
{kind=link}
It looks as if everybody and their mom is speaking about AI lately. And for good cause: numerous AI-driven instruments have gotten extra accessible than ever, and so they’ve superior previous the alarmingly innacurate first iteration of the speech-to-text voicemail transcription characteristic on the iPhone. Machine studying is a subset of AI, and it impacts your life in additional methods than you might notice. As a SparkFan, studying extra about it may additionally get you to start out fascinated with utilizing it in your initiatives, and the way your knowledge could possibly be used for superior software program functions.

That is how the AI takeover will start.
Since machine studying is on pattern proper now, you might suppose it’s simply one other buzzword folks within the business are throwing round once they wish to sound sensible or cutting-edge. (Personally when I attempt to sound cutting-edge, I simply insert a point out of the floppy disk into informal dialog, however to every their very own.) Nevertheless, machine studying is just not solely a really actual up-and-comer, it is already right here. Understanding the way it works is useful not simply to the tech fanatic, however to anybody dwelling in our information-centric society.
By definition, Machine Studying is “the use and growth of pc programs which are capable of study and adapt with out following specific directions, by utilizing algorithms and statistical fashions to investigate and draw inferences from patterns in knowledge.” That is a big umbrella that describes numerous present know-how we see each day. This weblog is the primary installment of a sequence all about machine studying, its influence, and what it may imply for you. Right this moment we’ll be speaking concerning the fundamentals of ML, the several types of ML, and the way they’re used.
Fundamentals of ML
Knowledge
Machine Studying depends closely on knowledge as a result of it’s a data-driven strategy to downside fixing and choice making. The elemental idea behind Machine Studying is to allow computer systems to study patterns, make predictions, and enhance their efficiency based mostly on experiences gained from knowledge. By exposing ML algorithms to a various and consultant dataset, they’ll uncover underlying patterns that allow them to generalize and make correct predictions on new knowledge.
If there isn’t any knowledge, there’s nothing to study. Supply: Mapendo
In lots of ML duties, the standard and relevance of options (enter variables) considerably influence the mannequin’s efficiency. Knowledge supplies the required info to extract significant options which are important for efficient studying and decision-making. Through the coaching section, ML fashions alter their inner parameters to reduce the discrepancy between their predictions and the precise knowledge (labels). The extra knowledge the mannequin is uncovered to, the extra it will probably fine-tune its parameters, resulting in improved efficiency and generalization. The bigger the dataset, the extra correct the outcomes.
In complicated duties resembling picture recognition, pure language processing, or deep studying, the fashions typically have thousands and thousands of parameters that should be estimated. Ample knowledge is required to optimize these parameters successfully and forestall overfitting or underfitting. Nevertheless, whereas the quantity of knowledge is vital in Machine Studying, the standard of the info is equally important. Biased, noisy, or inadequate knowledge can result in poor or biased fashions. Preprocessing and cautious curation of knowledge are mandatory steps to make sure that the ML fashions can study and generalize successfully, resulting in extra dependable and correct outcomes.
Algorithms
Along with being the upper energy behind your extremely curated feed on Instagram and TikTok that is aware of you are out of bathroom paper earlier than you do, an algorithm is a finite set of directions wanted to carry out a process or remedy an issue. In the event you’ve ever taken CS 101, you’ve got in all probability heard the peanut butter and jelly downside: inform a pc how you can make a peanut butter and jelly sandwich. It is a helpful train that reveals you a pc cannot fill in gaps of information or context like we will. You may’t simply inform it “get two items of bread out” as a result of it does not know what bread appears to be like like, the place it is saved in your kitchen, or the place to place it. With the intention to precisely get your sandwich, you must be painfully specific in your directions.

This robotic has by no means even heard of bread, so he is doing fairly nicely, all issues thought of. Supply: Inspirit Students
That is an instance of an algorithm – rigorous, outlined directions to do one thing particular. Computer systems aren’t sensible, they cannot suppose for themselves and so they cannot do something the programmer does not make doable for them. Nevertheless, they’re extraordinarily quick, and that is why we use them. Pc scientists optimize algorithms for velocity and ease, and the machine will do precisely because it’s advised to unravel complicated calculations and automate choices and duties.
In machine studying, the purpose is to get the pc to find its personal algorithm by studying from a dataset with out specific programming. These algorithms wish to attain a degree the place they’ll precisely classify new knowledge based mostly on previous knowledge, or make choices from the info they’re receiving based mostly on earlier occasions. The previous knowledge trains the algorithm on how you can course of the brand new knowledge. Utilizing an iterative course of, it retains checking its predictions off recognized options, then alters the mannequin to suit. Given sufficient examples of a correctly assembled peanut butter and jelly, it’d be capable to discern the recipe.
A core assumption of machine studying that permits this course of is generalization – if one thing has labored 99 occasions earlier than, we will assume it is going to work the a hundredth time it is tried. If a picture with sure properties has been precisely labeled as a crosswalk 99 occasions, we will assume the subsequent time the algorithm encounters an identical picture it is going to classify it as a crosswalk.
