
July 22, 2021
Robotic.txt, On-page Robotic Directions & their Significance in web optimization
Crawling, indexing, rendering and rating are the 4 primary parts of web optimization. This text will give attention to how robotic directions may be improved to have a constructive site-wide impression on web optimization and aid you handle what pages in your web site ought to and shouldn’t be listed for probably rating in Google, based mostly on your small business technique.
Google will crawl and index as many pages on an internet site that they’ll. So long as the pages aren’t behind a login utility, Google will attempt to index all of the pages it may well discover, except you might have supplied particular robotic directions to forestall it. Internet hosting a robots.txt file with crawling directions on the root of your area is an older means to supply the search engine steerage about what ought to and shouldn’t be listed and ranked on the positioning; It tells the search engine crawlers which pages, directories and information ought to or shouldn’t be listed for potential rating in Google or different search engines like google and yahoo. Now, for many indexing, Google sees the robots.txt directions as a advice, not a requirement (the principle caveat right here is that the brand new Google crawler, Duplex Bot, used for locating conversational info, nonetheless depends on the robots.txt file, in addition to a setting in Search Console, if that you must block its entry. (This shall be mentioned additional in a future article.) As an alternative, Google has begun contemplating on-page robots directions the first useful resource for steerage about crawling and indexing. As an alternative, Google has begun contemplating on-page robots directions the first useful resource for steerage about crawling and indexing. On-page robots directions are code that may be included within the <head> tag of the web page to point crawling indexing directions only for that web page. All internet pages that you don’t want Google to index should embrace particular on-page robotic directions that mirror or add to what could be included within the robots.txt file. This tutorial explains the way to reliably block pages which can be in any other case crawlable and never behind a firewall or login, from being listed and ranked in Google.
How you can Optimize Robotic Directions for web optimization
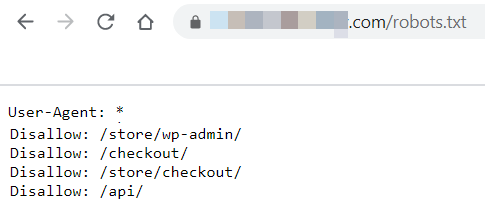
