

{kind=link}

(ra2 studio/Shutterstock)
The intersection of huge language fashions and graph databases is one which’s wealthy with prospects. The oldsters at property graph database maker Neo4j at the moment took a primary step in realizing these prospects for its prospects by saying the potential to retailer vector embeddings, enabling it to perform as long-term reminiscence for an LLM comparable to OpenAI’s GPT.
Whereas graph databases and huge language fashions (LLMs) reside at separate ends of the information spectrum, they bear some similarity to one another when it comes to how people work together with them and use them as information bases.
A property graph database, comparable to Neo4j’s, is an excessive instance of a structured information retailer. The node-and-edge graph construction excels at serving to customers to discover information about entities (outlined as nodes) and their relationships (outlined as edges) to different entities. At runtime, a property graph can discover solutions to questions by shortly traversing pre-defined connections to different nodes, which is extra environment friendly than, say, working a SQL take part a relational database.
An LLM, however, is an excessive instance of unstructured information retailer. On the core of an LLM is a neural community that’s been educated totally on a large quantity of human-generated textual content. At runtime, an LLM solutions questions by producing sentences one phrase at a time in a manner that greatest matches the phrases it encountered throughout coaching.
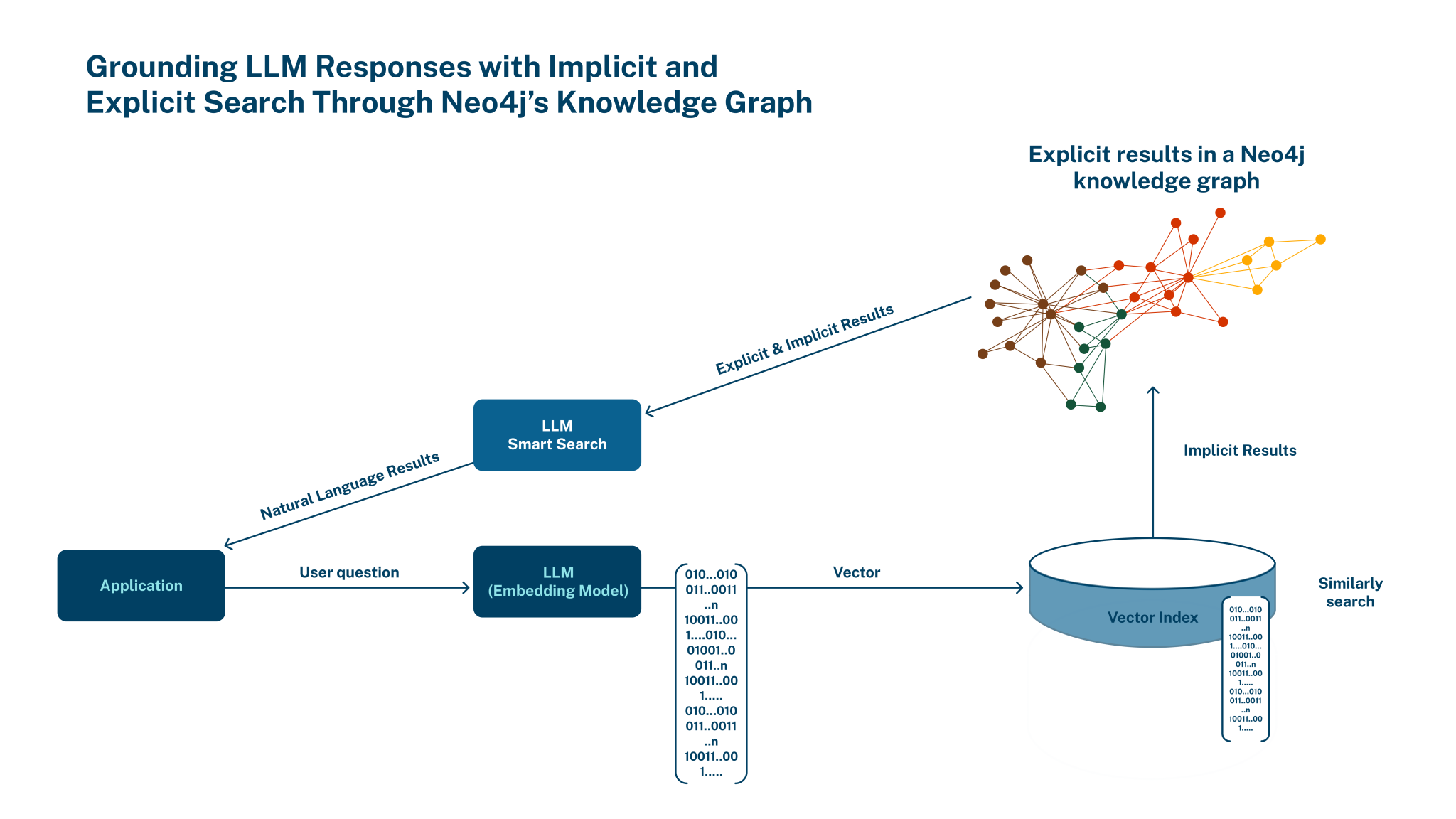
Picture supply: Neo4j
Whereas the information within the graph database is contained within the connections between labeled nodes, the information within the LLM is contained within the human-generated textual content. So whereas graphs and LLMs could also be known as upon to reply comparable knowledge-related questions, they work in solely other ways.
