

{kind=link}
Amazon OpenSearch Service lately introduced Multi-AZ with Standby, a brand new deployment possibility for managed clusters that allows 99.99% availability and constant efficiency for business-critical workloads. With Multi-AZ with Standby, clusters are resilient to infrastructure failures like {hardware} or networking failure. This selection offers improved reliability and the additional benefit of simplifying cluster configuration and administration by imposing finest practices and lowering complexity.
On this put up, we share how Multi-AZ with Standby works beneath the hood to realize excessive resiliency and constant efficiency to fulfill the 4 9s.
Background
One of many ideas in designing extremely accessible methods is that they have to be prepared for impairments earlier than they occur. OpenSearch is a distributed system, which runs on a cluster of situations which have completely different roles. In OpenSearch Service, you’ll be able to deploy information nodes to retailer your information and reply to indexing and search requests, you may as well deploy devoted cluster supervisor nodes to handle and orchestrate the cluster. To supply excessive availability, one widespread strategy for the cloud is to deploy infrastructure throughout a number of AWS Availability Zones. Even within the uncommon case {that a} full zone turns into unavailable, the accessible zones proceed to serve visitors with replicas.
If you use OpenSearch Service, you create indexes to carry your information and specify partitioning and replication for these indexes. Every index is comprised of a set of major shards and nil to many replicas of these shards. If you moreover use the Multi-AZ function, OpenSearch Service ensures that major shards and reproduction shards are distributed in order that they’re in numerous Availability Zones.
When there’s an impairment in an Availability Zone, the service would scale up in different Availability Zones and redistribute shards to unfold out the load evenly. This strategy was reactive at finest. Moreover, shard redistribution throughout failure occasions causes elevated useful resource utilization, resulting in elevated latencies and overloaded nodes, additional impacting availability and successfully defeating the aim of fault-tolerant, multi-AZ clusters. A simpler, statically secure cluster configuration requires provisioning infrastructure to the purpose the place it may possibly proceed working appropriately with out having to launch any new capability or redistribute any shards even when an Availability Zone turns into impaired.
Designing for top availability
OpenSearch Service manages tens of hundreds of OpenSearch clusters. We’ve gained insights into which cluster configurations like {hardware} (information or cluster-manager occasion varieties) or storage (EBS quantity varieties), shard sizes, and so forth are extra resilient to failures and may meet the calls for of widespread buyer workloads. A few of these configurations have been included in Multi-AZ with Standby to simplify configuring the clusters. Nonetheless, this alone isn’t sufficient. A key ingredient in attaining excessive availability is sustaining information redundancy.
If you configure a single reproduction (two copies) on your indexes, the cluster can tolerate the lack of one shard (major or reproduction) and nonetheless get better by copying the remaining shard. A two-replica (three copies) configuration can tolerate failure of two copies. Within the case of a single reproduction with two copies, you’ll be able to nonetheless maintain information loss. For instance, you possibly can lose information if there’s a catastrophic failure in a single Availability Zone for a chronic length, and on the identical time, a node in a second zone fails. To make sure information redundancy always, the cluster enforces a minimal of two replicas (three copies) throughout all its indexes. The next diagram illustrates this structure.

The Multi-AZ with Standby function deploys infrastructure in three Availability Zones, whereas preserving two zones as energetic and one zone as standby. The standby zone gives constant efficiency even throughout zonal failures by making certain identical capability always and through the use of a statically secure design with none capability provisioning or information actions throughout failure. Throughout regular operations, the energetic zone serves coordinator visitors for learn and write requests and shard question visitors, and solely replication visitors goes to the standby zone. OpenSearch makes use of synchronous replication protocol for write requests, which by design has zero replication lag, enabling the service to instantaneously promote a standby zone to energetic within the occasion of any failure in an energetic zone. This occasion is known as a zonal failover. The beforehand energetic zone is demoted to the standby mode and restoration operations to deliver the state again to wholesome start.
Why zonal failover is vital however onerous to do proper
A number of nodes in an Availability Zone can fail as a result of all kinds of causes, like {hardware} failures, infrastructure failures like fiber cuts, energy or thermal points, or inter-zone or intra-zone networking issues. Learn requests could be served by any of the energetic zones, whereas write requests have to be synchronously replicated to all copies throughout a number of Availability Zones. OpenSearch Service orchestrates two modes of failovers: learn failovers and the write failovers.
The primarily objectives of learn failovers are excessive availability and constant efficiency. This requires the system to continually monitor for faults and shift visitors away from the unhealthy nodes within the impacted zone. The system takes care of dealing with the failovers gracefully, permitting all in-flight requests to complete whereas concurrently shifting new incoming visitors to a wholesome zone. Nonetheless, it’s additionally potential for a number of shard copies throughout each energetic zones to be unavailable in circumstances of two node failures or one zone plus one node failure (sometimes called double faults), which poses a danger to availability. To unravel this problem, the system makes use of a fail-open mechanism to serve visitors off the third zone whereas it might nonetheless be in a standby mode to make sure the system stays extremely accessible. The next diagram illustrates this structure.