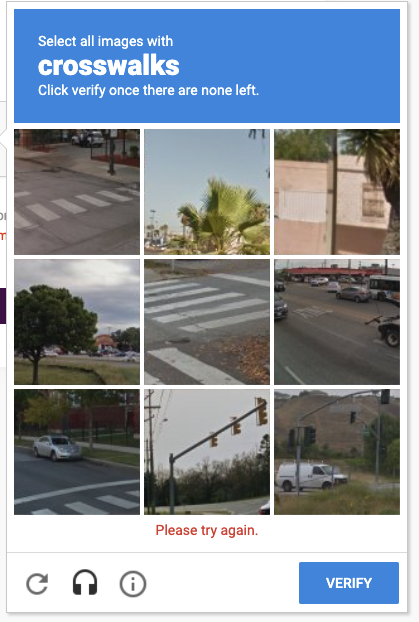
Each captcha you’ve got ever achieved has been feeding a mannequin. Thanks on your service.
Fashions
The ML algorithm is the mechanism that learns from knowledge, whereas the ML mannequin is the realized information that may be utilized to new knowledge for making predictions or choices. The algorithm processes the coaching knowledge, adjusting its inner parameters to seize patterns, and produces the mannequin as its finish consequence. Educated by ML algorithms, fashions use these patterns and relationships throughout the coaching knowledge, permitting them to generalize and apply that information to real-world eventualities.
As soon as the mannequin is skilled, it may be deployed and used to make predictions or carry out varied duties in autonomous automobiles, picture recognition, and pure language processing. By creating significant characteristic representations, fashions remodel uncooked knowledge into actionable info, making them priceless instruments in optimizing duties and bettering effectivity. Their versatility permits deployment throughout totally different programs, enhancing automation and aiding in decision-making processes.
There are lots of several types of fashions, and plenty of are specialised for particular functions. Listed below are among the fashions generally utilized in ML:
-
Linear Regression: Establishes a linear relationship between enter options and a steady goal variable, making it appropriate for predicting numerical values. The mannequin finds the best-fit line that minimizes the sum of squared errors between the anticipated values and the precise goal values. The slope and intercept of the road characterize the mannequin’s realized coefficients, which decide the connection between the options and the goal variable. Linear Regression is utilized in varied methods, resembling predicting home costs based mostly on options like measurement, location, and variety of rooms. Additionally it is utilized in finance to forecast inventory costs or in climate forecasting to foretell temperature developments.
-
