
{kind=link}
In cooperative multi-agent reinforcement studying (MARL), resulting from its on-policy nature, coverage gradient (PG) strategies are usually believed to be much less pattern environment friendly than worth decomposition (VD) strategies, that are off-policy. Nonetheless, some latest empirical research show that with correct enter illustration and hyper-parameter tuning, multi-agent PG can obtain surprisingly robust efficiency in comparison with off-policy VD strategies.
Why may PG strategies work so effectively? On this publish, we are going to current concrete evaluation to indicate that in sure eventualities, e.g., environments with a extremely multi-modal reward panorama, VD could be problematic and result in undesired outcomes. In contrast, PG strategies with particular person insurance policies can converge to an optimum coverage in these instances. As well as, PG strategies with auto-regressive (AR) insurance policies can study multi-modal insurance policies.
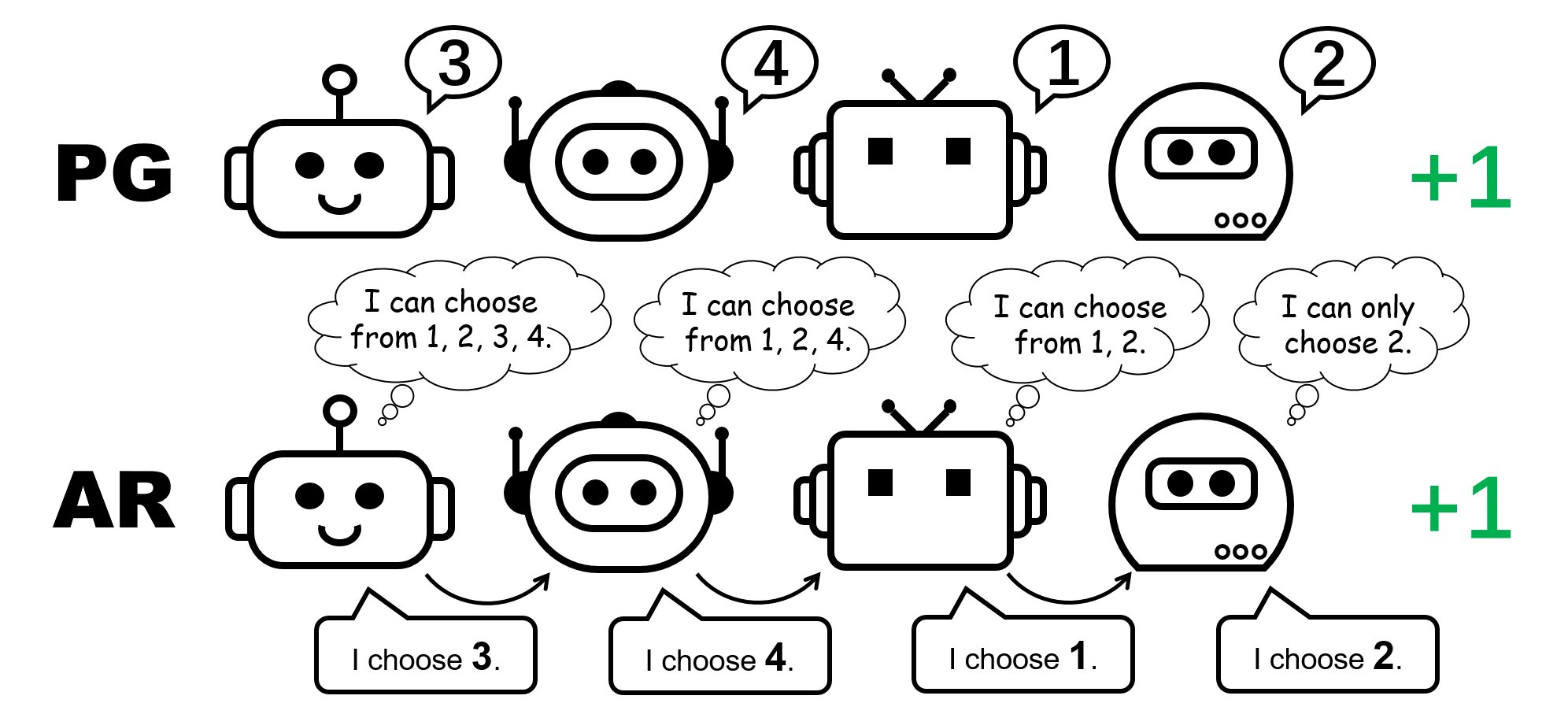
Determine 1: completely different coverage illustration for the 4-player permutation sport.
