
{kind=link}

(Blue Planet Studio/Shutterstock)
A humorous factor occurred whereas the tech world was targeted nearly solely on ChatGPT over the previous eight months: Adoption of different cutting-edge applied sciences stored rising. A type of is real-time stream information processing, curiosity through which has been quietly constructing over the previous couple of years for a number of high-impact use circumstances.
IDC says the stream processing market is anticipated to develop at a compound annual progress charge (CAGR) of 21.5% from 2022 to 2028. “This progress is being pushed by the growing quantity and velocity of knowledge, the necessity for real-time analytics, and the rise of the Web of Issues (IoT),” the analyst group says.
Over at Databricks, 54% of its prospects are utilizing Spark Structured Streaming, in accordance with Databricks CEO Ali Ghodsi.
“Lots of people are enthusiastic about generative AI, however they’re not taking note of how a lot consideration streaming functions truly now have,” Ghodsi mentioned throughout his keynote two weeks on the Knowledge + AI Summit. “It’s truly 177% progress previously 12 months for those who have a look at the variety of streaming jobs.”
The previous yr has seen numerous enhancements in Spark Structured Streaming because of Venture Lightspeed, which Databricks launched a yr in the past. The undertaking is growing processing instances and dropping latency, Ghodsi mentioned.
Firms like Columbia, AT&T, Walgreens, Honeywell, and Edmunds are utilizing Spark Structured Streaming in manufacturing, in accordance with a latest weblog submit on Venture Lightspeed. The corporate runs a mean of 10 million Structured Streaming Jobs per week on behalf of consumers, which it says is rising at 2.5x per yr. New enhancements as a part of the undertaking, similar to microbatch pipelining, will assist to enhance Structured Streaming.

Spark Structured Streaming utilization is rising quick, Databricks says
However Databricks isn’t the one vendor making progress with streaming information. Confluent continues to draw new customers and introduce new options to its hosted streaming information platform, dubbed Confluent Cloud, which is predicated on the Apache Kafka message bus.
Almost half (44%) of Confluent’s streaming information customers say the expertise is a prime strategic precedence, with 89% saying it’s vital, in accordance with Confluent’s 2023 Knowledge Streaming Report. What’s extra, the extra expertise prospects get with streaming information, the upper their return on funding, Confluent says within the report.
Along with the core Kafka message bus, Confluent sells stream processing techniques that trip on the bus. And with its acquisition of an Apache Flink startup known as Immerok late final yr, Confluent hopes to improve its revenues, which grew 38% final quarter.
Confluent and Databricks have a number of competitors from smaller distributors, nevertheless. A startup known as Redpanda not too long ago raised $100 million to assist it construct a brand new distributed messaging framework that’s absolutely suitable with Apache Kafka. Redpanda’s providing is written in C++, which has sure benefits over the Java codebase that Kafka runs on. (Kafka, for its half, is lastly shifting away from Zookeeper, the Java-based, Hadoop-era framework underlying its distributed structure).