Logistic Regression: A binary classification mannequin that predicts the chance of an enter belonging to certainly one of two lessons. It makes use of a logistic operate to map enter options to possibilities, that are then thresholded to make the ultimate class prediction. The mannequin’s coefficients characterize the power of the connection between options and the chance of belonging to a selected class. Logistic Regression is usually utilized in medical prognosis, resembling predicting the chance of a affected person having a sure illness based mostly on medical take a look at outcomes. Additionally it is utilized in spam e-mail filtering, sentiment evaluation, and credit score threat evaluation.
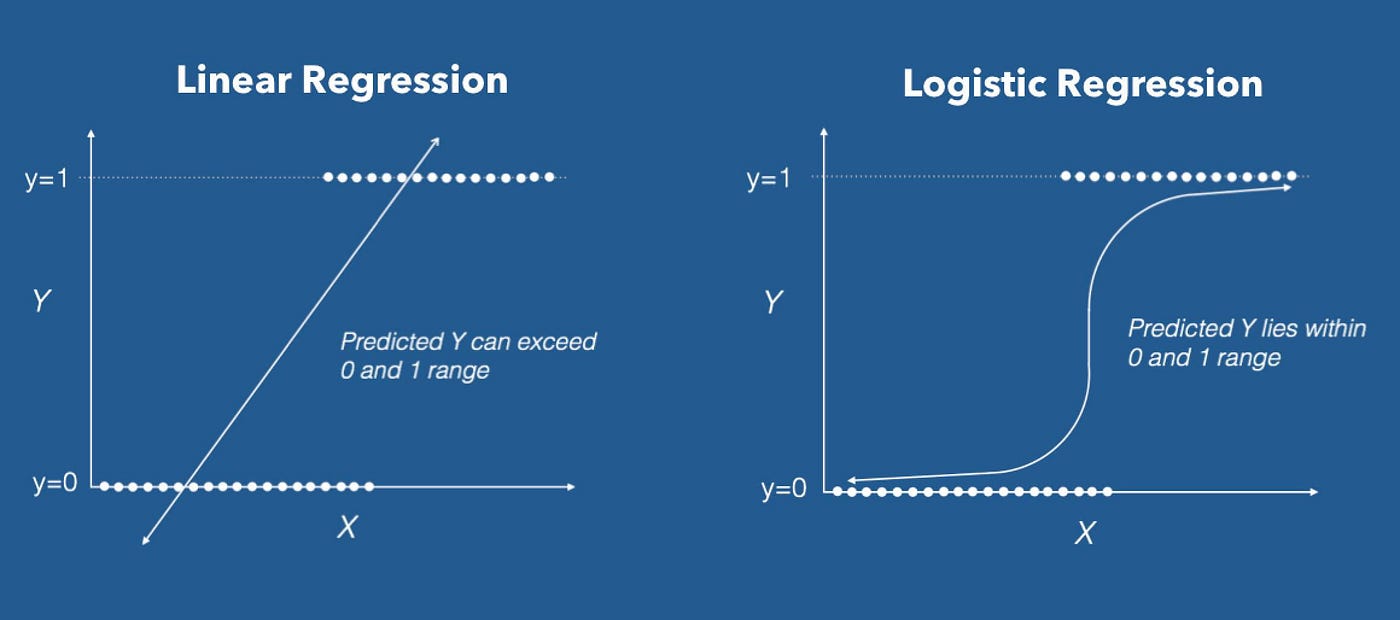
Comparability between linear and logistic regression. Supply: In direction of Knowledge Science
-
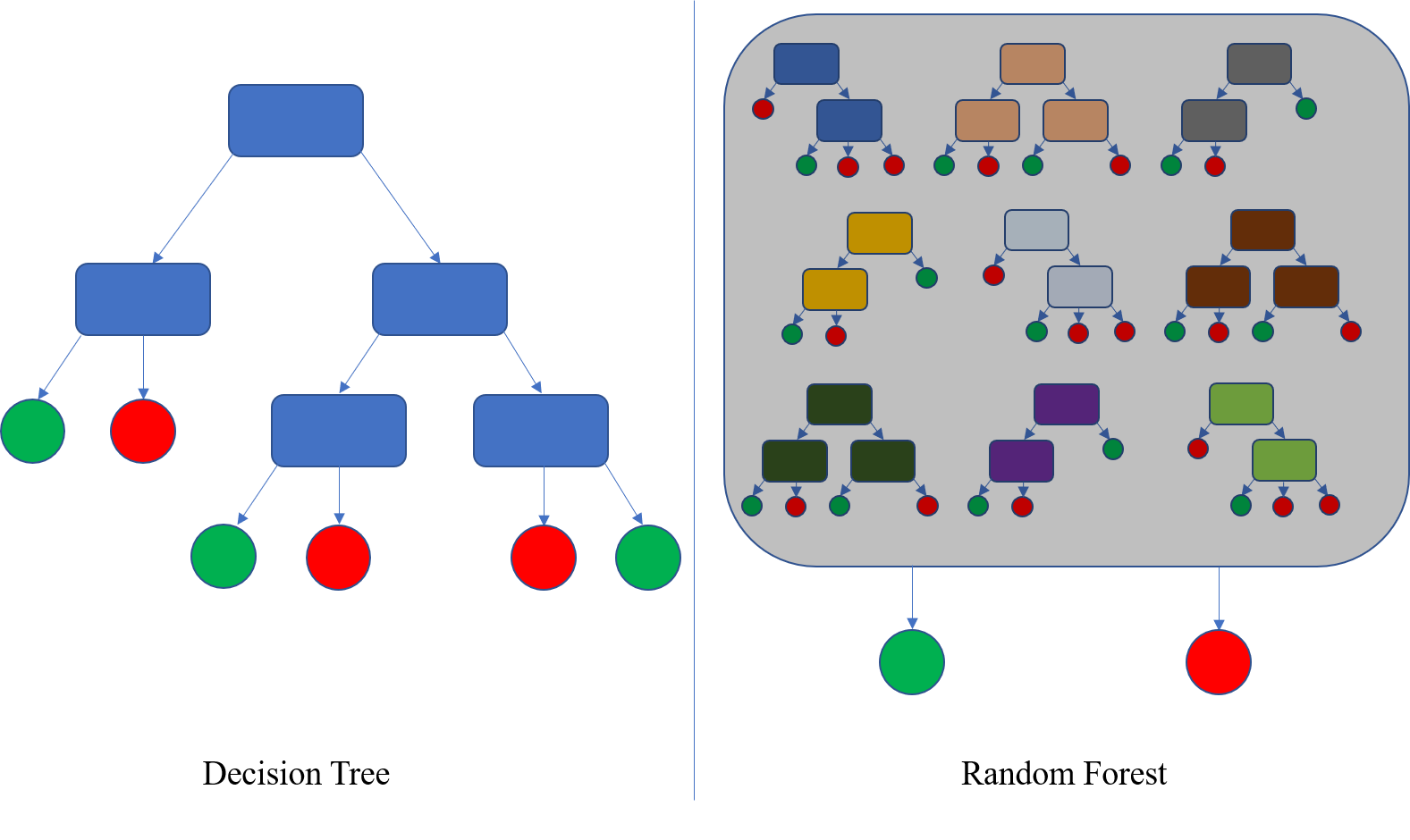
Resolution Timber: Intuitive ML fashions that create a tree-like construction based mostly on characteristic splits to make choices. Every inner node represents a characteristic, every department a call rule, and every leaf node an output class or worth. The mannequin selects the very best options and thresholds to separate the info into subsets which are homogenous by way of the goal variable.
Resolution Timber are well-liked for classification and regression duties, as they’re straightforward to know and interpret. They discover use in buyer segmentation, illness prognosis, and product advice programs. -
Random Forest: Persevering with with the arboreal vibes, Random Forest is an ensemble studying approach that mixes a number of choice bushes to enhance accuracy and scale back overfitting. It creates a number of choice bushes and combines their predictions to make the ultimate choice. Every tree is skilled on a random subset of the info with alternative, and have subsets are thought of for every cut up, making certain range among the many bushes. Random Forest is efficient in functions like picture recognition, the place it handles complicated and high-dimensional knowledge. It is also utilized in monetary forecasting and sentiment evaluation.
- Help Vector Machines (SVM): A robust ML mannequin used for classification and regression. It could actually assign classes to new examples given labeled classes. SVM maps examples to factors in area, then maximizes the hole between them, in search of to search out the optimum choice boundary. SVM is utilized in textual content classification like spam detection and sentiment evaluation, picture recognition, and bioinformatics.