CTDE in Cooperative MARL: VD and PG strategies
Centralized coaching and decentralized execution (CTDE) is a well-liked framework in cooperative MARL. It leverages international info for simpler coaching whereas protecting the illustration of particular person insurance policies for testing. CTDE could be applied through worth decomposition (VD) or coverage gradient (PG), main to 2 various kinds of algorithms.
VD strategies study native Q networks and a mixing perform that mixes the native Q networks to a world Q perform. The blending perform is often enforced to fulfill the Particular person-World-Max (IGM) precept, which ensures the optimum joint motion could be computed by greedily selecting the optimum motion domestically for every agent.
In contrast, PG strategies immediately apply coverage gradient to study a person coverage and a centralized worth perform for every agent. The worth perform takes as its enter the worldwide state (e.g., MAPPO) or the concatenation of all of the native observations (e.g., MADDPG), for an correct international worth estimate.
The permutation sport: a easy counterexample the place VD fails
We begin our evaluation by contemplating a stateless cooperative sport, particularly the permutation sport. In an $N$-player permutation sport, every agent can output $N$ actions ${ 1,ldots, N }$. Brokers obtain $+1$ reward if their actions are mutually completely different, i.e., the joint motion is a permutation over $1, ldots, N$; in any other case, they obtain $0$ reward. Observe that there are $N!$ symmetric optimum methods on this sport.
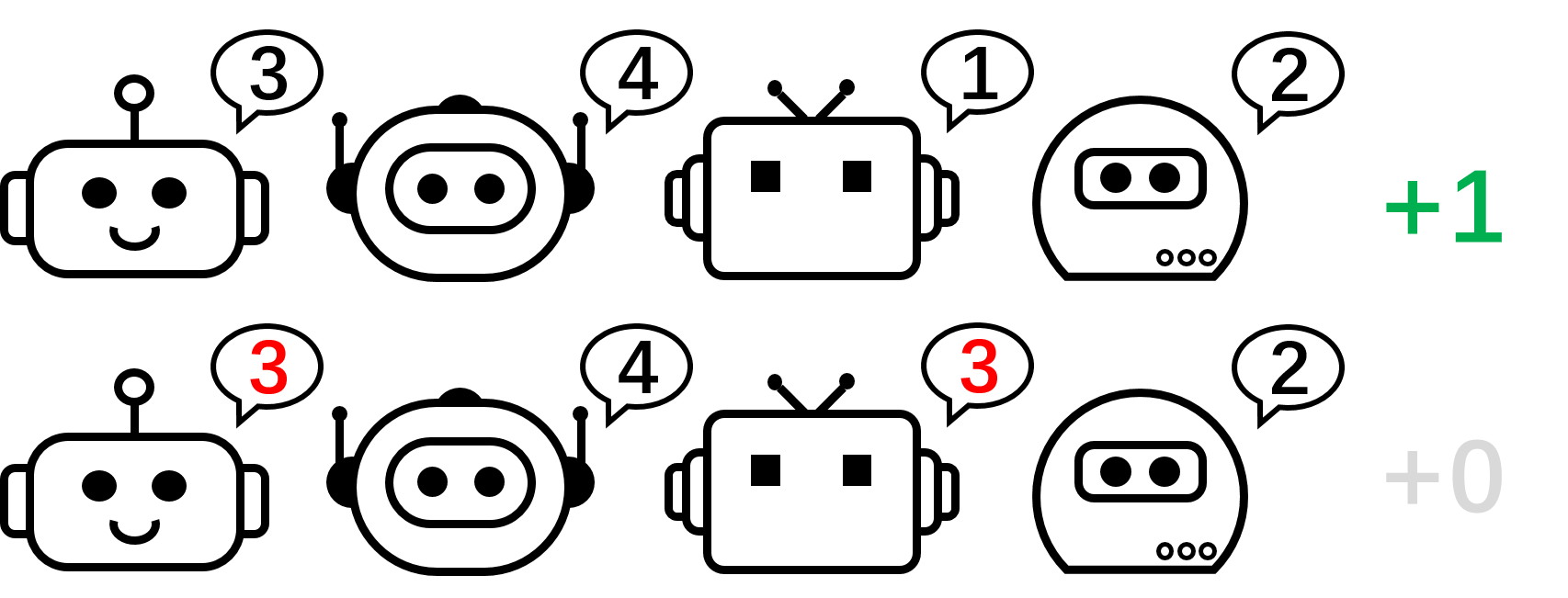
Determine 2: the 4-player permutation sport.
