

{kind=link}
Apache Spark Structured Streaming is the main open supply stream processing platform. Additionally it is the core know-how that powers streaming on the Databricks Lakehouse Platform and gives a unified API for batch and stream processing. Because the adoption of streaming is rising quickly, various functions need to make the most of it for actual time determination making. A few of these functions, particularly these operational in nature, demand decrease latency. Whereas Spark’s design allows excessive throughput and ease-of-use at a decrease value, it has not been optimized for sub-second latency.
On this weblog, we are going to concentrate on the enhancements we have now made round offset administration to decrease the inherent processing latency of Structured Streaming. These enhancements primarily goal operational use circumstances comparable to actual time monitoring and alerting which can be easy and stateless.
In depth analysis of those enhancements signifies that the latency has improved by 68-75% – or as a lot as 3X – from 700-900 ms to 150-250 ms for throughputs of 100K occasions/sec, 500K occasions/sec and 1M occasions/sec. Structured Streaming can now obtain latencies decrease than 250 ms, satisfying SLA necessities for a big share of operational workloads.
This text assumes that the reader has a primary understanding of Spark Structured Streaming. Discuss with the next documentation to study extra:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/newest/structured-streaming-programming-guide.html
Motivation
Apache Spark Structured Streaming is a distributed stream processing engine constructed on high of the Apache Spark SQL engine. It gives an API that enables builders to course of information streams by writing streaming queries in the identical method as batch queries, making it simpler to purpose about and check streaming functions. In accordance with Maven downloads, Structured Streaming is probably the most broadly used open supply distributed streaming engine at this time. One of many fundamental causes for its recognition is efficiency – excessive throughput at a decrease value with an end-to-end latency below a couple of seconds. Structured Streaming provides customers the pliability to steadiness the tradeoff between throughput, value and latency.
Because the adoption of streaming grows quickly within the enterprise, there’s a need to allow a various set of functions to make use of streaming information structure. In our conversations with many shoppers, we have now encountered use circumstances that require constant sub-second latency. Such low latency use circumstances come up from functions like operational alerting and actual time monitoring, a.ok.a “operational workloads.” As a way to accommodate these workloads into Structured Streaming, in 2022 we launched a efficiency enchancment initiative below Undertaking Lightspeed. This initiative recognized potential areas and strategies that can be utilized to enhance processing latency. On this weblog, we define one such space for enchancment intimately – offset administration for progress monitoring and the way it achieves sub-second latency for operational workloads.
What are Operational Workloads?
Streaming workloads may be broadly categorized into analytical workloads and operational workloads. Determine 1 illustrates each analytical and operational workloads. Analytical workloads usually ingest, rework, course of and analyze information in actual time and write the outcomes into Delta Lake backed by object storage like AWS S3, Azure Information Lake Gen2 and Google Cloud Storage. These outcomes are consumed by downstream information warehousing engines and visualization instruments.
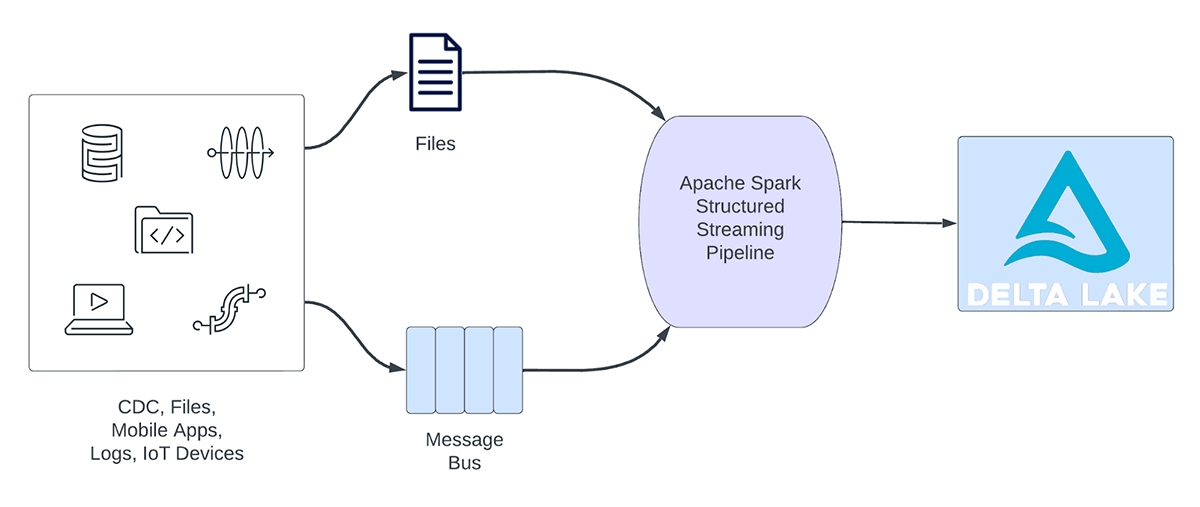
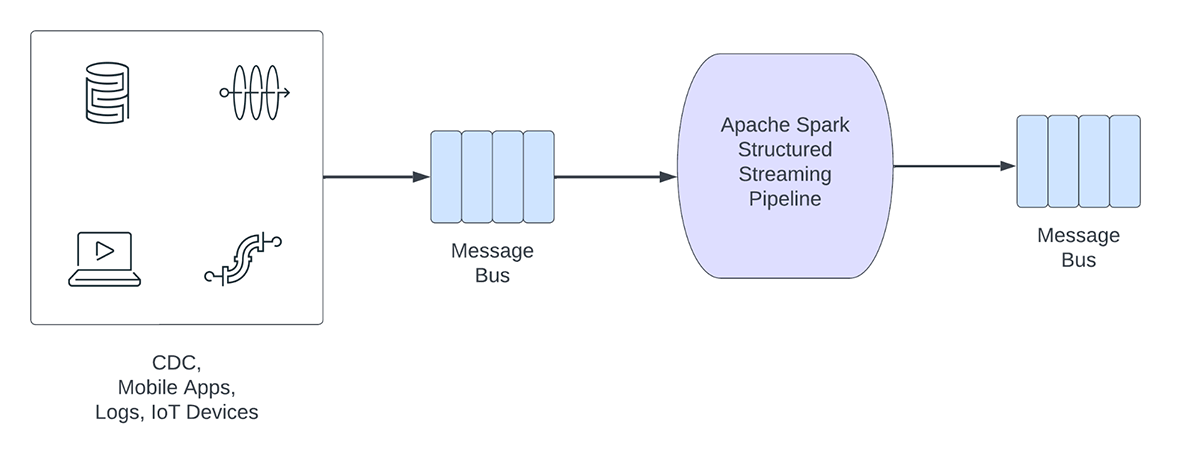
Determine 1. Analytical vs Operational Workloads
Some examples of analytical workloads embrace:
- Buyer Conduct Evaluation: A advertising and marketing agency might use streaming analytics to research buyer habits in real-time. By processing clickstream information, social media feeds, and different sources of data, the system can detect patterns and preferences that can be utilized to focus on clients extra successfully.
