
{kind=link}
Like bean dip and ogres, layers are the constructing blocks of the trendy information stack.
Its highly effective collection of tooling parts mix to create a single synchronized and extensible information platform with every layer serving a singular perform of the information pipeline.
Not like ogres, nonetheless, the cloud information platform is not a fairy story. New tooling and integrations are created nearly each day in an effort to enhance and elevate it.
So, with infinitely increasing integrations and the chance so as to add new layers for each characteristic and performance of your information movement, the query arises-where do you begin? Or to place it a distinct manner, how do you ship a information platform that drives actual worth for stakeholders with out constructing a platform that is both too complicated to handle or too costly to justify?
For small information groups constructing their first cloud-native platforms and groups making the leap from on-prem for the primary time, it is important to bias these layers that can have essentially the most quick influence on enterprise outcomes.
On this article, we’ll current you with the 5 Layer Information Stack-a mannequin for platform growth consisting of 5 important instruments that won’t solely permit you to maximize influence however empower you to develop with the wants of your group. These instruments embody:
And we can’t point out ogres or bean dip once more.
Let’s dive into it. (The content material, not the bean dip. Okay, that is actually the final time).
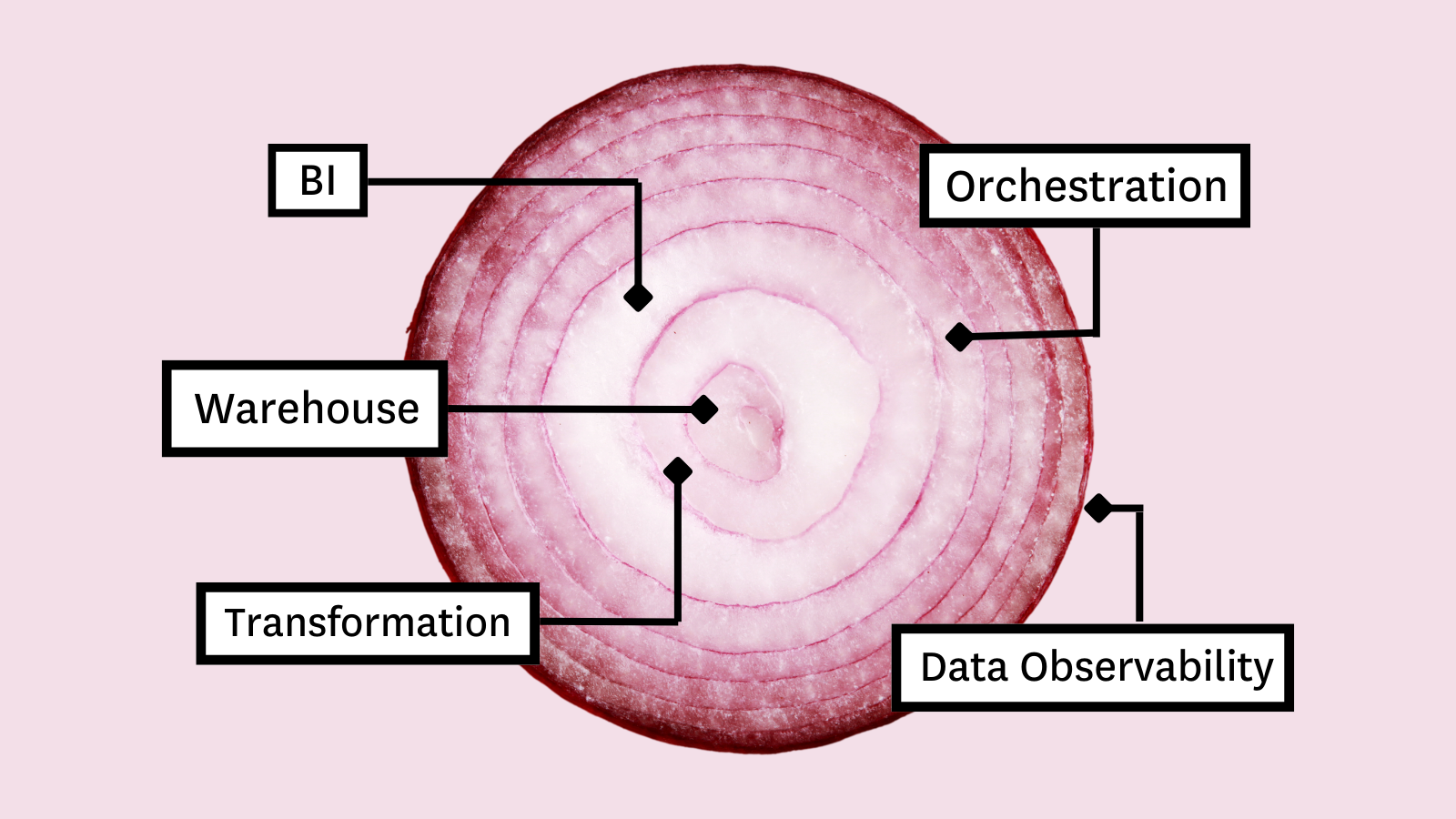
Cloud storage and compute
Whether or not you are stacking information instruments or pancakes, you all the time construct from the underside up. Like every good stack, an applicable basis is important to making sure the structural and purposeful integrity of your information platform.