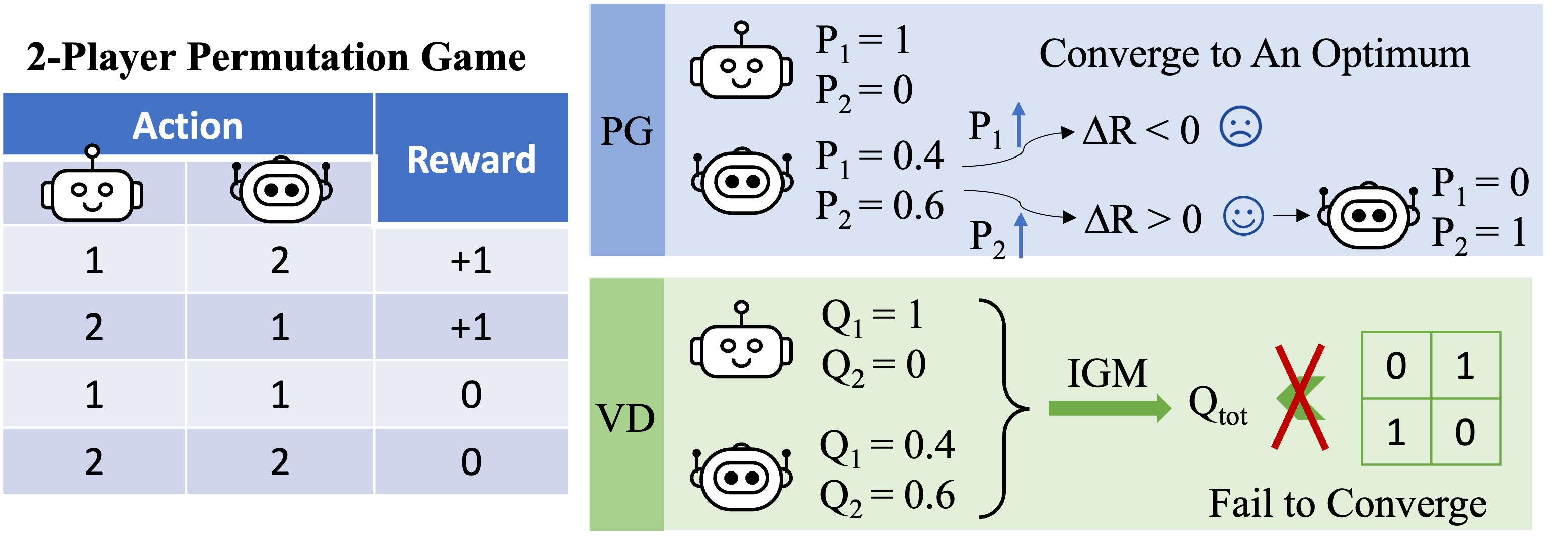
Determine 3: high-level instinct on why VD fails within the 2-player permutation sport.
Allow us to deal with the 2-player permutation sport now and apply VD to the sport. On this stateless setting, we use $Q_1$ and $Q_2$ to indicate the native Q-functions, and use $Q_textrm{tot}$ to indicate the worldwide Q-function. The IGM precept requires that
[argmax_{a^1,a^2}Q_textrm{tot}(a^1,a^2)={argmax_{a^1}Q_1(a^1),argmax_{a^2}Q_2(a^2)}.]
We show that VD can’t signify the payoff of the 2-player permutation sport by contradiction. If VD strategies have been capable of signify the payoff, we’d have
[Q_textrm{tot}(1, 2)=Q_textrm{tot}(2,1)=1quad text{and}quad Q_textrm{tot}(1, 1)=Q_textrm{tot}(2,2)=0.]