- Evaluation your present robots.txt: You will discover the robots.txt file on the root of the area, for instance: https://www.instance.com/robots.txt. We must always all the time begin with ensuring no web optimization optimized directories are blocked within the robots.txt. Under you may see an instance of a robots.txt file. On this robots.txt file, we all know it’s addressing all crawlers, as a result of it says Person-Agent: *. You may see robots.txt which can be consumer agent particular, however utilizing a star (*) is a ‘wildcard’ image that the rule may be utilized broadly to ‘all’ or ‘any’ – on this case bots or consumer brokers. After that, we see a listing of directories after the phrase ‘Disallow:’. These are the directories we’re requesting to not be listed, we wish to disallow bots from crawling & indexing them. Any information that seem in these directories might not be listed or ranked.
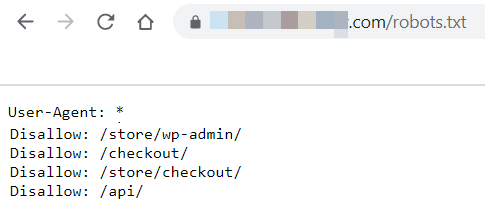
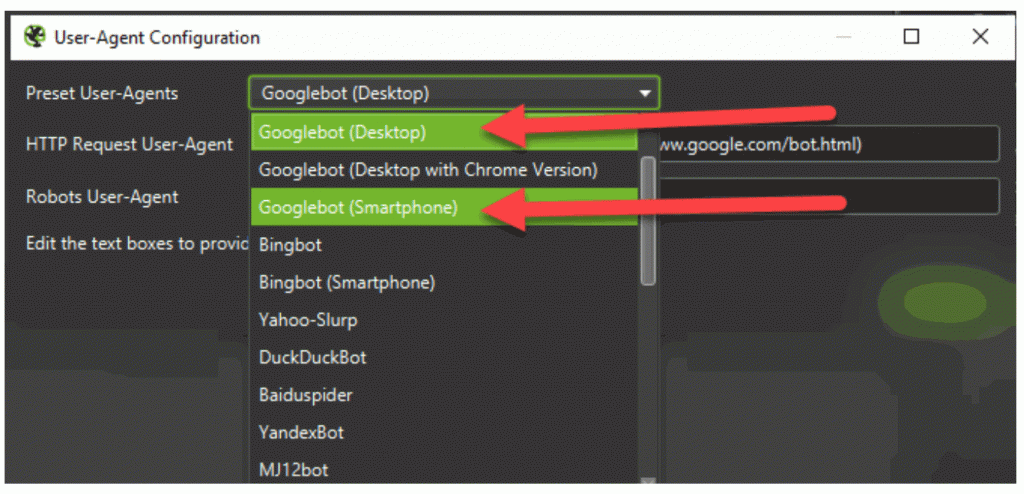
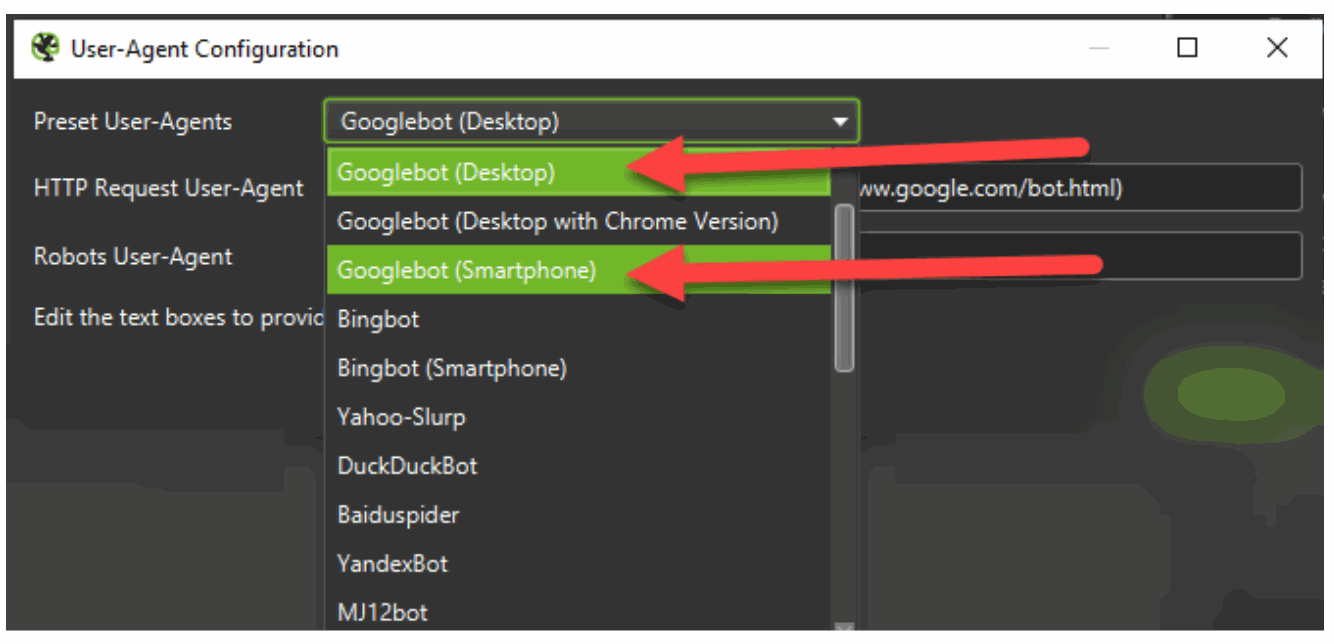
- Evaluation On-Web page Robots Directions: Google now takes on-page robots directions as extra of a rule than a suggestion. On-page robots directions solely impact the web page that they’re on and have the potential to restrict crawling of the pages which can be linked to from the web page as properly. They are often discovered within the supply code of the web page within the <head> tag. Right here is an instance for on web page directions <meta title=’robots‘ content material=’index, observe‘ /> On this instance, we’re telling the search engine to index the web page and observe the hyperlinks included on the web page, in order that it may well discover different pages. To conduct an on-page directions analysis at scale, site owners have to crawl their web site twice: As soon as because the Google Smartphone Crawler or with a cell consumer agent, and as soon as as Googlebot (for desktop) or with a desktop consumer agent. You should use any of the cloud based mostly or regionally hosted crawlers (EX: ScreamingFrog, SiteBulb, DeepCrawl, Ryte, OnCrawl, and so forth.). The user-agent settings are a part of the crawl settings or generally a part of the Superior Settings in some crawlers. In Screaming Frog, merely use the Configuration drop-down in the principle nav, and click on on ‘Person-Agent’ to see the modal under. Each cell and desktop crawlers are highlighted under. You possibly can solely select one after the other, so you’ll crawl as soon as with every Person Agent (aka: as soon as as a cell crawler and as soon as as a desktop crawler).