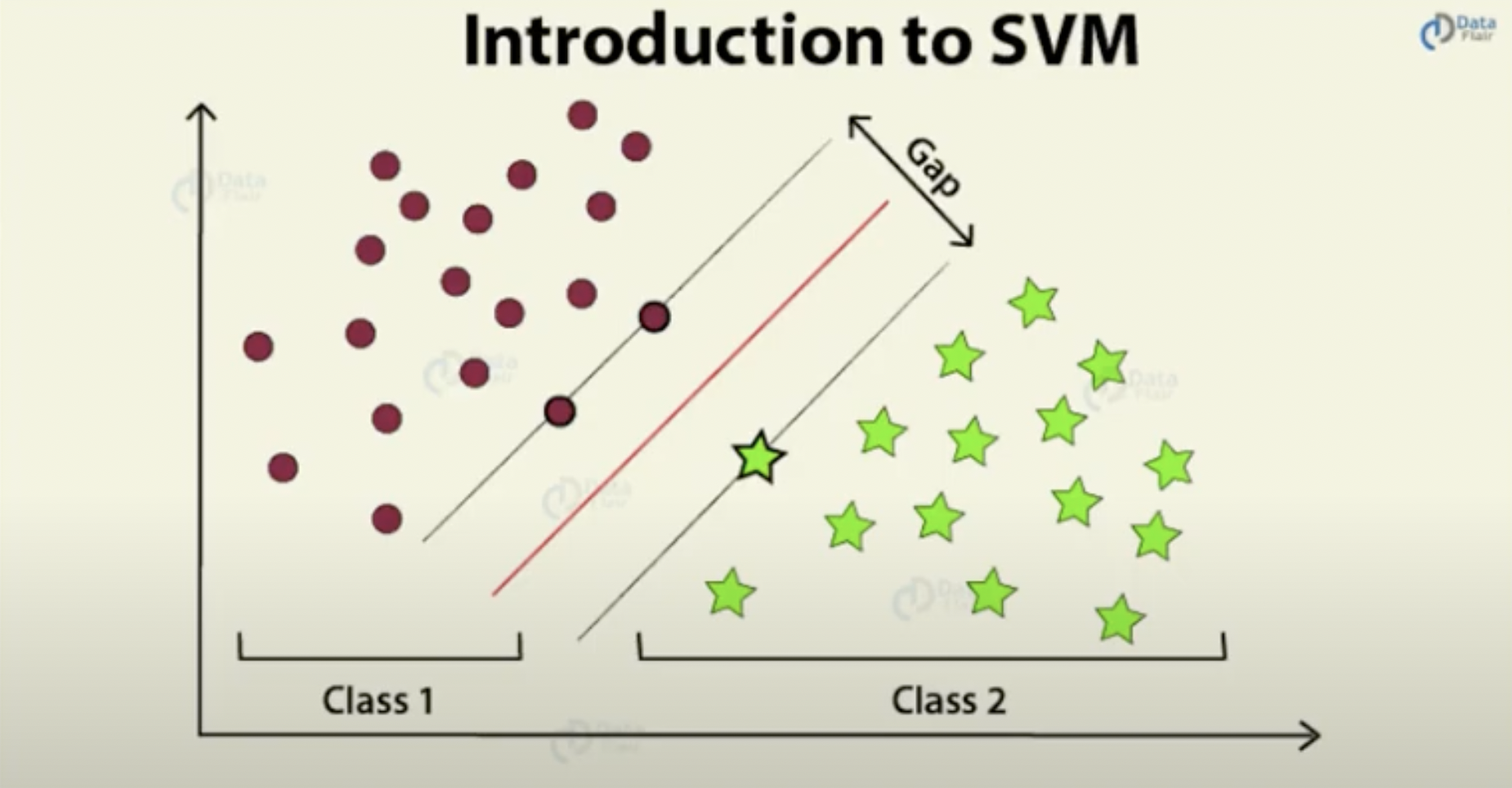
The place new factors lie throughout the hole will inform the mannequin how you can categorize them. Supply: Knowledge Aptitude
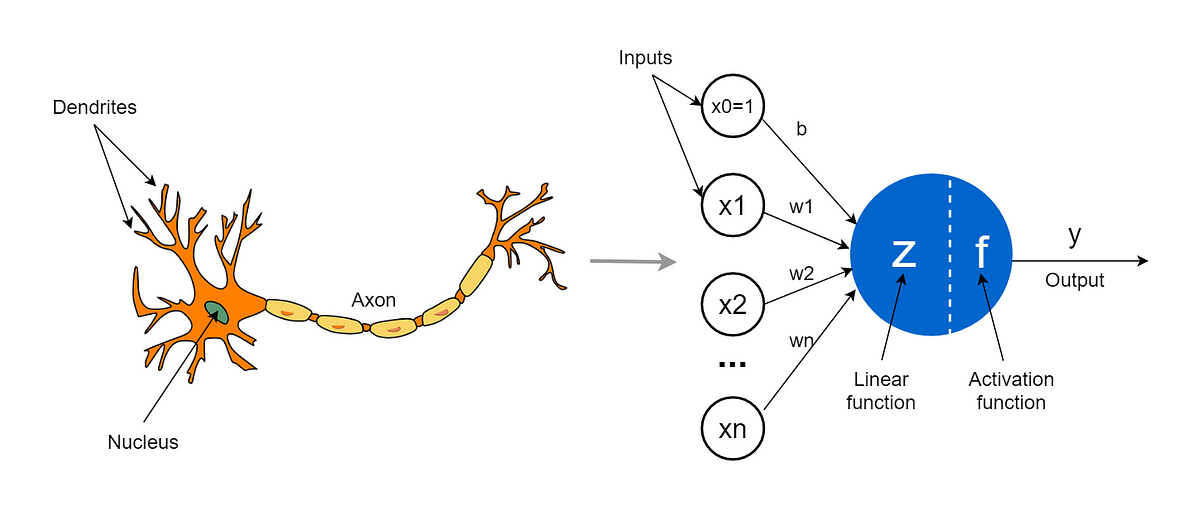
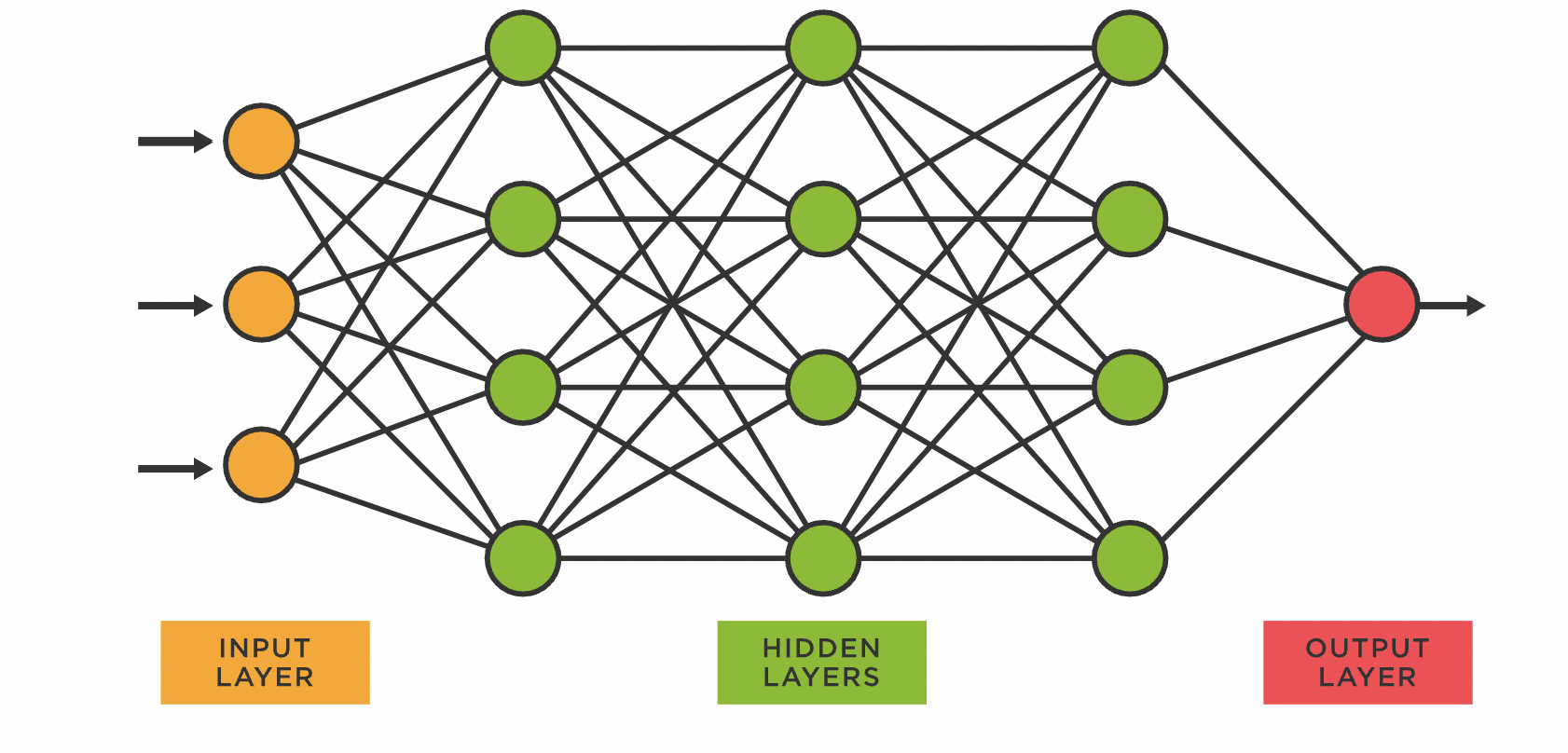
- Synthetic Neural Networks (ANN): Impressed by the human mind and include interconnected layers of synthetic neurons. They’re the inspiration of Deep Studying, which makes use of neural networks with a number of layers. ANN employs ahead and backward propagation to study complicated characteristic representations from the info, permitting them to deal with high-dimensional and nonlinear relationships. ANN is broadly utilized in picture and speech recognition, pure language processing, and autonomous automobiles. They’ve proven distinctive efficiency in duties like object detection, language translation, and enjoying strategic video games.
- Okay-Means Clustering: An unsupervised studying algorithm used for clustering. It teams n knowledge factors into ok clusters based mostly on their similarity – every datapoint belongs to the cluster with the closest imply. The algorithm begins with randomly initialized centroids for every cluster, then iteratively assigns knowledge factors to the closest centroid and recalculates the centroids’ positions till convergence. Okay-Means is used for focused advertising and marketing campaigns, picture compression, and anomaly detection. Additionally it is utilized in varied knowledge exploration and visualization duties.