- Sentiment Evaluation: An organization would possibly use streaming information from its social media accounts to research buyer sentiment in actual time. For instance, the corporate would possibly search for clients who’re expressing optimistic or destructive sentiment in regards to the firm’s services or products.
- IoT Analytics: A wise metropolis might use streaming analytics to observe visitors circulate, air high quality, and different metrics in real-time. By processing information from sensors embedded all through the town, the system can detect developments and make choices about visitors patterns or environmental insurance policies.
Then again, operational workloads, ingest and course of information in actual time and routinely set off a enterprise course of. Some examples of such workloads embrace:
- Cybersecurity: An organization would possibly use streaming information from its community to observe for safety or efficiency issues. For instance, the corporate would possibly search for spikes in visitors or for unauthorized entry to networks and ship an alert to the safety division.
- Personally Identifiable Info Leaks: An organization would possibly monitor the microservice logs, parse and detect if any personally identifiable info (PII) is being leaked and whether it is, inform by e-mail the proprietor of the microservice.
- Elevator Dispatch: An organization would possibly use the streaming information from the elevator to detect when an elevator alarm button is activated. If activated, it would search for extra elevator info to boost the information and ship a notification to safety personnel.
- Proactive Upkeep: Utilizing the streaming information from an influence generator monitor the temperature and when it exceeds a sure threshold inform the supervisor.
Operational streaming pipelines share the next traits:
- Latency expectations are normally sub-second
- The pipelines learn from a message bus
- The pipelines normally do easy computation with both information transformation or information enrichment
- The pipelines write to a message bus like Apache Kafka or Apache Pulsar or quick key worth shops like Apache Cassandra or Redis for downstream integration to enterprise course of
For these use circumstances, after we profiled Structured Streaming, we recognized that the offset administration to trace the progress of micro-batches consumes substantial time. Within the subsequent part, allow us to overview the present offset administration and description how we improved in subsequent sections.
What’s Offset Administration?
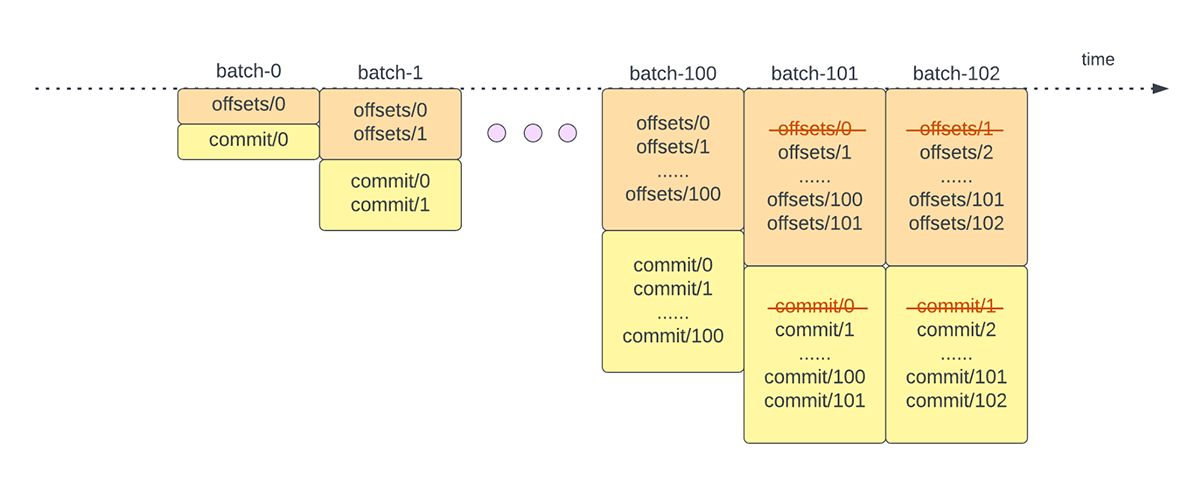
To trace the progress of as much as which level the information has been processed, Spark Structured Streaming depends on persisting and managing offsets that are used as progress indicators. Sometimes, an offset is concretely outlined by the supply connector as totally different techniques have alternative ways to signify progress or places in information. For instance, a concrete implementation of an offset may be the road quantity in a file to point how far the information within the file has been processed. Sturdy logs (as depicted in Determine 2) are used to retailer these offset and mark completion of micro-batches.