Earlier than you possibly can mannequin the information on your stakeholders, you want a spot to gather and retailer it. The primary layer of your stack will usually fall into one in all three classes: a information warehouse resolution like Snowflake that handles predominantly structured information; a information lake that focuses on bigger volumes of unstructured information; and a hybrid resolution like Databricks’ Lakehouse that mixes parts of each.
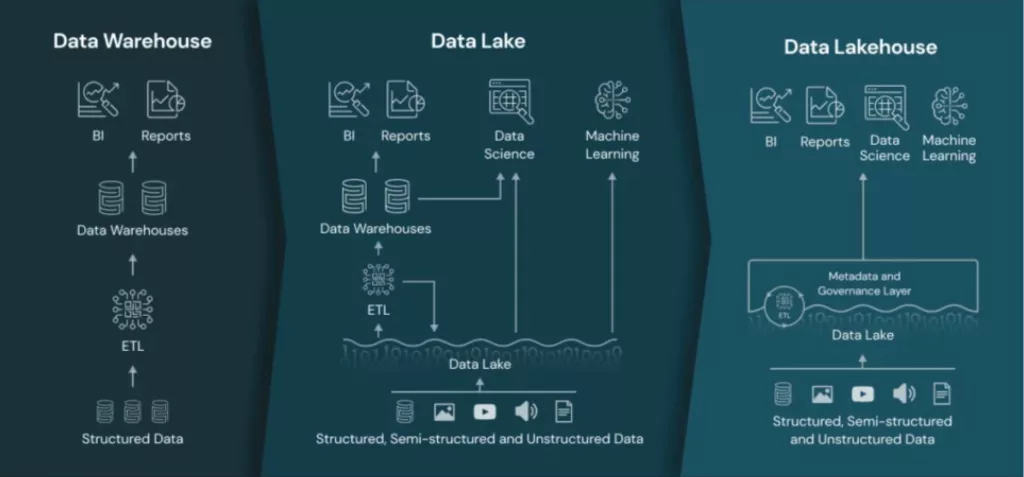
Picture courtesy of Databricks.
Nonetheless, this would possibly not merely be the place you retailer your information-it’s additionally the facility to activate it. Within the cloud information stack, your storage resolution is the first supply of compute energy for the opposite layers of your platform.
Now, I may get into the deserves of the warehouse, the lake, the lakehouse, and all the things in between, however that is not likely what’s essential right here. What’s essential is that you choose an answer that meets each the present and future wants of your platform at a useful resource price that is amenable to your finance staff. It would additionally dictate what instruments and options you can join sooner or later to fine-tune your information stack for brand spanking new use circumstances.
What particular storage and compute resolution you want will rely solely on what you are promoting wants and use-case, however our advice is to decide on one thing common-Snowflake, Databricks, BigQuery, etc-that’s effectively supported, well-integrated, and straightforward to scale.
Open-source is all the time a tempting resolution, however until you’ve got reached a stage of scale that truly necessitates it, it might probably current some main challenges for scaling on the storage and compute stage. Take our phrase for it, selecting a managed storage and compute resolution on the outset will prevent plenty of headache-and possible a painful migration-down the road.

Selecting the best cloud storage and compute layer can stop expensive migrations sooner or later.
Information transformation
Okay, so your information must stay within the cloud. Is smart. What else does your information platform want? Let us take a look at layer two of the 5 Layer Information Stack-transformation.
When information is first ingested, it is available in all kinds of enjoyable sizes and shapes. Completely different codecs. Completely different constructions. Completely different values. In easy phrases, information transformation refers back to the technique of changing all that information from a wide range of disparate codecs into one thing constant and helpful for modeling.