An impaired community gadget impacting inter-zone communication may cause write requests to considerably decelerate, owing to the synchronous nature of replication. In such an occasion, the system orchestrates a write failover to isolate the impaired zone, slicing off all ingress and egress visitors. Though with write failovers the restoration is quick, it leads to all nodes together with its shards being taken offline. Nonetheless, after the impacted zone is introduced again after community restoration, shard restoration ought to nonetheless be capable to use unchanged information from its native disk, avoiding full section copy. As a result of the write failover leads to the shard copy to be unavailable, we train write failovers with excessive warning, neither too often nor throughout transient failures.
The next graph depicts that in a zonal failure, computerized learn failover prevents any influence to availability.
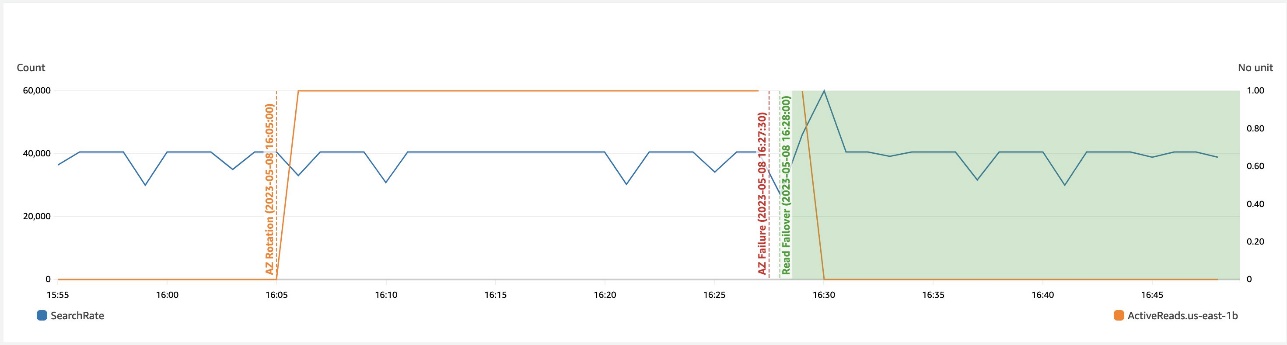
The next depicts that in a networking slowdown in a zone, write failover helps get better availability.

To make sure that the zonal failover mechanism is predictable (capable of seamlessly shift visitors throughout an precise failure occasion), we repeatedly train failovers and hold rotating energetic and standby zones even throughout regular state. This not solely verifies all community paths, making certain we don’t hit surprises like clock skews, stale credentials, or networking points throughout failover, but it surely additionally retains step by step shifting caches to keep away from chilly begins on failovers, making certain we ship constant efficiency always.
Enhancing the resiliency of the service
OpenSearch Service makes use of a number of ideas and finest practices to extend reliability, like computerized detection and sooner restoration from failure, throttling extra requests, fail quick methods, limiting queue sizes, shortly adapting to fulfill workload calls for, implementing loosely coupled dependencies, repeatedly testing for failures, and extra. We focus on a couple of of those strategies on this part.
Computerized failure detection and restoration
All faults get monitored at a minutely granularity, throughout a number of sub-minutely metrics information factors. As soon as detected, the system routinely triggers a restoration motion on the impacted node. Though most courses of failures mentioned thus far on this put up seek advice from binary failures the place the failure is definitive, there’s one other sort of failure: non-binary failures, termed grey failures, whose manifestations are delicate and often defy fast detection. Gradual disk I/O is one instance, which causes efficiency to be adversely impacted. The monitoring system detects anomalies in I/O wait occasions, latencies, and throughput, to detect and substitute a node with sluggish I/O. Sooner and efficient detection and fast restoration is our greatest wager for all kinds of infrastructure failures past our management.
Efficient workload administration in a dynamic setting
We’ve studied workload patterns that trigger the system both to be overloaded with too many requests, maxing out CPU/reminiscence, or a couple of rogue queries that may that both allocate big chunks of reminiscence or runaway queries that may exhaust a number of cores, both degrading the latencies of different vital requests or inflicting a number of nodes to fail as a result of system’s assets operating low. A few of the enhancements on this route are being executed as part of search backpressure initiatives, beginning with monitoring the request footprint at numerous checkpoints that forestalls accommodating extra requests and cancels those already operating in the event that they breach the useful resource limits for a sustained length. To complement backpressure in visitors shaping, we use admission management, which offers capabilities to reject a request on the entry level to keep away from doing non-productive work (requests both trip or get cancelled) when the system is already run excessive on CPU and reminiscence. Many of the workload administration mechanisms have configurable knobs. Nobody measurement suits all workloads, subsequently we use Auto-Tune to regulate them extra granularly.