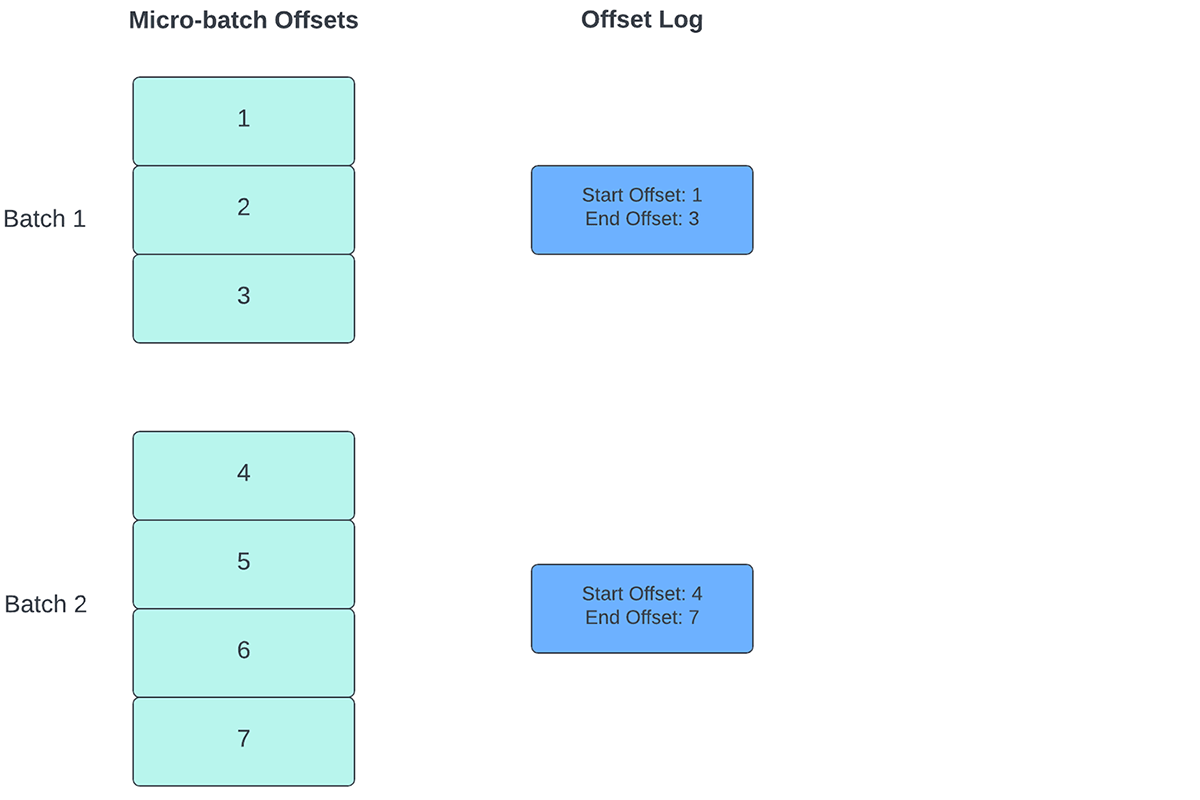
In Structured Streaming, information is processed in models of micro-batches. There are two offset administration operations performed for every micro-batch. One at the start of each micro-batch and one on the finish.
- In the beginning of each micro-batch (earlier than any information processing really begins), an offset is calculated based mostly on what new information may be learn from the goal system. This offset is endured to a sturdy log referred to as the “offsetLog” within the checkpoint listing. This offset is used to calculate the vary of information that can be processed in “this” micro-batch.
- On the finish of each micro-batch, an entry is endured within the sturdy log referred to as the “commitLog” to point that “this” micro-batch has been efficiently processed.
Determine 3 under depicts the present offset administration operations that happen.
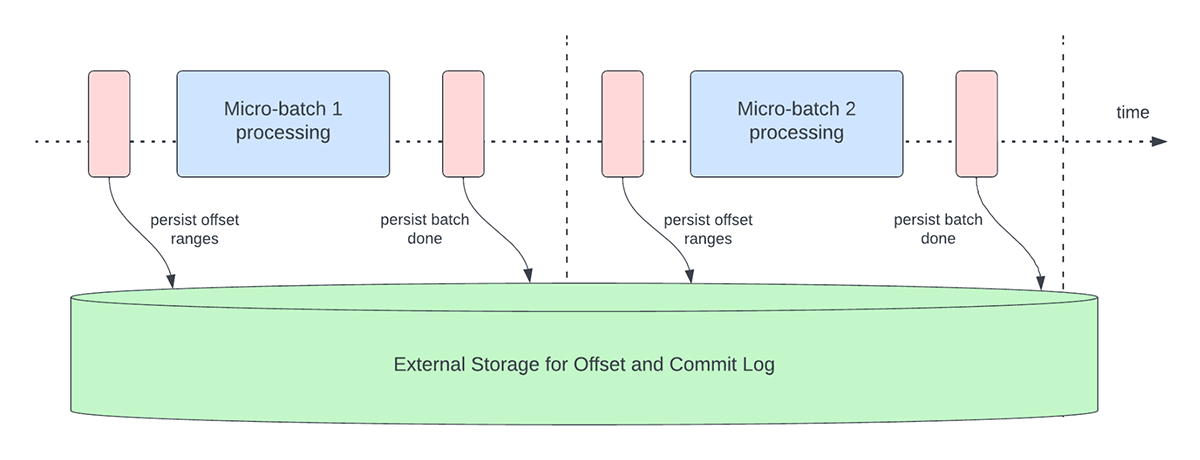
One other offset administration operation is carried out on the finish of each micro-batch. This operation is a clear up operation to delete / truncate outdated and pointless entries from each the offsetLog and commitLog in order that these logs do not develop in an unbounded style.
