
{kind=link}
Initially revealed on July 8, 2020
Yesterday I learn an analyst report that the serverless structure market will probably be $21B by 2025. I additionally just lately met with Alex DeBrie, creator of the DynamoDB ebook and loved studying about his serverless philosophy. He wrote an incredible submit about the important thing elements for selecting serverless databases right here, and we had an enchanting dialog about serverless indexing methods that complement them. Final week Bob Muglia, newly appointed govt chairman of FaunaDB, wrote an equally fascinating article about how client-serverless is basically the 4th technology of utility mannequin.
From Datacenter to Cloud
Throughout my early days at VMware, we spent a number of time serious about admin controls. Why? As a result of enterprise IT groups all the time requested us for higher methods to handle datacenter infrastructure and management spend. Alongside got here AWS, turning the mannequin on its head, unlocking developer agility by way of self-service. The current period of cloud agility noticed corporations migrate their present stacks to the cloud, however there’s solely a lot you are able to do once you migrate software program constructed for information facilities into the cloud. Raise-and-shift cloud migration is a foul concept – you find yourself bringing alongside all the present datacenter complexity and attempting to drive suit your software program stack to operate in a completely new setting.
From Cloud to Serverless
If you consider it, what’s the level of manually sizing clusters, provisioning servers and managing cloud infrastructure when your software program is the most effective choose of precisely what sources it wants at any given level? Manually configuring software program within the cloud is a number of ops overhead, entails a bunch of sizing assumptions, over-provisioned compute/storage and nonetheless causes operational fires when issues begin to scale.
That is why the world is transferring from cloud-hosted structure to serverless structure – its the next-generation of cloud infrastructure companies that automates capability planning, deployment and scaling. The result’s that your software program is simpler to construct, keep and way more cost-efficient. No marvel the JAM stack and GraphQL are all the craze at this time. However what’s the ideally suited information stack for serverless architectures?
Serverless Knowledge Stack for Low Ops, Excessive Velocity Groups
A knowledge administration system is serverless, if one can load information, persist information, and run queries merely utilizing an information API –without ever having to consider servers. A few of the key facets of a serverless information administration system are:
- No database connections – Customers shouldn’t should handle database connections. It ought to be accessible by way of information APIs.
- No provisioning – Customers should not have to decide on what kind of {hardware} to provision for his or her datastore.
- No capability planning – Customers should not have to plan cluster capability at any level through the lifetime of the applying.
- No scaling limits – Customers should not have to fret about hitting a wall with their information footprint development. It ought to really feel like its infinitely scalable and limitless.
- No server upkeep – Customers should not have to consider safety patching, upgrading dependent modules, or monitoring servers—all of the duties required to assist 24 x 7 server uptime.
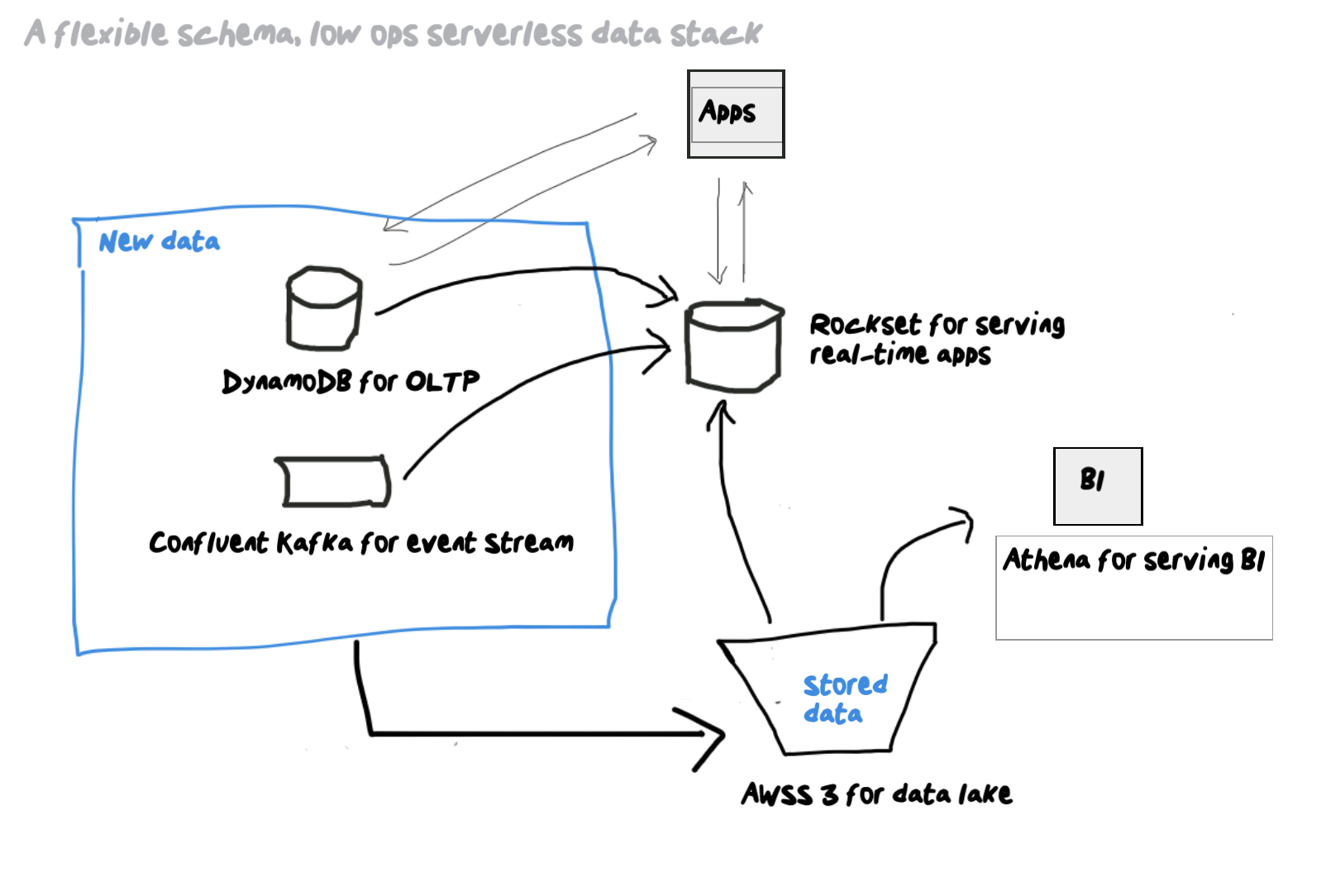
If you’re serious about your transactional database, there are some well-liked serverless choices it’s best to take into account, together with DynamoDB, Aurora serverless and FaunaDB. However what about your total information structure – what in regards to the different information shops you want and the way do you serve your BI and apps? Your information stack is 10x extra streamlined once you mix the the low ops method of serverless with flexibility of NoSQL information mannequin Such a trendy information stack within the cloud makes use of a serverless transactional database for OLTP, an information stream for occasions, an information lake with question engine for BI and a real-time indexing layer for serving functions. Here’s a reference structure – discover that DynamoDB, Kafka, S3, Athena and Rockset are all JSON-compatible serverless information shops so you might have a versatile schema, low ops information stack that unleashes developer agility like by no means earlier than.

What elements of your present utility stack are serverless? How a lot of your information structure has gone serverless? In case you’re new to serverless, here’s a curated listing of superior serverless occasions occurring round you.