
{kind=link}
AI-based language evaluation has lately gone by way of a “paradigm shift” (Bommasani et al., 2021, p. 1), thanks partly to a brand new method known as transformer language mannequin (Vaswani et al., 2017, Liu et al., 2019). Corporations, together with Google, Meta, and OpenAI have launched such fashions, together with BERT, RoBERTa, and GPT, which have achieved unprecedented giant enhancements throughout most language duties equivalent to net search and sentiment evaluation. Whereas these language fashions are accessible in Python, and for typical AI duties by way of HuggingFace, the R package deal textual content makes HuggingFace and state-of-the-art transformer language fashions accessible as social scientific pipelines in R.
Introduction
We developed the textual content package deal (Kjell, Giorgi & Schwartz, 2022) with two aims in thoughts:
To function a modular answer for downloading and utilizing transformer language fashions. This, for instance, contains remodeling textual content to phrase embeddings in addition to accessing widespread language mannequin duties equivalent to textual content classification, sentiment evaluation, textual content era, query answering, translation and so forth.
To offer an end-to-end answer that’s designed for human-level analyses together with pipelines for state-of-the-art AI strategies tailor-made for predicting traits of the individual that produced the language or eliciting insights about linguistic correlates of psychological attributes.
This weblog submit exhibits easy methods to set up the textual content package deal, rework textual content to state-of-the-art contextual phrase embeddings, use language evaluation duties in addition to visualize phrases in phrase embedding house.
Set up and organising a python setting
The textual content package deal is organising a python setting to get entry to the HuggingFace language fashions. The primary time after putting in the textual content package deal you should run two capabilities: textrpp_install() and textrpp_initialize().
# Set up textual content from CRAN
set up.packages("textual content")
library(textual content)
# Set up textual content required python packages in a conda setting (with defaults)
textrpp_install()
# Initialize the put in conda setting
# save_profile = TRUE saves the settings so that you simply do not need to run textrpp_initialize() once more after restarting R
textrpp_initialize(save_profile = TRUE)See the prolonged set up information for extra info.
Rework textual content to phrase embeddings
The textEmbed() perform is used to rework textual content to phrase embeddings (numeric representations of textual content). The mannequin argument allows you to set which language mannequin to make use of from HuggingFace; in case you have not used the mannequin earlier than, it should mechanically obtain the mannequin and crucial information.
# Rework the textual content information to BERT phrase embeddings
# Notice: To run quicker, attempt one thing smaller: mannequin = 'distilroberta-base'.
word_embeddings <- textEmbed(texts = "Hey, how are you doing?",
mannequin = 'bert-base-uncased')
word_embeddings
remark(word_embeddings)The phrase embeddings can now be used for downstream duties equivalent to coaching fashions to foretell associated numeric variables (e.g., see the textTrain() and textPredict() capabilities).
(To get token and particular person layers output see the textEmbedRawLayers() perform.)
There are a lot of transformer language fashions at HuggingFace that can be utilized for numerous language mannequin duties equivalent to textual content classification, sentiment evaluation, textual content era, query answering, translation and so forth. The textual content package deal contains user-friendly capabilities to entry these.
classifications <- textClassify("Hey, how are you doing?")
classifications
remark(classifications)generated_text <- textGeneration("The that means of life is")
generated_textFor extra examples of accessible language mannequin duties, for instance, see textSum(), textQA(), textTranslate(), and textZeroShot() below Language Evaluation Duties.
Visualizing phrases within the textual content package deal is achieved in two steps: First with a perform to pre-process the info, and second to plot the phrases together with adjusting visible traits equivalent to shade and font dimension.