The oldsters at Neo acknowledged the potential advantages from attacking some of these information challenges from either side of the structured information spectrum. “We see worth in combining the implicit relationships uncovered by vectors with the specific and factual relationships and patterns illuminated by graph,” Emil Eifrem, co-founder and CEO of Neo4j, mentioned in a press launch at the moment.
Neo4j Chief Scientist Jim Webber sees three patterns for the way prospects can combine graph databases and LLMs.
The primary is utilizing the LLM as a helpful interface to work together together with your graph database. The second is making a graph database from the LLM. The third is coaching the LLM straight from the graph database. “In the intervening time, these three instances appear very prevalent,” Webber says.
How can these integrations work in the actual world? For the primary sort, Webber used an instance of the question “Present me a film from my favourite actor.” As an alternative of prompting the LLM with a load of textual content explaining who your favourite actor is, the LLM would generate a question for the graph database, the place the reply “Michael Douglas” will be simply deduced from the construction of the graph, thereby streamlining the interplay.
For the second use case, Weber shared a number of the work at the moment being completed by BioCypher. The group is utilizing LLMs to construct a mannequin of drug interactions based mostly on massive corpuses of information. It’s then utilizing the probabilistic connections within the LLM to construct a graph database that may be question in a extra deterministic method.
BioCypher is utilizing LLMs as a result of it “does the pure language exhausting stuff,” Webber says. “However what they’ll’t do is then question that giant language mannequin for perception or solutions, as a result of it’s opaque and it would hallucinate, and so they don’t like that. As a result of within the regulatory atmosphere saying ‘As a result of this field of randomness advised us so’ is just not adequate.”
Webber shared an instance of the final use case–coaching a LLM based mostly on curated information within the information graph. Weber says he lately met with the proprietor of an Indonesian firm that’s constructing customized chatbots based mostly on information within the Neo4j information graph.![]()
“You’ll be able to ask it query concerning the newest Premiere League soccer season, and it might don’t know what you’re speaking about,” Webber says the proprietor advised him. “However in case you ask a query about my merchandise, it solutions actually exactly, and my buyer satisfaction goes by way of the roof.
In a weblog publish at the moment, Neo4j Chief Product Officer Sudhir Hasbe says the combination of LLMs and graph will assist prospects in enhancing fraud detection, offering higher and extra personalised suggestions, and for locating new solutions. “…[V]ector search gives a easy strategy for shortly discovering contextually associated data and, in flip, helps groups uncover hidden relationships,” he writes. “Grounding LLMs with a Neo4j information graph improves accuracy, context, and explainability by bringing factual responses (specific) and contextually related (implicit) responses to the LLM.”
There’s a “yin and yang” to information graphs and LLMs, Webber says. In some conditions, the LLM are the best instrument for the job. However in different instances–comparable to the place extra transparency and determinism is required–then shifting up the structured information stack a full-blown information graph goes to be a greater resolution.
“And in the meanwhile these three instances appear very prevalent,” he says. “But when we’ve got one other dialog in a single yr… actually don’t know the place that is going, which is odd for me, as a result of I’ve been round a bit in IT and I often have a superb sense for the place issues are going, however the future feels very unwritten right here with the intersection of data graphs and LLMs.”
Associated Gadgets:
The Boundless Enterprise Prospects of Generative AI
Neo4j Releases the Subsequent Technology of Its Graph Database