How completely different information pipeline structure designs deal with completely different parts of the information lifecycle.
Historically, transformation was a guide course of, requiring information engineers to hard-code every pipeline by hand inside a CLI.
Just lately, nonetheless, cloud transformation instruments have begun to democratize the information modeling course of. In an effort to make information pipelines extra accessible for practitioners, automated information pipeline instruments like dbt Labs, Preql, and Dataform permit customers to create efficient fashions with out writing any code in any respect.
Instruments like dbt depend on what’s often known as “modular SQL” to construct pipelines from frequent, pre-written, and optimized plug-and-play blocks of SQL code.
As you start your cloud information journey, you may rapidly uncover new methods to mannequin the information and supply worth to information customers. You may area new dashboard requests from finance and advertising and marketing. You may discover new sources that have to be launched to present fashions. The alternatives will come quick and livid.
Like many layers of the information stack, coding your individual transforms can work on a small scale. Sadly, as you start to develop, manually coding transforms will rapidly grow to be a bottleneck to your information platform’s success. Investing in out-of-the-box operationalized tooling is usually essential to remaining aggressive and persevering with to offer new worth throughout domains.
However, it isn’t simply writing your transforms that will get cumbersome. Even for those who may code sufficient transforms to cowl your scaling use-cases, what occurs if these transforms break? Fixing one damaged mannequin might be no large deal, however fixing 100 is a pipe dream (pun clearly meant).
Improved time-to-value for scaling organizations
Transformation instruments like dbt make creating and managing complicated fashions quicker and extra dependable for increasing engineering and practitioner groups. Not like guide SQL coding which is mostly restricted to information engineers, dbt’s modular SQL makes it doable for anybody accustomed to SQL to create their very own information pipelines. This implies quicker time to worth for busy groups, decreased engineering drain, and, in some circumstances, a decreased demand on experience to drive your platform ahead.
Flexibility to experiment with transformation sequencing
An automatic cloud transformation layer additionally permits for information transforms to happen at completely different phases of the pipeline, providing the pliability to experiment with ETL, ELT, and all the things in between as your platform evolves.
Permits self-service capabilities
Lastly, an operationalized rework device will pave the street for a totally self-service structure within the future-should you select to journey it.
Enterprise Intelligence (BI)
If transformation is layer two, then enterprise intelligence must be layer three.
Enterprise intelligence within the context of information platform tooling refers back to the analytical capabilities we current to end-users to meet a given use-case. Whereas our information could feed some exterior merchandise, enterprise intelligence capabilities are the first information product for many groups.
Whereas enterprise intelligence instruments like Looker, Tableau, and a wide range of open-source instruments can differ wildly in complexity, ease of use, and feature-sets, what these instruments all the time share is a capability to assist information customers uncover insights by means of visualization.
This one’s gonna be fairly self-explanatory as a result of whereas all the things else in your stack is a way to an finish, enterprise intelligence is usually the tip itself.
Enterprise intelligence is mostly the consumable product on the coronary heart of a information stack, and it is a necessary worth driver for any cloud information platform. As your organization’s urge for food to create and eat information grows, the necessity to entry that information rapidly and simply will develop proper together with it.
Enterprise intelligence tooling is what makes it doable on your stakeholders to derive worth out of your information platform. With out a technique to activate and eat the information, there can be no want for a cloud information platform at all-no matter what number of layers it had.
Information observability
The typical information engineering staff spends roughly two days per week firefighting unhealthy information. In actual fact, in response to a latest survey by Gartner, unhealthy information prices organizations a mean of $12.9 million per yr. To mitigate all that monetary threat and shield the integrity of your platform, you want layer 4: information observability.
Earlier than information observability, some of the frequent methods to find information high quality points was by means of guide SQL checks. Open supply information testing instruments like Nice Expectations and dbt enabled information engineers to validate their group’s assumptions concerning the information and write logic to stop the difficulty from working its manner downstream.

Information observability platforms use machine studying as a substitute of guide coding to robotically generate high quality checks for issues like freshness, quantity, schema, and null charges throughout all of your manufacturing tables. Along with complete high quality protection, a great information observability resolution may also generate each desk and column-level lineage to assist groups rapidly establish the place a break occurred and what’s been impacted primarily based on upstream and downstream dependencies.
The worth of your information platform-and by extension its products-is inextricably tied to the standard of the information that feeds it. Rubbish in, rubbish out. (Or nothing out for those who’ve received a damaged ingestion job.) To have dependable, actionable, and helpful information merchandise, the underlying information must be reliable. If you cannot belief the information, you possibly can’t belief the information product.