If both of those two brokers has completely different native Q values (e.g. $Q_1(1)> Q_1(2)$), we now have $argmax_{a^1}Q_1(a^1)=1$. Then in accordance with the IGM precept, any optimum joint motion
[(a^{1star},a^{2star})=argmax_{a^1,a^2}Q_textrm{tot}(a^1,a^2)={argmax_{a^1}Q_1(a^1),argmax_{a^2}Q_2(a^2)}]
satisfies $a^{1star}=1$ and $a^{1star}neq 2$, so the joint motion $(a^1,a^2)=(2,1)$ is sub-optimal, i.e., $Q_textrm{tot}(2,1)<1$.
In any other case, if $Q_1(1)=Q_1(2)$ and $Q_2(1)=Q_2(2)$, then
[Q_textrm{tot}(1, 1)=Q_textrm{tot}(2,2)=Q_textrm{tot}(1, 2)=Q_textrm{tot}(2,1).]
In consequence, worth decomposition can’t signify the payoff matrix of the 2-player permutation sport.
What about PG strategies? Particular person insurance policies can certainly signify an optimum coverage for the permutation sport. Furthermore, stochastic gradient descent can assure PG to converge to one among these optima underneath gentle assumptions. This means that, regardless that PG strategies are much less widespread in MARL in contrast with VD strategies, they are often preferable in sure instances which might be frequent in real-world functions, e.g., video games with a number of technique modalities.
We additionally comment that within the permutation sport, as a way to signify an optimum joint coverage, every agent should select distinct actions. Consequently, a profitable implementation of PG should be certain that the insurance policies are agent-specific. This may be achieved by utilizing both particular person insurance policies with unshared parameters (known as PG-Ind in our paper), or an agent-ID conditioned coverage (PG-ID).
PG outperforms current VD strategies on widespread MARL testbeds
Going past the easy illustrative instance of the permutation sport, we prolong our research to widespread and extra lifelike MARL benchmarks. Along with StarCraft Multi-Agent Problem (SMAC), the place the effectiveness of PG and agent-conditioned coverage enter has been verified, we present new leads to Google Analysis Soccer (GRF) and multi-player Hanabi Problem.
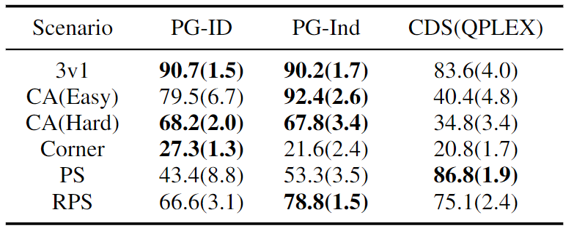
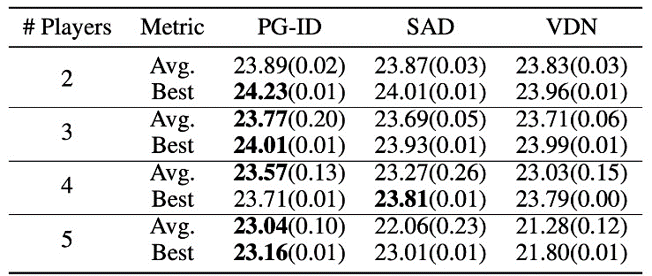
Determine 4: (left) successful charges of PG strategies on GRF; (proper) greatest and common analysis scores on Hanabi-Full.
In GRF, PG strategies outperform the state-of-the-art VD baseline (CDS) in 5 eventualities. Curiously, we additionally discover that particular person insurance policies (PG-Ind) with out parameter sharing obtain comparable, typically even larger successful charges, in comparison with agent-specific insurance policies (PG-ID) in all 5 eventualities. We consider PG-ID within the full-scale Hanabi sport with various numbers of gamers (2-5 gamers) and examine them to SAD, a robust off-policy Q-learning variant in Hanabi, and Worth Decomposition Networks (VDN). As demonstrated within the above desk, PG-ID is ready to produce outcomes corresponding to or higher than the perfect and common rewards achieved by SAD and VDN with various numbers of gamers utilizing the identical variety of surroundings steps.