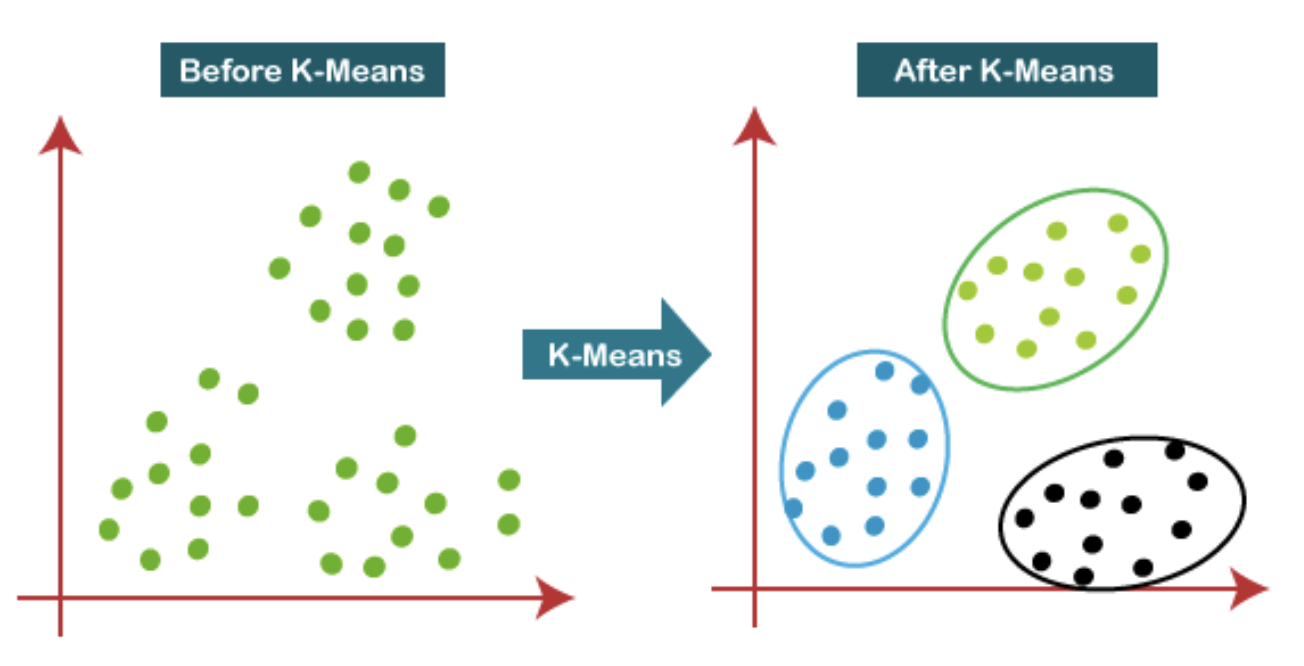
Supply: Java T Level
Forms of ML
The sphere of ML is continually creating and altering, however there are three predominant sorts that almost all ML strategies fall below.
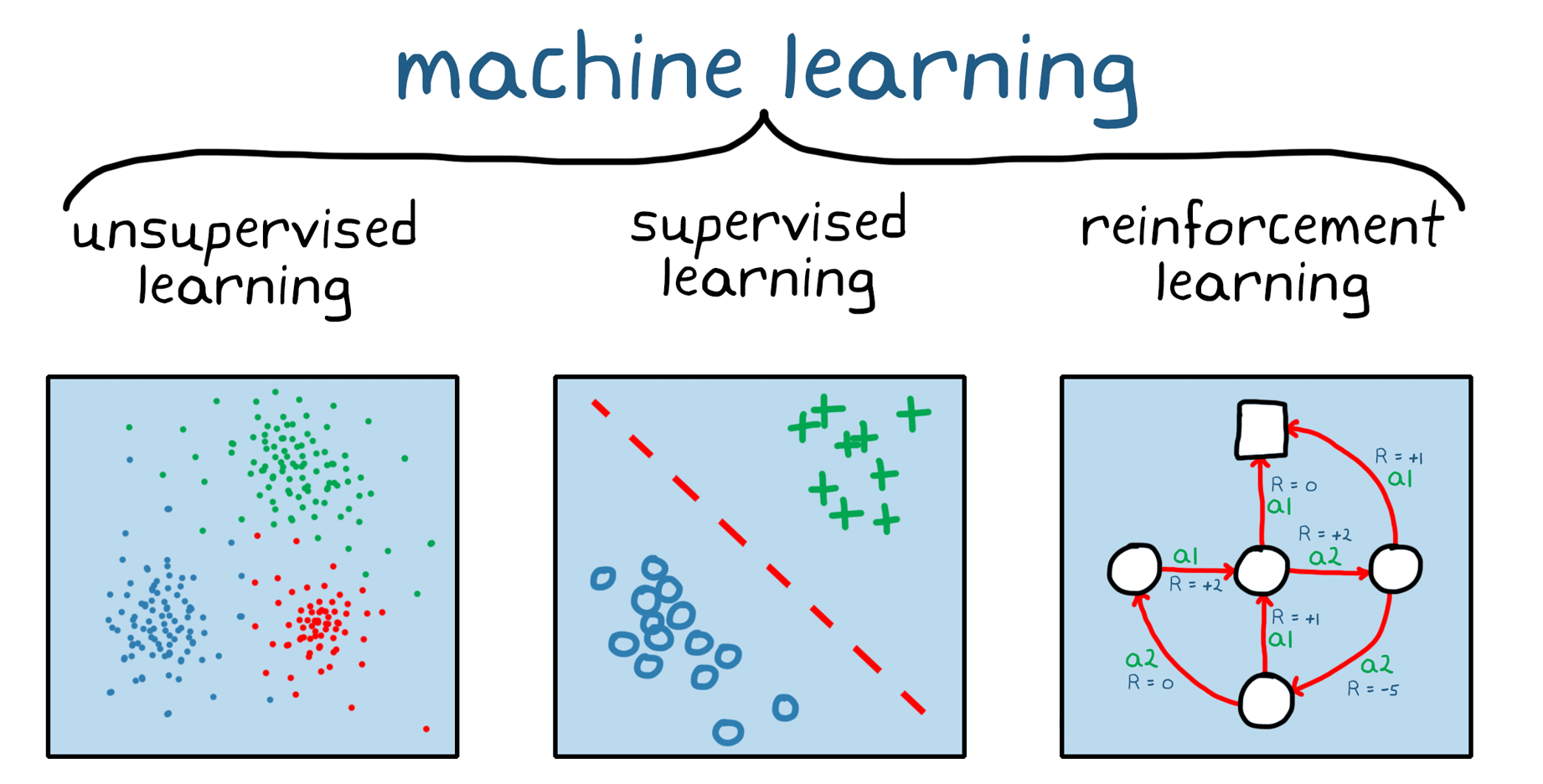
Supply: Math Works
Supervised Studying: Coaching Knowledge and Labels
Supervised studying is a sort of machine studying the place the mannequin is skilled on a labeled dataset, that means that every enter knowledge level has a corresponding output label or goal worth. The purpose of supervised studying is for the mannequin to study the connection between the enter options and their corresponding labels in order that it will probably make correct predictions on new knowledge it is by no means seen earlier than. Throughout coaching, the mannequin adjusts its inner parameters based mostly on the offered labeled examples, minimizing the error between its predictions and the true labels. Supervised studying is often used for duties like classification, the place the mannequin assigns enter knowledge to predefined classes, and regression, the place the mannequin predicts steady numerical values.