Sadly, as your information grows, your information high quality points will develop proper together with it. The extra complicated your platform, the extra sources you ingest, the extra groups you support-the extra high quality incidents you are more likely to have. And as groups more and more leverage information to energy AI fashions and ML use circumstances, the necessity to guarantee its belief and reliability grows exponentially.
Whereas information testing can present some high quality protection, its perform is restricted to recognized points and particular tables. And since every test guide take a look at must be coded by hand, scalability is barely proportionate to your accessible engineering assets. Information observability, then again, gives plug-and-play protection throughout each desk robotically, so you may be alerted to any information high quality incident-known or unknown-before it impacts downstream customers. And as your platform and your information scale, your high quality protection will scale together with it.
Plus, on prime of automated protection, most information observability instruments provide end-to-end lineage right down to the BI layer, which makes it doable to really root trigger and resolve high quality incidents. That may imply hours of time recovered on your information staff. Whereas conventional guide testing could possibly catch a portion of high quality incidents, it is ineffective that can assist you resolve them. That is much more alarming if you notice that time-to-resolution has almost doubled for information groups year-over-year.
Not like information testing which is reactionary by nature, information observability gives proactive visibility into recognized and unknown points with a real-time report of your pipeline lineage to place your information platform for development – all with out sacrificing your staff’s time or assets.
Information orchestration
While you’re extracting and processing information for analytics, the order of operation issues. As we have seen already, your information would not merely exist throughout the storage layer of your information stack. It is ingested from one supply, housed in one other, then ferried someplace else to be remodeled and visualized.
Within the broadest phrases, information orchestration is the configuration of a number of duties (some could also be automated) right into a single end-to-end course of. It triggers when and the way important jobs will probably be activated to make sure information flows predictably by means of your platform on the proper time, in the best sequence, and on the applicable velocity to take care of manufacturing requirements. (Type of like a conveyor belt on your information merchandise.)
Not like storage or transformation, pipelines do not require orchestration to be thought-about functional-at least not at a foundational stage. Nonetheless, as soon as information platforms scale past a sure level, managing jobs will rapidly grow to be unwieldy by in-house requirements.
While you’re extracting and processing a small quantity of information, scheduling jobs requires solely a small quantity of effort. However if you’re extracting and processing very massive quantities of information from a number of sources and for numerous use circumstances, scheduling these jobs requires a really great amount of effort-an inhuman quantity of effort.
The explanation that orchestration is a purposeful necessity of the 5 Layer Information Stack-if not a literal one-is because of the inherent lack of scalability in hand-coded pipelines. Very like transformation and information high quality, engineering assets grow to be the limiting precept for scheduling and managing pipelines.
The fantastic thing about a lot of the trendy information stack is that it permits instruments and integrations that take away engineering bottlenecks, liberating up engineers to offer new worth to their organizations. These are the instruments that justify themselves. That is precisely what orchestration does as effectively.
And as your group grows and silos naturally start to develop throughout your information, having an orchestration layer in place will place your information staff to take care of management of your information sources and proceed to offer worth throughout domains.
Among the hottest options for information orchestration embody Apache Airflow, Dagster, and relative newcomer Prefect.
A very powerful half? Constructing for influence and scale
After all, 5 is not the magic quantity. An ideal information stack might need six layers, seven layers, or 57 layers. And lots of of these potential layers-like governance, information contracts, and even some extra testing-can be fairly helpful relying on the stage of your group and its platform.
Nonetheless, if you’re simply getting began, you do not have the assets, the time, and even the requisite use circumstances to boil the Mariana Trench of platform tooling accessible to the trendy information stack. Greater than that, every new layer will introduce new complexities, new challenges, and new prices that can have to be justified. As an alternative, concentrate on what issues most to understand the potential of your information and drive firm development within the close to time period.
Every of the layers talked about above-storage, transformation, BI, information observability, and orchestration-provides a necessary perform of any absolutely operational fashionable information stack that maximizes influence and gives the quick scalability you may must quickly develop your platform, your use circumstances, and your staff sooner or later.
For those who’re a information chief who’s simply getting began on their information journey and also you need to ship a lean information platform that limits prices with out sacrificing energy, the 5 Layer Information Stack is the one to beat.
The submit Tips on how to Construct a 5-Layer Information Stack appeared first on Datafloq.