These offset administration operations are carried out on the essential path and inline with the precise processing of the information. Which means that the length of those operations immediately impacts processing latency and no information processing can happen till these operations are full. This immediately impacts cluster utilization as nicely.
By way of our benchmarking and efficiency profiling efforts, we have now recognized these offset administration operations can take up a majority of the processing time particularly for stateless single state pipelines which can be usually used within the operation alerting and real-time monitoring use circumstances.
Efficiency Enhancements in Structured Streaming
Asynchronous Progress Monitoring
This function was created to deal with the latency overhead of persisting offsets for progress monitoring functions. This function, when enabled, will permit Structured Streaming pipelines to checkpoint progress, i.e. replace the offsetLog and commitLog, asynchronously and in parallel to the precise information processing inside a micro-batch. In different phrases, the precise information processing is not going to be blocked by these offset administration operations which is able to considerably enhance the latency of functions. Determine 5 under depicts this new habits for offset administration.
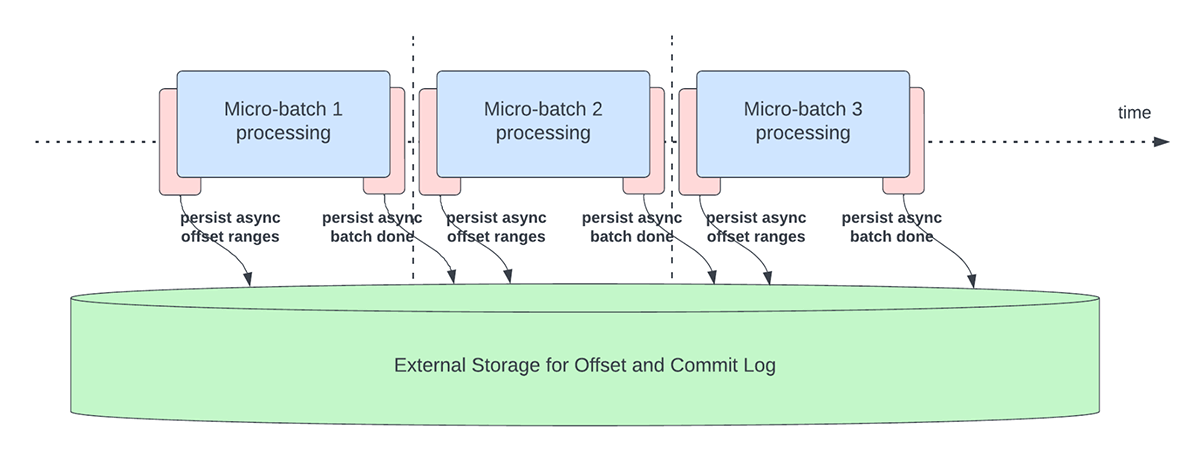
Along side asynchronously performing updates, customers can configure the frequency at which the progress is checkpointed. This can be useful for eventualities through which offset administration operations happen at a better price than they are often processed. This occurs in pipelines when the time spent really processing information is considerably much less in comparison with these offset administration operations. In such eventualities, an ever growing backlog of offset administration operations will happen. To stem this rising backlog, information processing must be blocked or slowed down which is able to primarily revert the processing habits to being the identical as if these offset administration operations had been executed inline with the information processing. A person will usually not must configure or set the checkpoint frequency as an satisfactory default worth can be set. You will need to observe that failure restoration time will improve with the rise in checkpoint interval time. In case of failure, a pipeline has to reprocess all the information earlier than the earlier profitable checkpoint. Customers can contemplate this trade-off between decrease latency throughout common processing and restoration time in case of failure.
Following configurations are launched to allow and configure this function:
asyncProgressTrackingEnabled - allow or disable asynchronous progress monitoringasyncProgressCheckpointingInterval - the interval through which we commit offsets and completion commits
Following code pattern illustrates how one can allow this function:
val stream = spark.readStream
.format("kafka")
.possibility("kafka.bootstrap.servers", "host1:port1,host2:port2")
.possibility("subscribe", "in")
.load()
val question = stream.writeStream
.format("kafka")
.possibility("matter", "out")
.possibility("checkpointLocation", "/tmp/checkpoint")
.possibility("asyncProgressTrackingEnabled", "true")
.begin()
Be aware that this function is not going to work with Set off.as soon as or Set off.availableNow as these triggers execute pipelines in handbook/scheduled style. Subsequently, asynchronous progress monitoring is not going to be related. Question will fail whether it is submitted utilizing any of the aforementioned triggers.
Applicability and Limitations
There are a few limitations within the present model(s) that may change as we evolve the function:
- At the moment, asynchronous progress monitoring is barely supported in stateless pipelines utilizing Kafka Sink.
- Precisely as soon as end-to-end processing is not going to be supported with this asynchronous progress monitoring as a result of offset ranges for a batch may be modified in case of failure. Nevertheless, many sinks, such because the Kafka sink, solely assist at-least as soon as ensures, so this is probably not a brand new limitation.