Past larger rewards: studying multi-modal conduct through auto-regressive coverage modeling
In addition to studying larger rewards, we additionally research study multi-modal insurance policies in cooperative MARL. Let’s return to the permutation sport. Though we now have proved that PG can successfully study an optimum coverage, the technique mode that it lastly reaches can extremely rely on the coverage initialization. Thus, a pure query will probably be:
Can we study a single coverage that may cowl all of the optimum modes?
Within the decentralized PG formulation, the factorized illustration of a joint coverage can solely signify one explicit mode. Subsequently, we suggest an enhanced technique to parameterize the insurance policies for stronger expressiveness — the auto-regressive (AR) insurance policies.

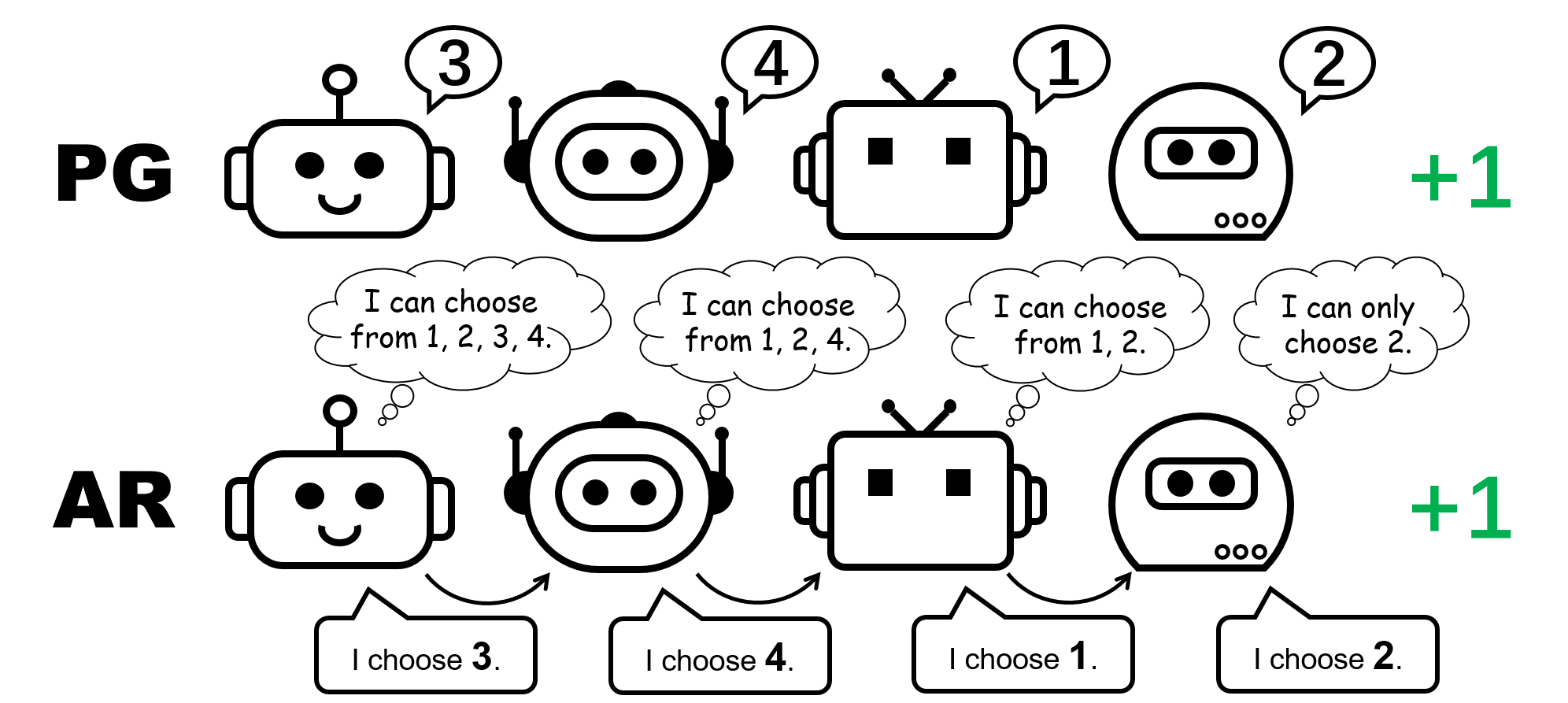
Determine 5: comparability between particular person insurance policies (PG) and auto-regressive insurance policies (AR) within the 4-player permutation sport.