Actual life instance: galaxy classification. Galaxy Zoo started as a method to crowdsource the labeling of coaching knowledge. Though it began with galaxy photographs, Zooniverse now has many different classification labeling initiatives going, resembling handwriting transcription, wildlife monitoring, and gravitational wave detection.

Supply: Galaxy Zoo
Unsupervised Studying: Clustering and Dimensionality Discount
Unsupervised studying is a sort of machine studying the place the mannequin is skilled on an unlabeled dataset, that means that the info factors shouldn’t have corresponding output labels. In unsupervised studying, the mannequin seeks to search out patterns, buildings, or relationships throughout the knowledge with out particular steering. Widespread duties in unsupervised studying embody clustering, the place the mannequin teams related knowledge factors collectively based mostly on their similarities, and dimensionality discount, the place the mannequin reduces the variety of options whereas preserving necessary info. Unsupervised studying is effective for knowledge exploration and discovering hidden patterns in complicated datasets.
Actual life instance: local weather evaluation in Somalia. Researchers used unlabeled knowledge within the type of satellite tv for pc photographs to search out variations indicative of lack of vegetation.
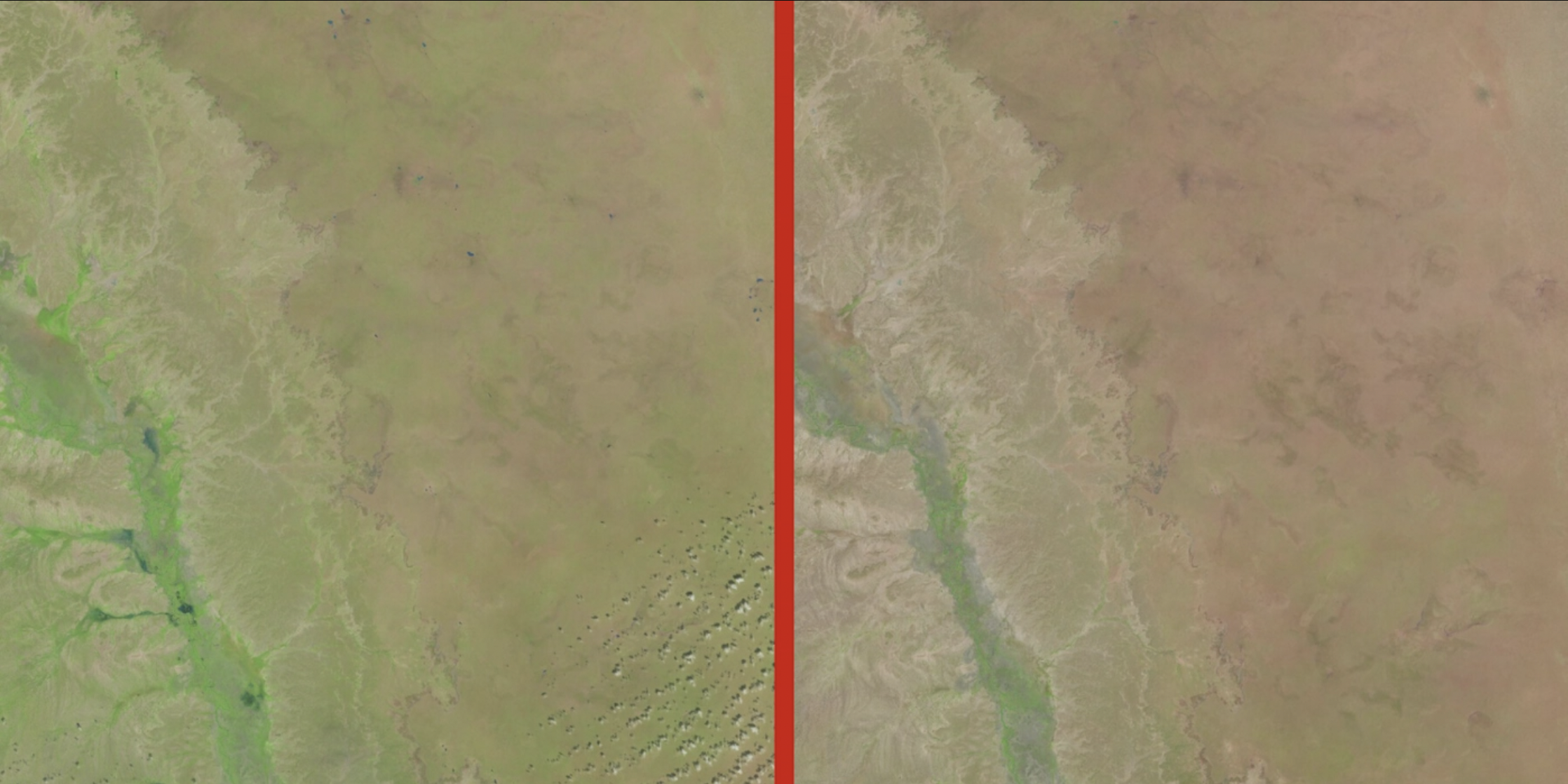
Supply: Omdena