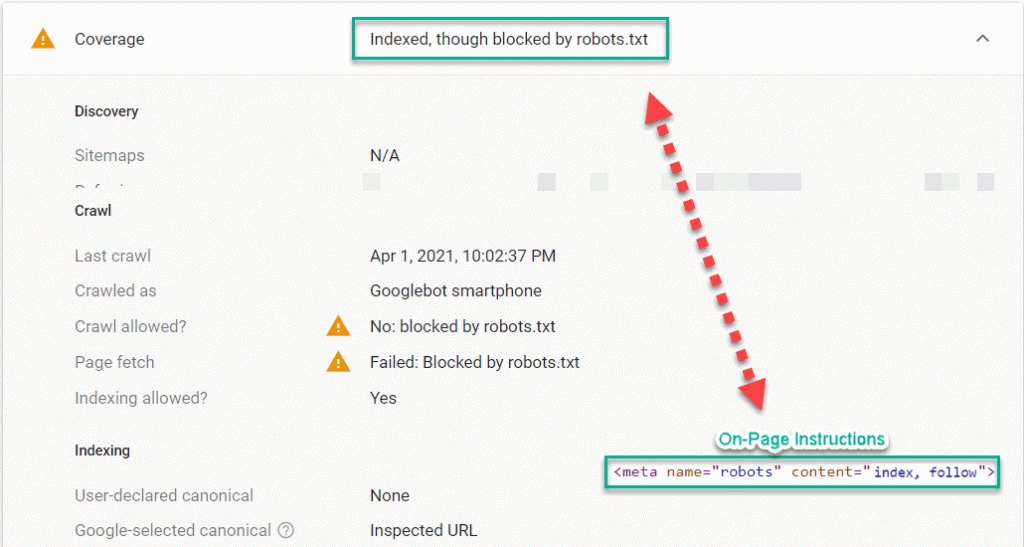
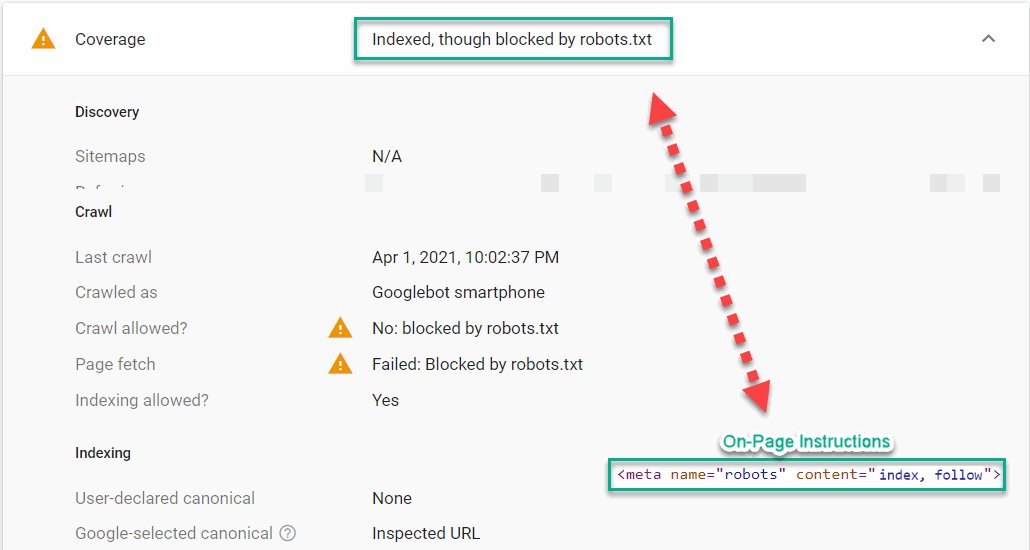
- Audit for blocked pages: Evaluation the outcomes from the crawls to verify that there are not any pages containing ’noindex’ directions that ought to be listed and rating in Google. Then, do the other and examine that the entire pages that may be listed and rating in Google are both marked with ‘index,observe’ or nothing in any respect. Be sure that all of the pages that you simply enable Google to index could be a helpful touchdown web page for a consumer in line with your small business technique. You probably have a high-number of low-value pages which can be out there to index, it may deliver down the general rating potential of the complete web site. And eventually, just be sure you aren’t blocking any pages within the Robots.txt that you simply enable to be crawled by together with ‘index,observe’ or nothing in any respect on the web page. In case of blending indicators between Robots.txt and on-page robots directions, we are likely to see issues like the instance under. We examined a web page in Google Search Console Inspection Software and located {that a} web page is ‘listed, although blocked by robots.txt’ as a result of the on-page directions are conflicting with the robots.txt and the on-page directions take precedence.
