

{kind=link}

(Maksim-Kabakou/Shutterstock)
Apache Iceberg seems to have the within observe to change into the defacto commonplace for large knowledge desk codecs at this level. And with at present’s $26 million spherical, the corporate behind the open supply venture, Tabular, is best positioned to proceed growing an automatic Iceberg knowledge administration service that may make a messy knowledge lake perform like a refined–and open–knowledge warehouse.
The arrival of open desk codecs is without doubt one of the largest issues to occur to knowledge lakes in fairly some time. As a substitute of placing the onus on builders or engineers to handle Parquet information in energetic knowledge lakes to make sure knowledge integrity, desk codecs like Iceberg and the opposite two competing codecs, Hudi from Uber and Delta from Databricks, present the ACID ensures that give clients confidence within the accuracy of the information.
Whereas an Iceberg atmosphere by itself delivers these advantages, it brings its personal set of necessities that will usually fall to the information engineer. Ryan Blue, who co-created Iceberg with Dan Weeks whereas at Netflix, co-founded Tabular in 2021 with Weeks and one other former Netflix colleague, Jason Reid, to automate these duties in an Iceberg atmosphere.
“Tabular is a wider platform” than simply Iceberg, Blue tells Datanami. “We offer a catalog, role-based entry controls, and background providers to maintain knowledge performant and clear. We are able to do issues like age-off knowledge or masks it after a sure time frame. We’ll go null out a column that may not be saved, and do kind of these fundamental heavy lifting duties that you simply don’t wish to spend on an information engineer’s time.”
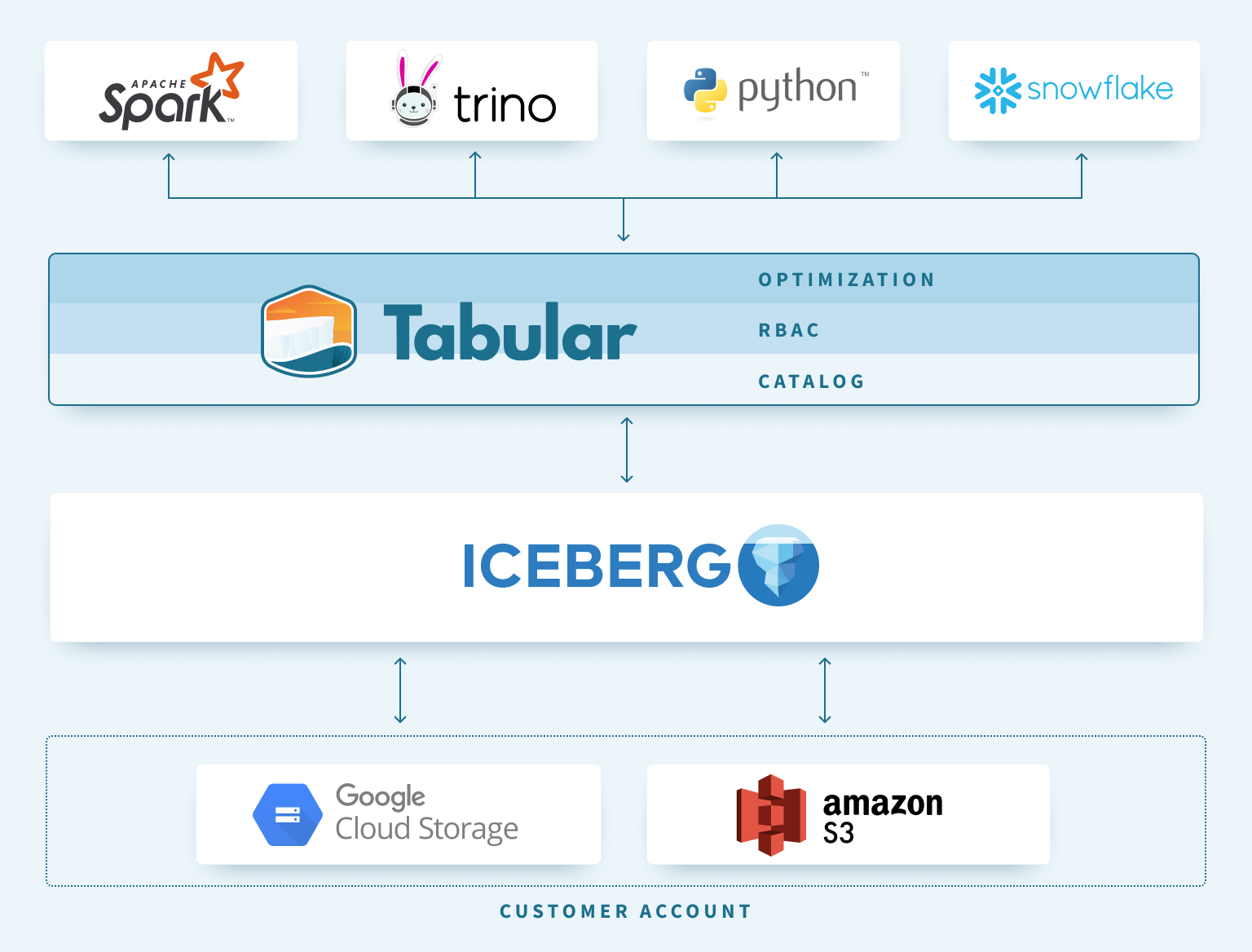
When mixed with object storage, Tabular and Iceberg perform as the underside half of an information warehouse (Picture supply: Tabular)
Tabular’s automated compaction service can shrink the S3 knowledge storage by 50%, and typically extra. As a substitute of requiring a human engineer to rewrite a complete bunch of small Parquet information which were dropped onto S3 (the one object storage Tabular helps proper now), the Tabular service will robotically compact all these small information right into a fewer variety of bigger information, thereby lowering storage.
One among Tabular’s early clients slashed its AWS storage invoice by upwards of $1 million per yr due to its use of Tabular. The massive gaming firm was ingesting 20.2 TB of supply Parquet information every day throughout 4 million information. After Tabular’s knowledge ingestion and compaction routines have been implmented, the variety of information was diminished to 60,000 throughout 1,100 Iceberg tables, totalling simply 10.4 TB in storage. “You’re by no means going to get a workforce of knowledge engineers to go, by hand, tune 1,100 tables, not to mention make it 50% smaller,” Blue says. “So it’s an enormous win.”
The way in which Blue sees it, the Tabular service provides knowledge lake clients within the cloud an open storage layer that could be a lot smarter than what got here earlier than it.
“I feel that is without doubt one of the pitfalls of coming from the Hadoop panorama, as a result of earlier than, your storage was dumb,” the 2022 Datanami Particular person to Watch says. “It didn’t do something for you. You had a catalog that was both [AWS] Glue or the Hive metastore that kind of described what was in S3, and that was it.”