Asynchronous Log Purging
This function was created to deal with the latency overhead of the log cleanups that had been performed in line inside a micro-batch. By making this log cleanup/purge operation asynchronous and carried out within the background, we are able to take away the latency overhead this operation will incur on precise information processing. Additionally, these purges don’t have to be performed with each micro-batch and might happen on a extra relaxed schedule.
Be aware that this function / enchancment doesn’t have any limitations on what sort of pipelines or workloads can use this, thus this function can be enabled within the background by default for all Structured Streaming pipelines.
Benchmarks
As a way to perceive the efficiency of async progress monitoring and async log purging, we created a couple of benchmarks. Our aim with the benchmarks is to grasp the distinction in efficiency that the improved offset administration gives in an end-to-end streaming pipeline. The benchmarks are divided into two classes:
- Charge Supply to Stat Sink – On this benchmark, we used a primary, stateless, stats-collecting supply and sink which is beneficial in figuring out the distinction in core engine efficiency with none exterior dependencies.
- Kafka Supply to Kafka Sink – For this benchmark, we transfer information from a Kafka supply to Kafka sink. That is akin to a real-world state of affairs to see what the distinction could be in a manufacturing state of affairs.
For each these benchmarks, we measured the top to finish latency (fiftieth percentile, 99th percentile) at totally different information enter charges (100K occasions/sec, 500K occasions/sec, 1M occasions/sec).
Benchmark Methodology
The primary methodology was to generate information from a supply at a specific fixed throughput. The generated information comprise details about when the information had been created. On the sink facet, we use the Apache DataSketches library to gather the distinction between the time the sink processes the file and the time that it was created in every batch. That is used to calculate the latency. We used the identical cluster with the identical variety of nodes for all experiments.