- Evaluate Cellular vs Desktop On-Web page Directions: Evaluate the crawls to verify the on-page robots directions match between cell and desktop:
- In case you are utilizing Responsive Design this shouldn’t be an issue, except parts of the Head Tag are being dynamically populated with JavaScript or Tag Supervisor. Typically that may introduce variations between the desktop and cell renderings of the web page.
- In case your CMS creates two totally different variations of the web page for the cell and desktop rendering, in what is usually known as ‘Adaptive Design’, ‘Adaptive-Responsive’ or ‘Selective Serving’, you will need to be sure the on-page robotic directions which can be generated by the system match between cell and desktop.
- If the <head> tag is ever modified or injected by JavaScript, that you must be sure the JavaScript will not be rewriting/eradicating the instruction on one or the opposite model(s) of the web page.
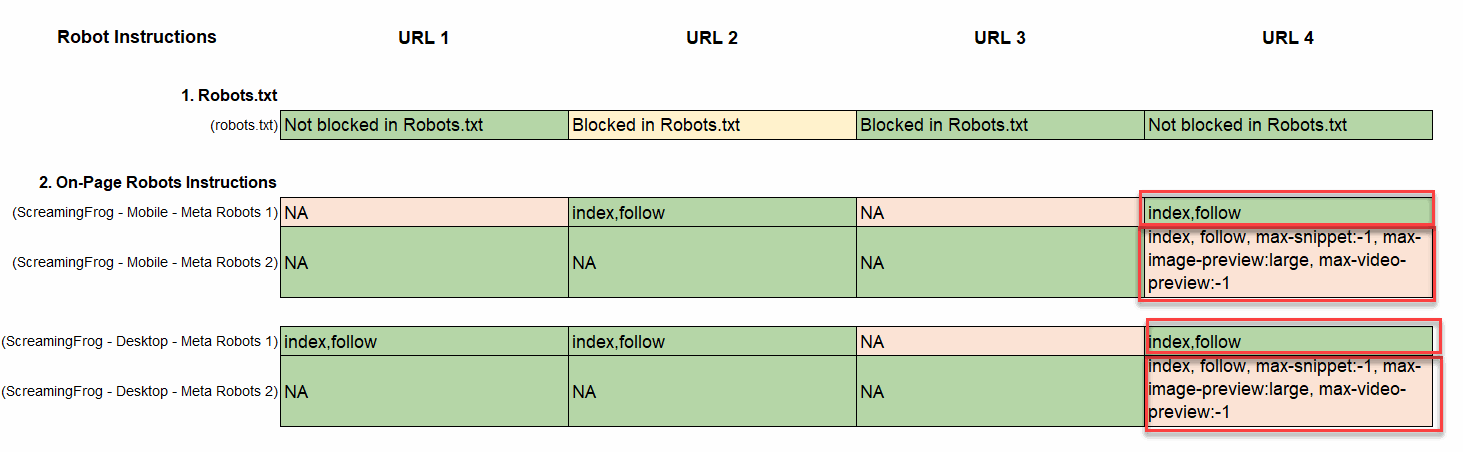
- Within the instance under, you may see that the Robots on-page directions are lacking on cell however are current on desktop.