The open desk codecs give customers extra confidence that their knowledge is appropriate and there aren’t soiled reads coming from a number of engines accessing the identical piece of knowledge on the similar time. The fee to realize these ACID ensures with desk codecs is a little more technical complexity, Blue says. Iceberg maintains extra historical past to make sure knowledge integrity, and typically there’s a must go in and delete that historical past when it’s not wanted, which is what Tabular offers.
In different phrases, an S3 knowledge lake paired with Tabular’s knowledge service features much more like a typical knowledge warehouse does than your typical Hadoop or S3 lake, Blue says.
“I feel the analogy of us as the underside half of an information warehouse makes much more sense,” he says. “Within the Hadoop house, you don’t assume ‘Oh, hey, somebody must go preserve my tables.’ However within the knowledge warehouse house, you do assume that. ‘In fact Snowflake retains your knowledge compacted and in a performant structure.’![]()
“Properly, what service is doing that work?” he continues. “In Hadoop, it was knowledge engineers. It was those that we stated, ‘Hey, right here’s a scheduler. Go determine find out how to make every thing environment friendly.’ We’re simply the automated type of that…. We’ll handle compaction and optimization. So we’ll have a look at the information and every desk individually and learn the way ought to we be storing that knowledge for the perfect question efficiency, the perfect storage effectivity, and many others.”
Tabular service is at the moment solely usually obtainable on AWS and S3, which it unveiled in March. Tabular clients can use no matter open supply question engines they need in opposition to their Tabular tables, together with EMR and Athena, which was additionally introduced at present and is at the moment in preview. Prospects also can use Galaxy, the hosted model of Trino from Starburst, in addition to open supply Trino or Presto. They will additionally entry knowledge from Snowflake in the event that they like, Blue says.
At present’s $26 million funding spherical provides the San Jose, California firm the monetary assets it must proceed growing the product. Presently, the corporate has an early preview of Google Cloud Storage, with plans to make that GA quickly. The plan requires supporting Microsoft Azure, Minio, and Cloudflare as nicely, Blue says.
Greater than 1,500 folks to date have signed as much as check out the Tabular service, though not all are paying clients. “We now have a improbable quantity of curiosity within the product that we’ve launched,” Blue says. “We’ve gotten precisely the form of bottom-up interplay that we have been hoping for, with folks letting us know what they’d like to see enhance.”

Ryan Blue is the CEO and co-founder of Tabular
The eventual aim is to offer knowledge optimization providers for nearly any object storage system, successfully turning these knowledge lakes into extremely performant knowledge warehouses, however with out subjecting clients to the lock-in usually related to these excessive efficiency warehouses.
Martin Casado, basic accomplice at Andreesen Horowitz, which particpated within the present spherical at Tabular that was led by Altimeter Capital, says providers like Tabular may help foster an open knowledge ecosystem.
“The cloud ecosystem has begun to consolidate round a small constellation of full-stack distributors, creating an actual danger of rent-seeking habits that may negatively influence clients and stifle innovation,” Casado stated in a press launch. “Impartial and open platforms akin to Tabular supply a path to wholesome competitors and adaptability for enterprises.”
Associated Gadgets:
Cloudera Sees Iceberg All over the place
Iceberg Information Companies Emerge from Tabular, Dremio
Apache Iceberg: The Hub of an Rising Information Service Ecosystem?