Be aware: For the Kafka benchmark, we put apart some nodes of a cluster for operating Kafka and producing the information for feeding to Kafka. We calculate the latency of a file solely after the file has been efficiently printed into Kafka (on the sink)
Charge Supply to Stat Sink Benchmark
For this benchmark, we used a Spark cluster of seven employee nodes (i3.2xlarge – 4 cores, 61 GiB reminiscence) utilizing the Databricks runtime (11.3). We measured the top to finish latency for the next eventualities to quantify the contribution of every enchancment.
- Present Structured Streaming – that is the baseline latency with none of the aforementioned enhancements
- Async Log Purge – this measures the latency after making use of asynchronous log purging solely
- Async Progress – this measures the latency after making use of asynchronous progress monitoring
- Async Progress + Async Log Purge – this measures the latency after making use of each the enhancements
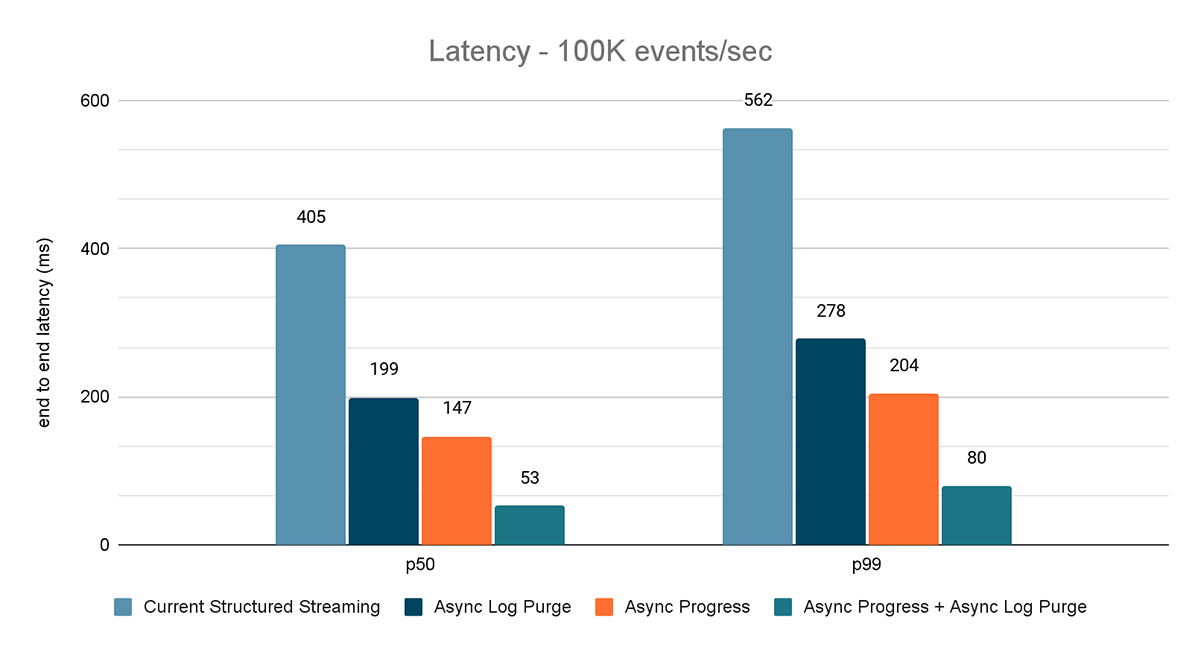
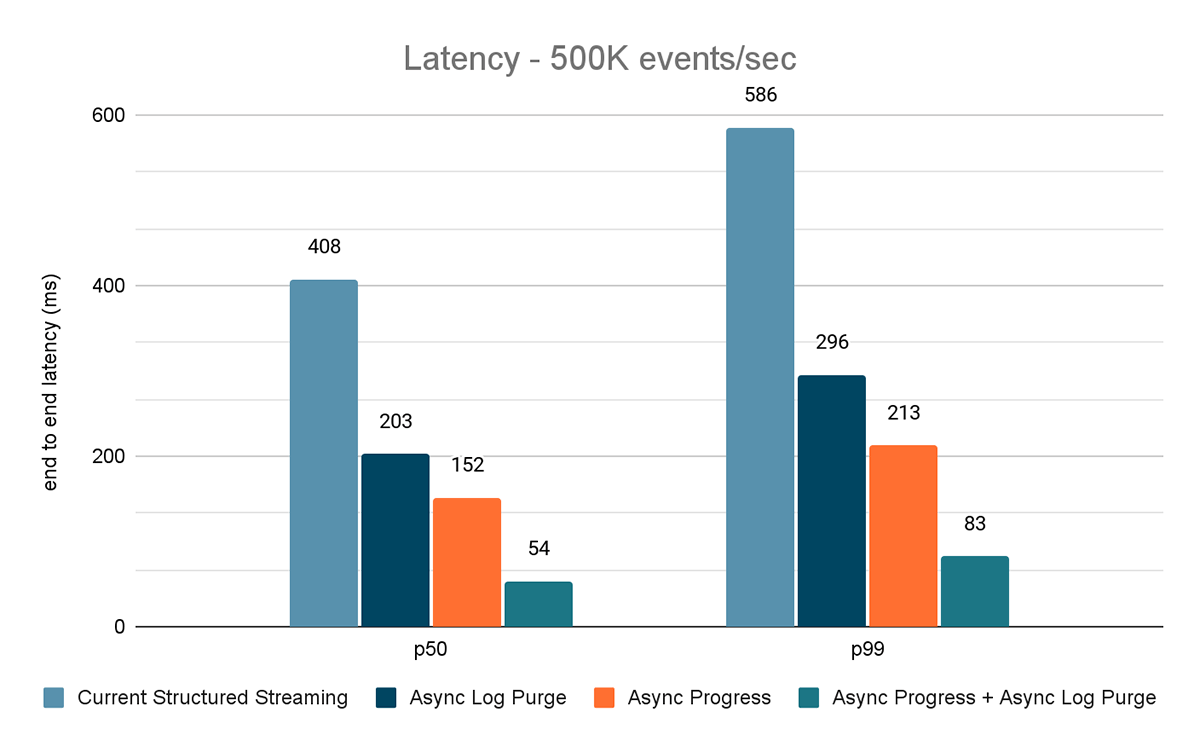
The outcomes of those experiments are proven in Figures 6, 7 and eight. As you may see, async log purging persistently reduces the latency roughly by 50%. Equally, async progress monitoring alone improves latency by roughly 65%. Mixed collectively, the latency reduces by 85-86% and the latency goes under 100 ms.
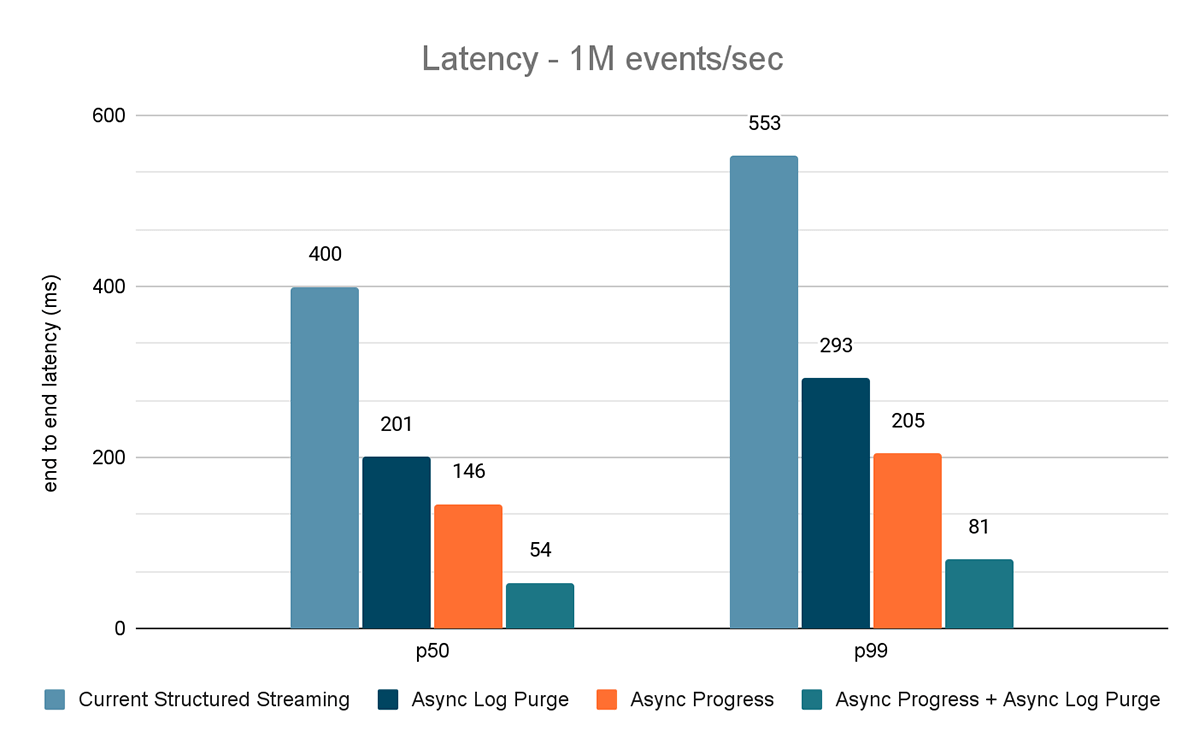
Kafka Supply to Kafka Sink Benchmark
For the Kafka benchmarks, we used a Spark cluster of 5 employee nodes (i3.2xlarge – 4 cores, 61 GiB reminiscence), a separate cluster of three nodes to run Kafka and a further 2 nodes to generate information added to the Kafka supply. Our Kafka matter has 40 partitions and a replication issue of three.