The way forward for streaming is so shiny, you’ll want shades… (Lightspring/Shutterstock)
One other stream processing vendor to control is RisingWave Labs. The corporate, which builds a distributed SQL streaming database, not too long ago launched a totally managed model of its product. Dubbed RisingWave Cloud, the providing eliminates the necessity for the shopper to run and keep the underlying streaming information infrastructure, liberating them to concentrate on constructing real-time functions utilizing SQL.
You might also wish to control Nstream. Previously often called Swim (click on right here to learn our August 2022 profile), the corporate has constructed a stream processing product designed to take care of the state of occasions whereas concurrently dealing with huge occasion volumes, one thing that has bedeviled stateless approaches, similar to these employed by Kafka. Nstream developed its personal vertically built-in stack based mostly partly on the actor strategy (much like Akka) to attenuate latency for large-scale stateful processing.
Nstream was one of many distributors talked about in a latest Gartner report on the state of occasion stream processing platforms. The Market Information for Occasion Stream Processing (ESP) notes that real-time information sources are proliferating, each from inner sources like company web sites, sensors, machines, cellular gadgets and enterprise functions; in addition to from exterior sources, similar to social media platforms, information brokers and enterprise companions.
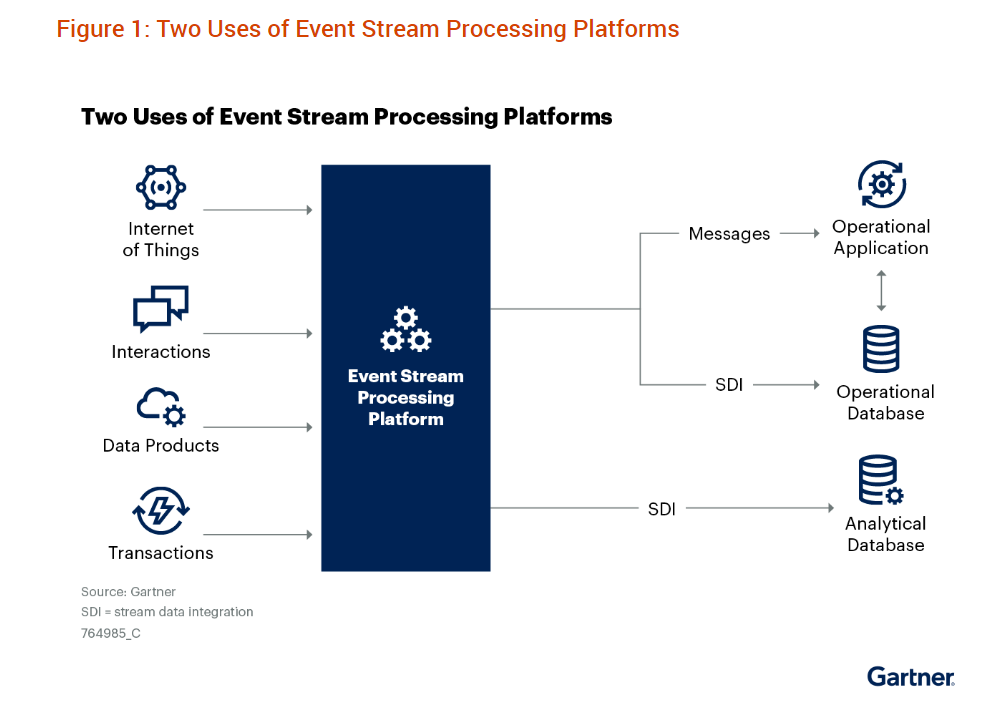
There are two sorts of ESP functions, Gartner says
“This data is most respected when it’s used as quickly because it arrives to enhance real-time or near-real-time enterprise selections,” Gartner analysts write. “ESP platforms are important parts in lots of new techniques that present steady intelligence, enhanced state of affairs consciousness, and sooner, more-precise enterprise selections.”
Gartner breaks the ESP market down into three classes, together with pure open supply, “open core” choices, and proprietary ESP techniques. Open-source choices making Gartner’s Market Information embody these from Apache Software program Basis, which develops the Kafka Streams, Flink, Spark Streaming, Storm, and Heron choices. Gartner says open supply choices are serving to to drive down the price of ESP deployments.
The open core class consists of vendor-backed merchandise based mostly on open supply code. Gartner lists a number of in its report, together with (however not restricted to):
- Aiven, which develops a stream processing service atop Apache Flink;
- Axual, which hosts an Apache Kafka-based real-time system;
- Cogility, which develops ESP atop Flink;
- Cloudera, which develops real-time techniques utilizing Apache Nifi and Flink;
- Gigaspaces, an in-memory information grid (IMDG) that has integrated Flink;
- GridGain Methods, the IMDG developer behind Apache Ignite;
- EsperTech, which develops an in-memory processing engine for real-time information that runs on Java and .NET;
- Instaclustr (owned by NetApp), which develops an ESP platform atop Kafka and Apache Cassandra;
- Lightbend, which develops the Akka framework;
- Google Cloud, which develops the Cloud Dataflow engine.
And within the proprietary class, Gartner has:
- Hazelcast, which develops an open supply, Java-based, in-memory information grid (IMDG) that can be utilized to construct ESP techniques;
- Hitachi, which develops the Hitachi Streaming Knowledge Platform;
- Oracle, which developed the GoldenGate Stream Analytics product;
- Microsoft Azure, which develops the Azure Stream Analytics and StreamInsight choices;
- SAP, which develops the Leonardo IoT and Edge Providers merchandise;
- SAS, which develops Occasion Stream Processing
- Software program AG, which develops Apama Streaming Analytics;
- TIBCO Software program, which develops Streaming and Cloud Integration.
Two-thirds of the ESP deployments Gartner sees assist real-time operational techniques. This consists of functions that require fast decision-making based mostly on recent information reflecting real-time occasions. The opposite third of ESP deployments are used to ingest, remodel, and retailer information for later analytics. In that respect, it’s principally a real-time model of conventional ETL and ELT processes.
Actual-time information typically arrives by way of the message bus, which is commonly Kafka (reportedly utilized by 80% of the Fortune 100), however information may additionally arrive by way of Apache Pulsar, RabbitMQ, Solace PubSub+, or TIBCO Software program Messaging, the analysts observe. The information is then routed to the ESP functions and frameworks, the place information is processed or routed to object shops, distributed file techniques, or databases for subsequent use.
Associated Gadgets:
To Enhance Knowledge Availability, Assume ‘Proper-Time’ Not ‘Actual-Time’
Actual-Time Analytics Databases Emerge to Take On Huge, Quick-Transferring Knowledge
Confluent to Develop Apache Flink Providing with Acquisition of Immerok
Aiven, AWS, Axual, Cloudera, Cogility, Confluent, Databricks, EsperTech, Gigaspaces, Google Cloud, Hazelcast, Hitachi, Instaclustr, Lightbend, NetApp, Nstream, Oracle, RisingWave Labs, SAP, SAS, Software program AG, TIBCO