

{kind=link}
The variations between machine studying and statistics
Machine studying and statistics are the 2 core disciplines for information evaluation. Each fields present the scientific background for information science and information scientists will normally have skilled in one of many two. Nevertheless, a lot has been stated in regards to the variations between the 2 disciplines, whereas there are proponents solely of 1 method. So, what are the variations?
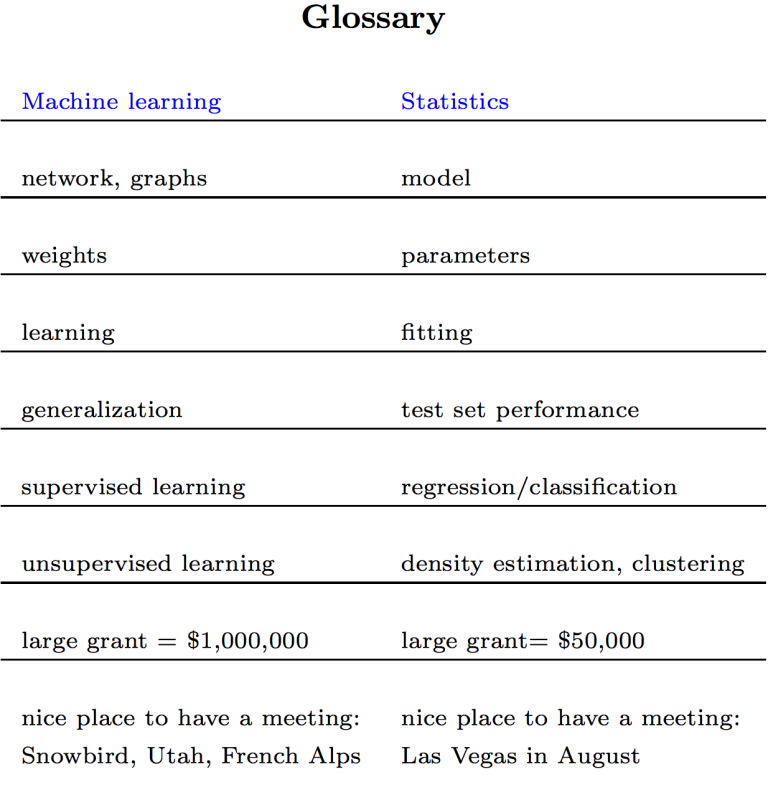
Effectively, there are two major variations. The primary one, which isn’t crucial, is terminology. An excellent comparability by the wonderful statistician – and machine studying professional –Robert Tibshiriani is reproduced right here:
The second distinction, which is key, is that machine studying is concentrated on prediction whereas statistics is concentrated on mathematical modelling. Additionally, machine studying is influenced rather a lot by the “engineering” mentality which exists in laptop science departments. It is extra essential to make one thing work, even when there may be not a transparent idea behind it.
Two totally different views on information science
So, in machine studying you’ve got algorithms comparable to neural networks that may establish non-linear patterns and interactions within the information. In statistics, alternatively, you’ve got significance testing for assessing the essential of every particular person variable.
In all probability, no-one stated it higher than Leo Breiman, the inventor of random forests, some of the profitable algorithms in information science (hyperlink to paper right here):
“There are two cultures in using statistical modeling to succeed in conclusions from information. One assumes that the information are generated by a given stochastic information mannequin. The opposite makes use of algorithmic fashions and treats the information mechanism as unknown. The statistical neighborhood has been dedicated to the just about unique use of information fashions. This dedication has led to irrelevant idea, questionable conclusions, and has saved statisticians from engaged on a wide variety of attention-grabbing present issues. Algorithmic modeling, each in idea and follow, has developed quickly in fields exterior statistics. It may be used each on giant advanced information units and as a extra correct and informative different to information modeling on smaller information units. If our aim as a subject is to make use of information to unravel issues, then we have to transfer away from unique dependence on information fashions and undertake a extra numerous set of instruments.”
 Leo Breiman
Leo Breiman
Be aware that Breiman was extra in favour of the “machine studying” mind-set (as you in all probability guessed from the summary).
Machine studying is likely to be getting extra credit score these days than statistics, primarily as a result of the abundance in information makes it straightforward to construct profitable predictive fashions. Statistics shines extra when the info is restricted and once we care about particular hypotheses.
These variations may also be attributed to the historical past of the fields. Trendy statistics got here in regards to the nineteenth century when information was sparse, so creating fashions with sturdy assumptions might counteract the absence of information, if these assumptions have been appropriate. When there’s a enormous quantity of information, nonetheless, you will get fairly good options with non-parametric strategies or different sorts of approaches. SVMs for instance take a geometrical view on studying which doesn’t embody any probabilistic pondering in any respect.
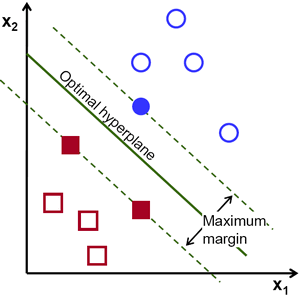 Assist Vector Machine instance
Assist Vector Machine instance
My private method is to take the perfect of each worlds and to make use of the correct software for the job. The time period information science will hopefully transfer in direction of a larger integration of each fields.
The Wikipedia defines information science as a subject that “incorporates various parts and builds on strategies and theories from many fields, together with math, statistics, information engineering, sample recognition and studying, superior computing, visualization, uncertainty modeling, information warehousing, and high-performance computing with the aim of extracting that means from information and creating information merchandise.”
So, simply pay attention to the variations between the fields and use what’s finest on your downside at hand! If you would like to be taught extra in regards to the topic and comparable subjects, such because the distinction between AI and ML, then take a look at a few of my programs, or the Tesseract Academy.
So, briefly, what’s the distinction between machine studying and statistics? In a couple of phrases, the primary distinction is within the focus that every method has. Statistics is concentrated extra on interpretability, whereas machine studying is concentrated extra on prediction. The precise method is determined by your specific downside.
Some additional studying:
Historical past of statistics on Wikipedia
A pleasant publish from Win-Vector: The differing views of statistics and machine studying
An attention-grabbing view by Brendan O’Connor: Statistics vs. Machine Studying, battle!
The publish Statistics vs Machine Studying: The 2 worlds appeared first on Datafloq.