Reinforcement Studying: The Position of Rewards and Brokers
Reinforcement studying is a sort of machine studying that offers with decision-making in an setting the place an agent interacts with the setting to attain a selected purpose. The agent receives suggestions within the type of rewards or penalties based mostly on its actions, guiding it to study from trial and error. The target of reinforcement studying is for the agent to study the optimum coverage or technique that maximizes cumulative rewards over time. The agent takes actions based mostly on what it has realized and frequently updates its choice making course of. Reinforcement studying is utilized in functions resembling robotics, sport enjoying, useful resource administration, and autonomous automobiles, the place the agent should make sequential choices to attain its objectives.
Actual life instance: site visitors alerts. A analysis group experimented with utilizing reinforcement studying to optimize site visitors alerts of their setting.
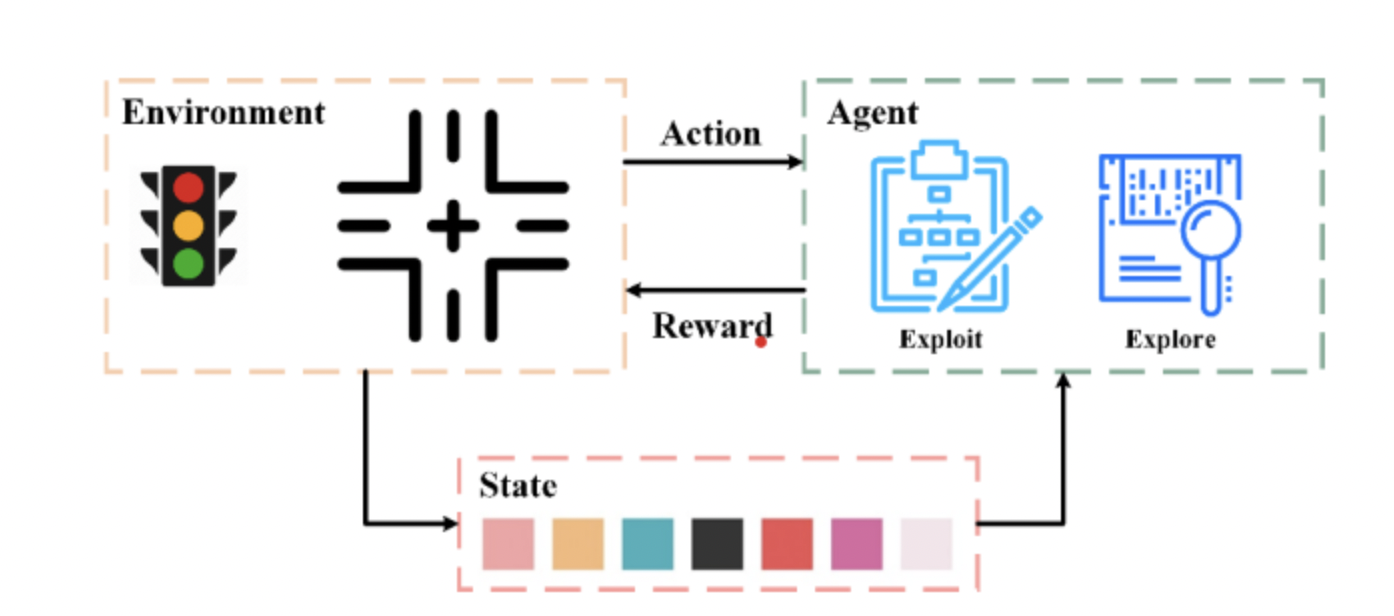
Supply: Li, Xu, Zhang
Keep tuned within the coming weeks for extra about machine studying’s historical past, TinyML, and the way this revolution will have an effect on you!
Utilizing ML in your work? We wish to hear about what kind you are using! Tell us within the feedback.