The information generator publishes the information right into a Kafka matter and the structured streaming pipeline consumes information and republishes into one other Kafka matter. The outcomes of the efficiency analysis are proven in Figures 9, 10 and 11. As one can see, after making use of async progress and async log purging, the latency reduces by 65-75% or 3-3.5X throughout totally different throughputs.
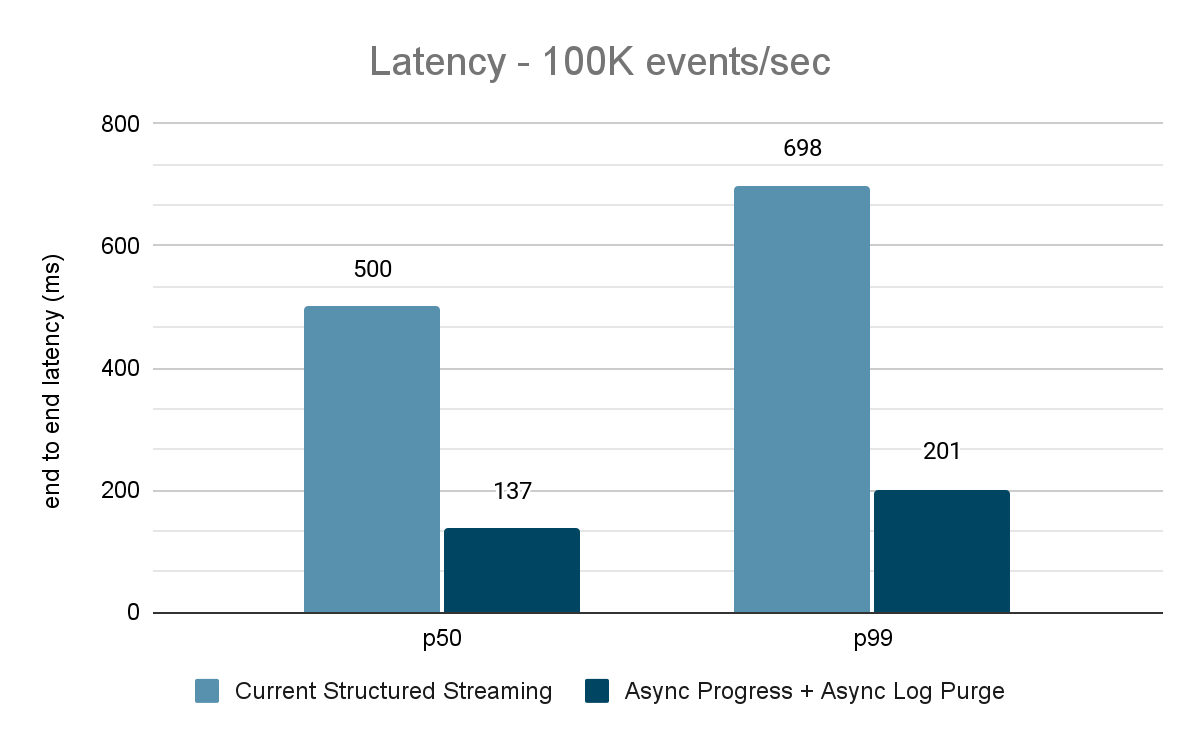
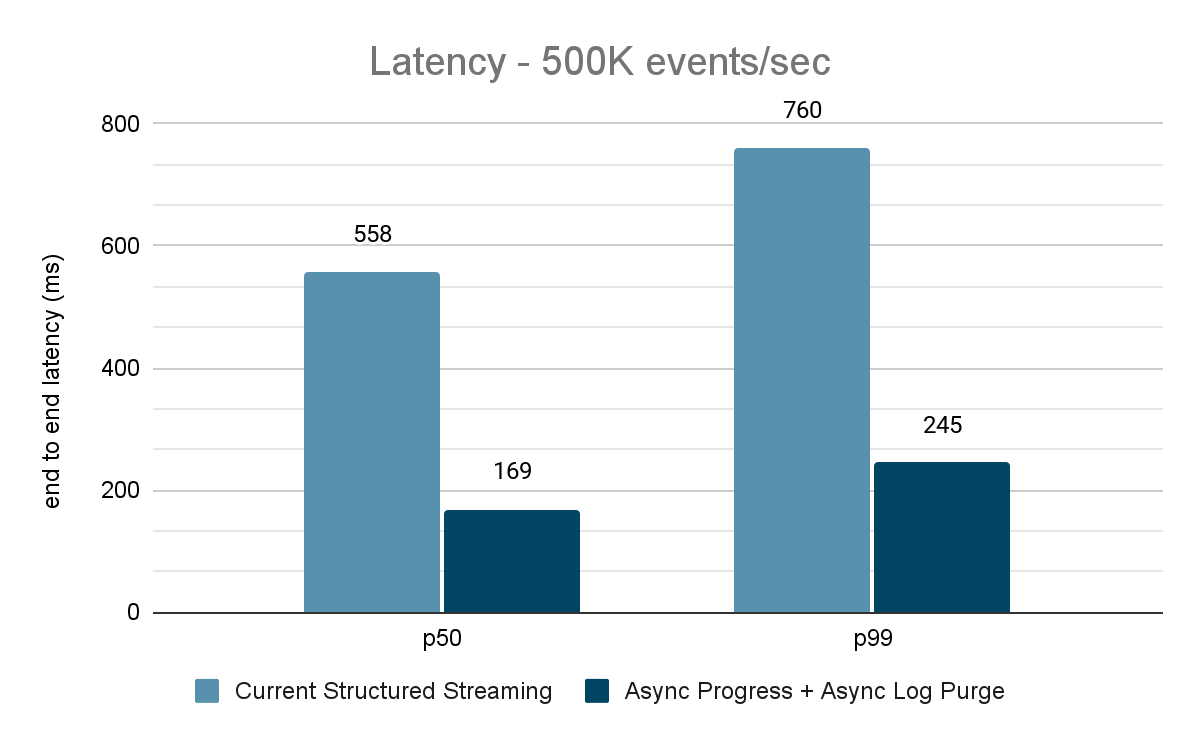
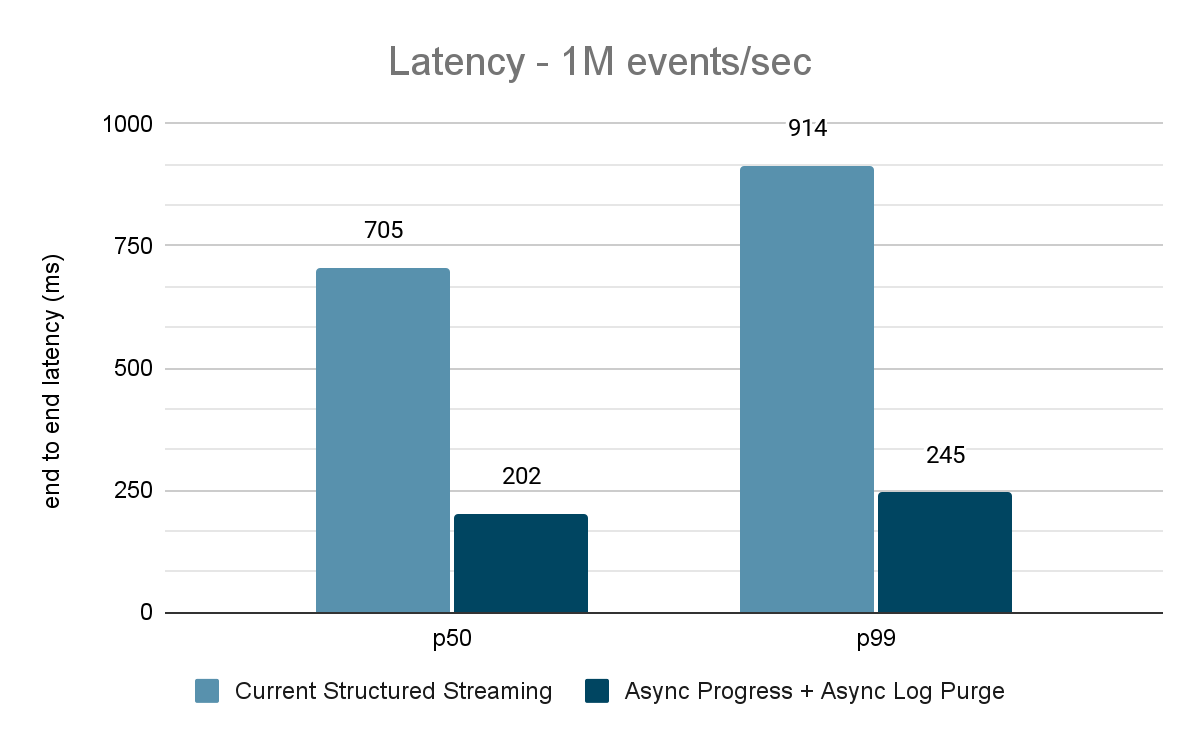
Abstract of Efficiency Outcomes
With the brand new asynchronous progress monitoring and asynchronous log purge, we are able to see that each configs cut back latency as a lot as 3X. Working collectively, latency is enormously decreased throughout all throughputs. The charts additionally present that the period of time saved is normally a relentless period of time (200 – 250 ms for every config) and collectively they will shave off round 500 ms throughout the board (leaving sufficient time for batch planning and question processing).
Availability
These efficiency enhancements can be found in Databricks Lakehouse Platform from DBR 11.3 onwards. Async log purging is enabled by default in DBR 11.3 and subsequent releases. Moreover, these enhancements have been contributed to Open Supply Spark and is accessible from Apache Spark 3.4 onwards.
Future Work
There are at present some limitations to the kinds of workloads and sinks supported by the asynchronous progress monitoring function. We can be trying into supporting extra kinds of workloads with this function sooner or later.
That is solely the start of the predictable low latency options we’re constructing in Structured Streaming as a part of Undertaking Lightspeed. As well as, we are going to proceed to benchmark and profile Structured Streaming to seek out extra areas of enchancment. Keep tuned!
Be part of us on the Information and AI Summit in San Francisco, June 26-29 to study extra about Undertaking Lightspeed and information streaming on the Databricks Lakehouse Platform.