Formally, we factorize the joint coverage of $n$ brokers into the type of
[pi(mathbf{a} mid mathbf{o}) approx prod_{i=1}^n pi_{theta^{i}} left( a^{i}mid o^{i},a^{1},ldots,a^{i-1} right),]
the place the motion produced by agent $i$ relies upon by itself statement $o_i$ and all of the actions from earlier brokers $1,dots,i-1$. The auto-regressive factorization can signify any joint coverage in a centralized MDP. The solely modification to every agent’s coverage is the enter dimension, which is barely enlarged by together with earlier actions; and the output dimension of every agent’s coverage stays unchanged.
With such a minimal parameterization overhead, AR coverage considerably improves the illustration energy of PG strategies. We comment that PG with AR coverage (PG-AR) can concurrently signify all optimum coverage modes within the permutation sport.

Determine: the heatmaps of actions for insurance policies discovered by PG-Ind (left) and PG-AR (center), and the heatmap for rewards (proper); whereas PG-Ind solely converge to a selected mode within the 4-player permutation sport, PG-AR efficiently discovers all of the optimum modes.
In additional complicated environments, together with SMAC and GRF, PG-AR can study fascinating emergent behaviors that require robust intra-agent coordination that will by no means be discovered by PG-Ind.
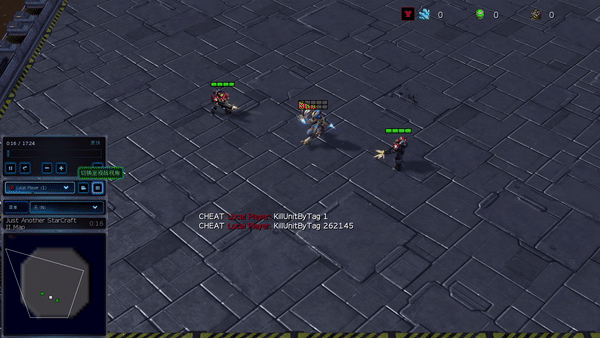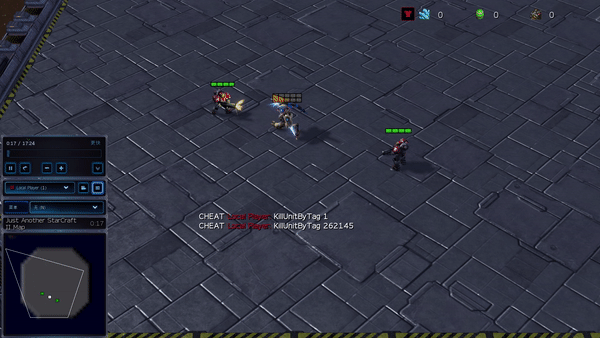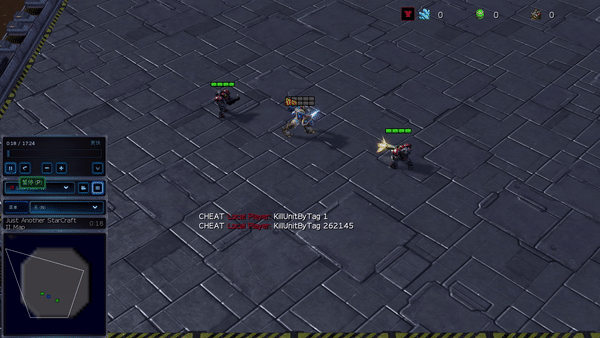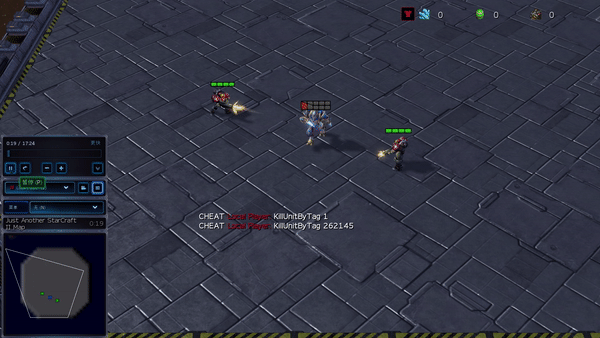