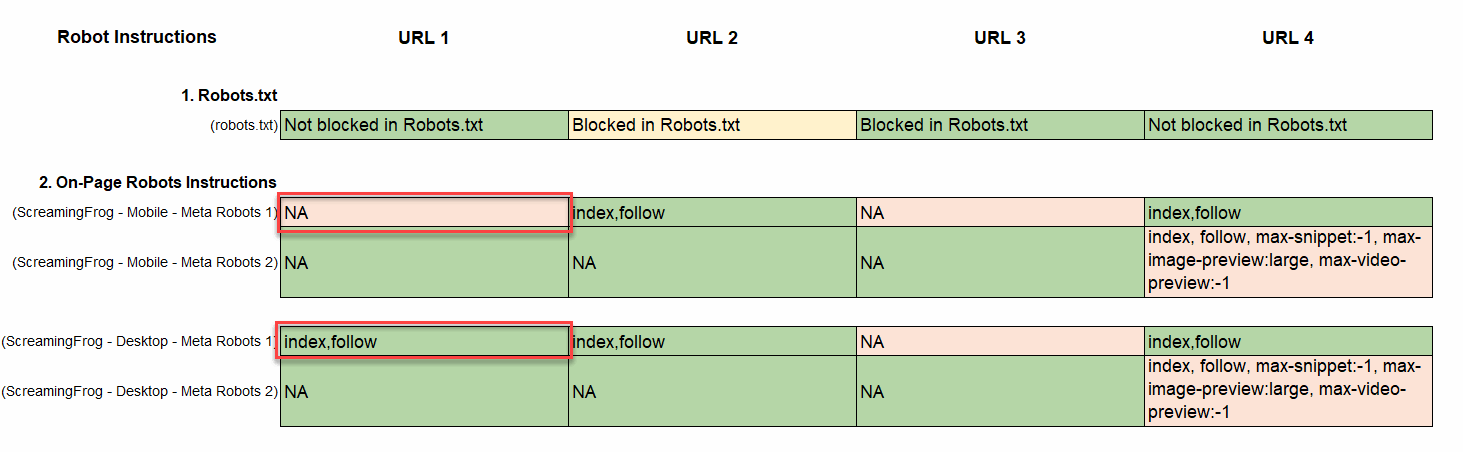
- Evaluate Robots.txt and Robotic On-Web page Instruction: Notice that if the robots.txt and on-page robotic directions don’t match, then the on-page robotic directions take precedence and Google will most likely index pages within the robots.txt file; even these with ‘Disallow: /example-page/’ in the event that they comprise <meta title=”robots” content material=”index” /> on the web page. Within the instance, you may see that the web page is blocked by Robotic.txt however it comprises index on-page directions. That is an instance of why many site owners see “Listed, although blocked my Robots.txt in Google Search Console.
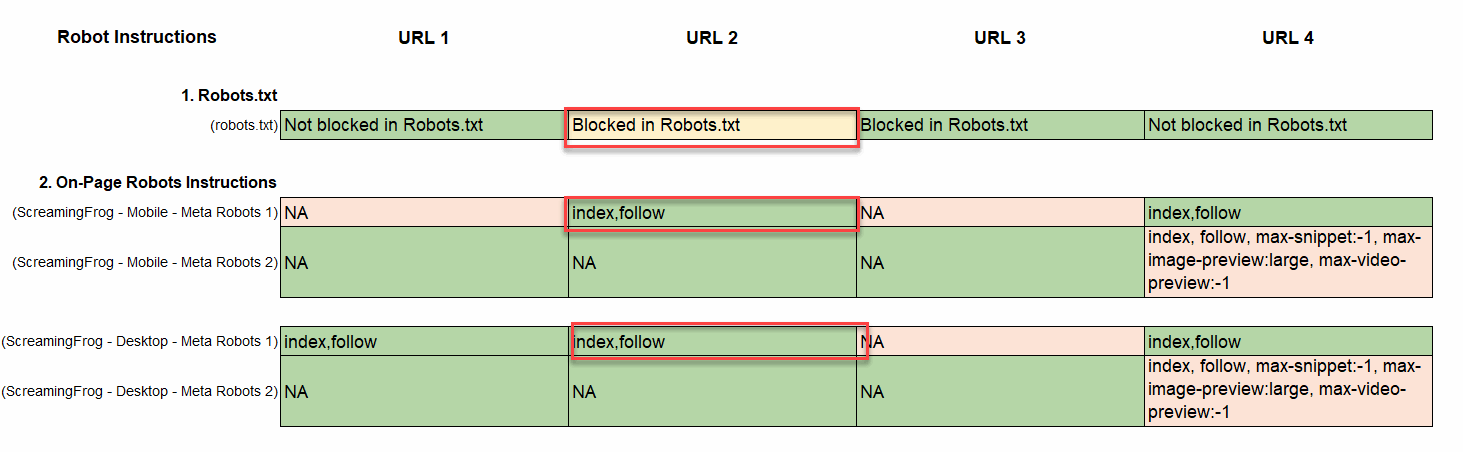
- Establish Lacking On-Web page Robotic Instruction: Crawling and indexing is the default habits for all crawlers. Within the circumstances when web page templates don’t comprise any on-page meta robots directions, Google will apply ‘index,observe’ on-page crawling and indexing directions by default. This shouldn’t be a priority so long as you need these pages listed. If that you must block the major search engines from rating sure pages, you would want so as to add a noindex rule with an on-page, ‘noindex’ tag within the head tag of the HTML, like this: <meta title=”robots” content material=”noindex” />, within the <head> tag of the HTML supply file. On this instance, The robots.txt blockers the web page from indexing however we’re lacking on-page directions for each, cell and desktop. The lacking directions wouldn’t be a priority if we would like the web page listed, however on this case it’s extremely doubtless that Google will index the web page though we’re blocking the web page with the Robots.txt.