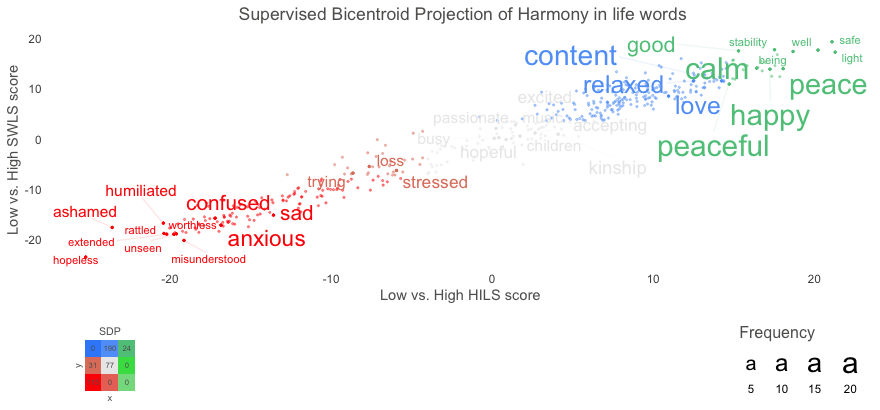
To display these two capabilities we use instance information included within the textual content package deal: Language_based_assessment_data_3_100. We present easy methods to create a two-dimensional determine with phrases that people have used to explain their concord in life, plotted in accordance with two totally different well-being questionnaires: the concord in life scale and the satisfaction with life scale. So, the x-axis exhibits phrases which are associated to low versus excessive concord in life scale scores, and the y-axis exhibits phrases associated to low versus excessive satisfaction with life scale scores.
word_embeddings_bert <- textEmbed(Language_based_assessment_data_3_100,
aggregation_from_tokens_to_word_types = "imply",
keep_token_embeddings = FALSE)
# Pre-process the info for plotting
df_for_plotting <- textProjection(Language_based_assessment_data_3_100$harmonywords,
word_embeddings_bert$textual content$harmonywords,
word_embeddings_bert$word_types,
Language_based_assessment_data_3_100$hilstotal,
Language_based_assessment_data_3_100$swlstotal
)
# Plot the info
plot_projection <- textProjectionPlot(
word_data = df_for_plotting,
y_axes = TRUE,
p_alpha = 0.05,
title_top = "Supervised Bicentroid Projection of Concord in life phrases",
x_axes_label = "Low vs. Excessive HILS rating",
y_axes_label = "Low vs. Excessive SWLS rating",
p_adjust_method = "bonferroni",
points_without_words_size = 0.4,
points_without_words_alpha = 0.4
)
plot_projection$final_plot
This submit demonstrates easy methods to perform state-of-the-art textual content evaluation in R utilizing the textual content package deal. The package deal intends to make it straightforward to entry and use transformers language fashions from HuggingFace to research pure language. We sit up for your suggestions and contributions towards making such fashions obtainable for social scientific and different purposes extra typical of R customers.
- Bommasani et al. (2021). On the alternatives and dangers of basis fashions.
- Kjell et al. (2022). The textual content package deal: An R-package for Analyzing and Visualizing Human Language Utilizing Pure Language Processing and Deep Studying.
- Liu et al (2019). Roberta: A robustly optimized bert pretraining strategy.
- Vaswaniet al (2017). Consideration is all you want. Advances in Neural Data Processing Programs, 5998–6008
Corrections
Should you see errors or need to recommend adjustments, please create a difficulty on the supply repository.
Reuse
Textual content and figures are licensed below Artistic Commons Attribution CC BY 4.0. Supply code is out there at https://github.com/OscarKjell/ai-blog, until in any other case famous. The figures which have been reused from different sources do not fall below this license and may be acknowledged by a word of their caption: “Determine from …”.
Quotation
For attribution, please cite this work as
Kjell, et al. (2022, Oct. 4). Posit AI Weblog: Introducing the textual content package deal. Retrieved from https://blogs.rstudio.com/tensorflow/posts/2022-09-29-r-text/
BibTeX quotation
@misc{kjell2022introducing,
creator = {Kjell, Oscar and Giorgi, Salvatore and Schwartz, H Andrew},
title = {Posit AI Weblog: Introducing the textual content package deal},
url = {https://blogs.rstudio.com/tensorflow/posts/2022-09-29-r-text/},
12 months = {2022}
}