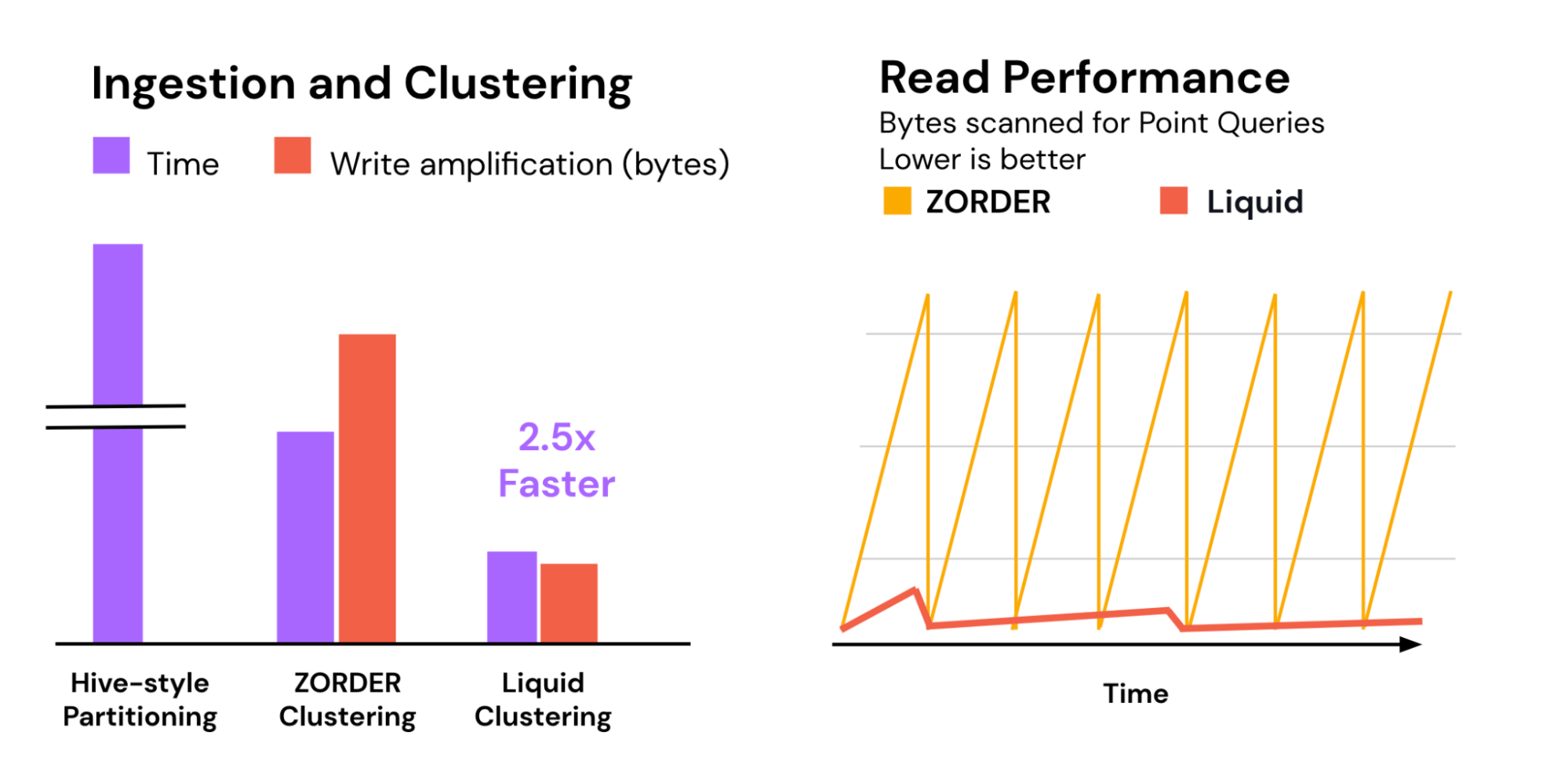
To check the efficiency of Liquid, we ran a benchmark of a typical 1 TB information warehouse workload. Liquid Clustering resulted in 2.5x quicker clustering relative to Z-order. In the identical trial, conventional Hive-style partitioning was an order of magnitude slower as a result of costly shuffle required for writing out many partitions. Liquid additionally incrementally clusters new information as it’s ingested, paving the best way for constantly quick learn efficiency.
Problem #3: Deciding which connector to prioritize is difficult for integrators.
The connector ecosystem for Delta is giant and rising to satisfy the fast adoption of the format. As engine integrators and builders construct connectors for open supply storage codecs, they’ve a call to make about which format to prioritize first. They need to stability the upkeep time and prices in opposition to engineering assets as a result of each new protocol specification requires new code.
Resolution: Kernel unifies the connector ecosystem.
Delta Kernel is a brand new initiative that can present simplified, slim and steady programmatic APIs that cover all of the complicated Delta protocol particulars. With Kernel, connector builders could have entry to all new Delta options by updating the Kernel model itself, not a single line of code. For finish customers, this implies quicker entry to the most recent Delta improvements throughout the ecosystem.
Along with UniForm, Kernel additional unifies the connector ecosystem, as a result of Delta will write out metadata for Iceberg and Hudi routinely. For engine integrators, which means if you construct as soon as for Delta, you construct for everybody.
The preview launch candidate for Delta Lake 3.0 is obtainable in the present day. Databricks prospects may preview these options in Delta Lake with DBR model 13.2 or the subsequent preview channel of DBSQL coming quickly.
Concerned with taking part within the open supply Delta Lake group?
Go to Delta Lake to study extra; you may be part of the Delta Lake group through Slack and Google Group. In case you’re occupied with contributing to the venture, see the record of open points right here.
An enormous thanks to the next contributors for making this launch accessible to the group:
Ahir Reddy, Ala Luszczak, Alex, Allen Reese, Allison Portis, Antoine Amend, Bart Samwel, Boyang Jerry Peng, CabbageCollector, Carmen Kwan, Christos Stavrakakis, Denny Lee, Desmond Cheong, Eric Ogren, Felipe Pessoto, Fred Liu, Fredrik Klauss, Gerhard Brueckl, Gopi Krishna Madabhushi, Grzegorz Kołakowski, Herivelton Andreassa, Jackie Zhang, Jiaheng Tang, Johan Lasperas, Junyong Lee, Ok.I. (Dennis) Jung, Kam Cheung Ting, Krzysztof Chmielewski, Lars Kroll, Lin Ma, Luca Menichetti, Lukas Rupprecht, Ming DAI, Mohamed Zait, Ole Sasse, Olivier Nouguier, Pablo Flores, Paddy Xu, Patrick Pichler, Paweł Kubit, Prakhar Jain, Ryan Johnson, Sabir Akhadov, Satya Valluri, Scott Sandre, Shixiong Zhu, Siying Dong, Son, Tathagata Das, Terry Kim, Tom van Bussel, Venki Korukanti, Wenchen Fan, Yann Byron, Yaohua Zhao, Yuhong Chen, Yuming Wang, Yuya Ebihara, aokolnychyi, gurunath, jintao shen, maryannxue, noelo, panbingkun, windpiger, wwang-talend