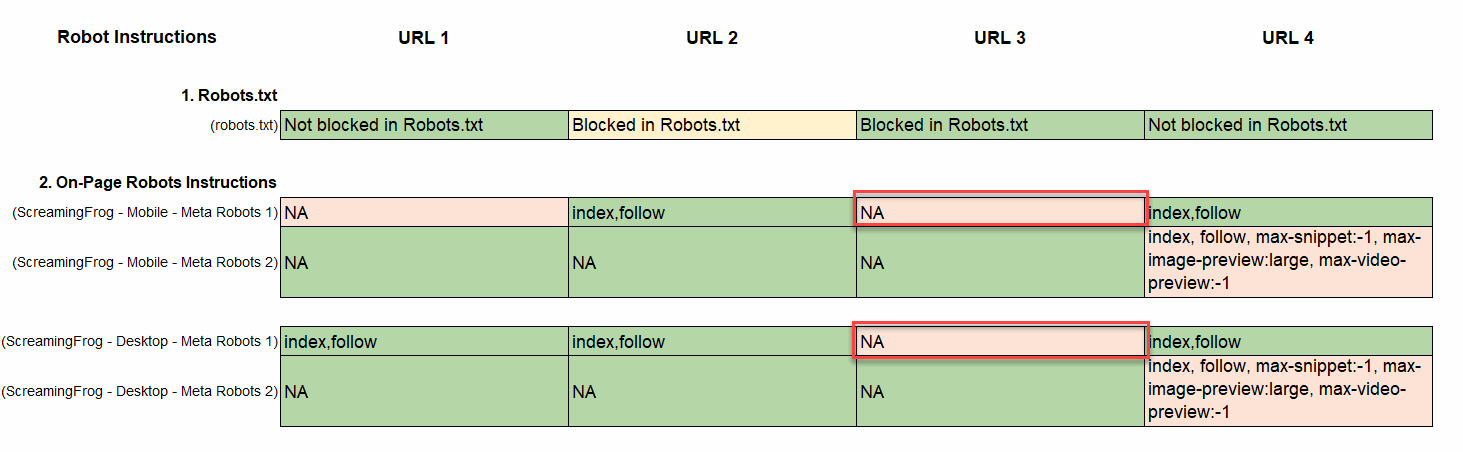
- Establish Duplicate On-Web page Robotic Directions: Ideally, a web page would solely have one set of on-page meta robots directions. Nonetheless, now we have often encountered pages with a number of on-page directions. It is a main concern as a result of if they aren’t matching, then it may well ship complicated indicators to Google. The much less correct or much less optimum model of the tag ought to be eliminated. Within the instance under you may see that the web page comprises 2 units of on-page directions. It is a huge concern when these directions are conflicting.
{kind=link}
Conclusion
Robots directions are important for web optimization as a result of they permit site owners to handle and assist with indexability of their web sites. Robots.txt file and On-Web page Robots Directions (aka: robots meta tags) are two methods of telling search engine crawlers to index or ignore URLs in your web site. Understanding the directives for each web page of your web site helps you and Google to know the accessibility & prioritization of the content material in your web site. As a Finest Observe, be certain that your Robots.txt file and On-Web page Robots Directions are given matching cell and desktop directives to Google and different crawlers by auditing for mismatches recurrently.
Full Listing of Technical web optimization Articles:
- How you can Uncover & Handle Spherical Journey Requests
- How Matching Cellular vs. Desktop Web page Property can Enhance Your web optimization
- How you can Establish Unused CSS or JavaScript on a Web page
- How you can Optimize Robotic Directions for Technical web optimization
- How you can Use Sitemaps to Assist web optimization