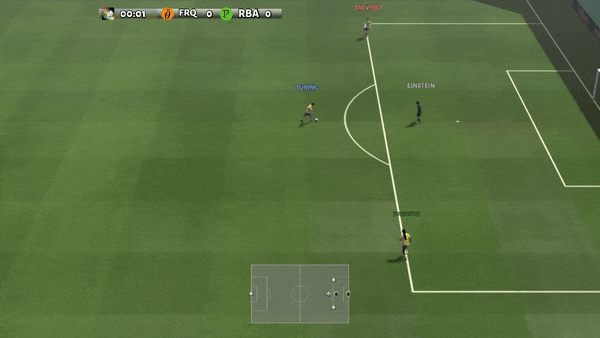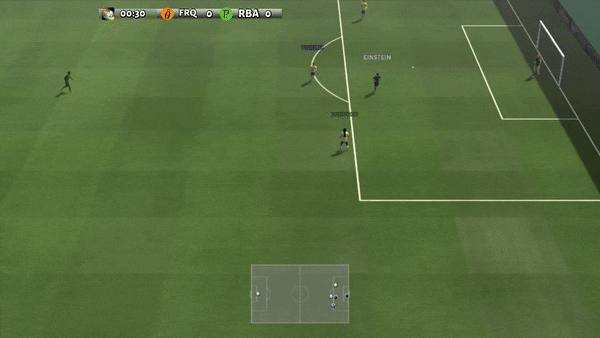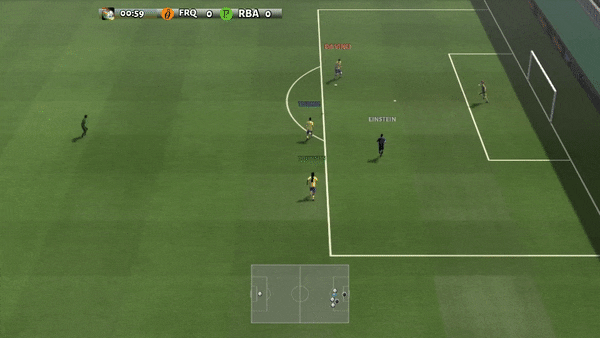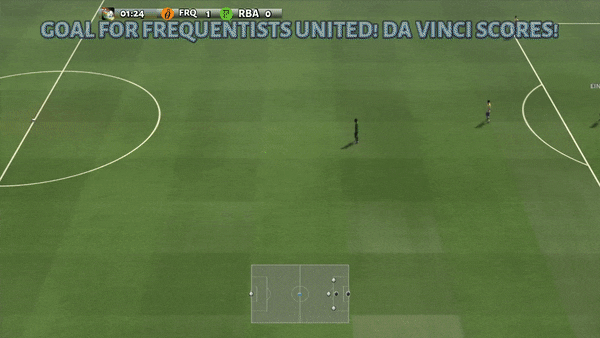
Determine 6: (left) emergent conduct induced by PG-AR in SMAC and GRF. On the 2m_vs_1z map of SMAC, the marines hold standing and assault alternately whereas guaranteeing there is just one attacking marine at every timestep; (proper) within the academy_3_vs_1_with_keeper situation of GRF, brokers study a “Tiki-Taka” model conduct: every participant retains passing the ball to their teammates.
Discussions and Takeaways
On this publish, we offer a concrete evaluation of VD and PG strategies in cooperative MARL. First, we reveal the limitation on the expressiveness of widespread VD strategies, exhibiting that they might not signify optimum insurance policies even in a easy permutation sport. In contrast, we present that PG strategies are provably extra expressive. We empirically confirm the expressiveness benefit of PG on widespread MARL testbeds, together with SMAC, GRF, and Hanabi Problem. We hope the insights from this work may gain advantage the group in the direction of extra normal and extra highly effective cooperative MARL algorithms sooner or later.
This publish relies on our paper: Revisiting Some Frequent Practices in Cooperative Multi-Agent Reinforcement Studying (paper, web site).