The cluster supervisor performs vital coordination duties like metadata administration and cluster formation, and orchestrates a couple of background operations like snapshot and shard placement. We added a job throttler to regulate the speed of dynamic mapping updates, snapshot duties, and so forth to forestall overwhelming it and to let vital operations run deterministically on a regular basis. However what occurs when there isn’t any cluster supervisor within the cluster? The following part covers how we solved this.
Decoupling vital dependencies
Within the occasion of cluster supervisor failure, searches proceed as standard, however all write requests begin to fail. We concluded that permitting writes on this state ought to nonetheless be secure so long as it doesn’t must replace the cluster metadata. This modification additional improves the write availability with out compromising information consistency. Different service dependencies have been evaluated to make sure downstream dependencies can scale because the cluster grows.
Failure mode testing
Though it’s onerous to imitate all types of failures, we depend on AWS Fault Injection Simulator (AWS FIS) to inject widespread faults within the system like node failures, disk impairment, or community impairment. Testing with AWS FIS repeatedly in our pipelines helps us enhance our detection, monitoring, and restoration occasions.
Contributing to open supply
OpenSearch is an open-source, community-driven software program. Many of the modifications together with the excessive availability design to help energetic and standby zones have been contributed to open supply; the truth is, we comply with an open-source first growth mannequin. The basic primitive that allows zonal visitors shift and failover is predicated on a weighted visitors routing coverage (energetic zones are assigned weights as 1 and standby zones are assigned weights as 0). Write failovers use the zonal decommission motion, which evacuates all visitors from a given zone. Resiliency enhancements for search backpressure and cluster supervisor job throttling are a number of the ongoing efforts. When you’re excited to contribute to OpenSearch, open up a GitHub problem and tell us your ideas.
Abstract
Efforts to enhance reliability is a endless cycle as we proceed to study and enhance. With the Multi-AZ with Standby function, OpenSearch Service has built-in finest practices for cluster configuration, improved workload administration, and achieved 4 9s of availability and constant efficiency. OpenSearch Service additionally raised the bar by repeatedly verifying availability with zonal visitors rotations and automatic assessments through AWS FIS.
We’re excited to proceed our efforts into enhancing the reliability and fault tolerance even additional and to see what new and present options builders can create utilizing OpenSearch Service. We hope this results in a deeper understanding of the fitting degree of availability based mostly on the wants of your enterprise and the way this providing achieves the supply SLA. We might love to listen to from you, particularly about your success tales attaining excessive ranges of availability on AWS. When you have different questions, please go away a remark.
Concerning the authors
 Bukhtawar Khan is a Principal Engineer engaged on Amazon OpenSearch Service. He’s fascinated by constructing distributed and autonomous methods. He’s a maintainer and an energetic contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer engaged on Amazon OpenSearch Service. He’s fascinated by constructing distributed and autonomous methods. He’s a maintainer and an energetic contributor to OpenSearch.
 Gaurav Bafna is a Senior Software program Engineer engaged on OpenSearch at Amazon Net Companies. He’s fascinated about fixing issues in distributed methods. He’s a maintainer and an energetic contributor to OpenSearch.
Gaurav Bafna is a Senior Software program Engineer engaged on OpenSearch at Amazon Net Companies. He’s fascinated about fixing issues in distributed methods. He’s a maintainer and an energetic contributor to OpenSearch.
 Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has constructed AWS OpenSearch Service and AWS CloudSearch. His areas of experience embrace Info Retrieval, Giant scale distributed computing, low latency actual time serving methods and so on. He has huge expertise in designing and constructing internet scale methods for crawling, processing, indexing and serving textual content and multimedia content material. Previous to Amazon, he was a part of Yahoo!, constructing crawling and indexing methods for his or her search merchandise.
Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has constructed AWS OpenSearch Service and AWS CloudSearch. His areas of experience embrace Info Retrieval, Giant scale distributed computing, low latency actual time serving methods and so on. He has huge expertise in designing and constructing internet scale methods for crawling, processing, indexing and serving textual content and multimedia content material. Previous to Amazon, he was a part of Yahoo!, constructing crawling and indexing methods for his or her search merchandise.
 Ranjith Ramachandra is a Senior Engineering Supervisor engaged on Amazon OpenSearch Service. He’s captivated with extremely scalable distributed methods, excessive efficiency and resilient methods.
Ranjith Ramachandra is a Senior Engineering Supervisor engaged on Amazon OpenSearch Service. He’s captivated with extremely scalable distributed methods, excessive efficiency and resilient methods.
 Rohin Bhargava is a Sr. Product Supervisor with the Amazon OpenSearch Service group. His ardour at AWS is to assist clients discover the right combination of AWS companies to realize success for his or her enterprise objectives.
Rohin Bhargava is a Sr. Product Supervisor with the Amazon OpenSearch Service group. His ardour at AWS is to assist clients discover the right combination of AWS companies to realize success for his or her enterprise objectives.